Управление данными
Развертывания ClickHouse для задач наблюдаемости неизбежно связаны с большими объемами данных, которыми необходимо управлять. ClickHouse предлагает ряд возможностей для управления такими данными.
Разделы
Разбиение на разделы (partitioning) в ClickHouse позволяет логически разделять данные на диске в соответствии со столбцом или SQL-выражением. При таком логическом разделении данные каждого раздела могут обрабатываться независимо, например, удаляться. Это позволяет пользователям перемещать разделы, а значит, и подмножества данных, между уровнями хранилища по времени, а также удалять устаревшие данные/эффективно удалять данные из кластера.
Разбиение на разделы задаётся для таблицы при её первичном определении с помощью предложения PARTITION BY. В этом предложении может содержаться SQL-выражение по любым столбцам, результат которого определяет, в какой раздел будет отправлена строка.
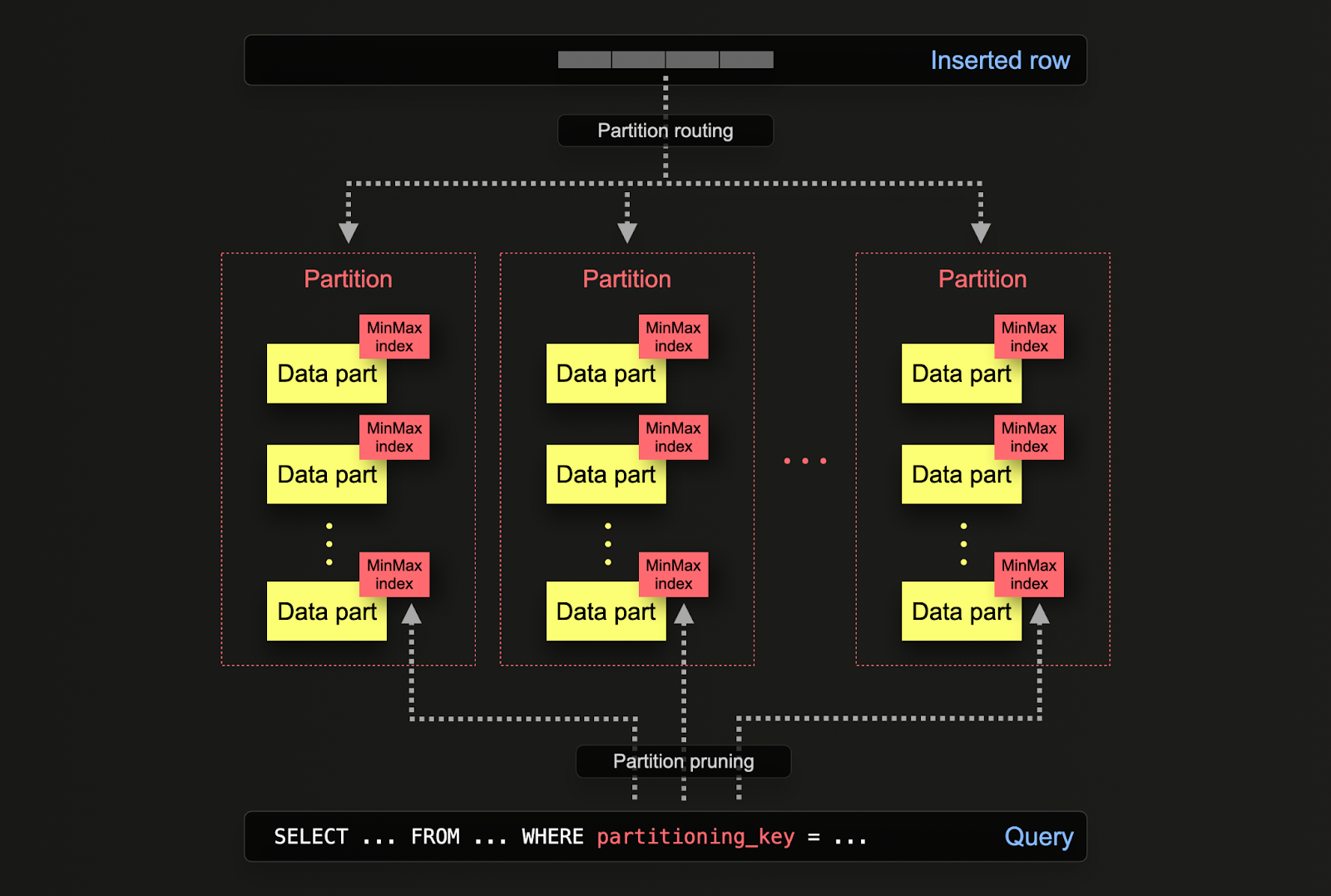
Части данных (data parts) логически связаны (через общий префикс имени каталога) с каждым разделом на диске и могут запрашиваться по отдельности. В примере ниже схема otel_logs по умолчанию делит данные на разделы по дням, используя выражение toDate(Timestamp). По мере вставки строк в ClickHouse это выражение вычисляется для каждой строки, и она направляется в соответствующий раздел, если он уже существует (если строка — первая для дня, соответствующий раздел будет создан).
Над разделами можно выполнять ряд операций, включая резервное копирование, манипуляции со столбцами, мутации, изменяющие/удаляющие данные на уровне строк, а также очистку индексов (например, вторичных индексов).
В качестве примера предположим, что наша таблица otel_logs разбита на разделы по дням. Если заполнить её набором данных со структурированными логами, в ней будет содержаться несколько дней данных:
Список текущих партиций можно получить с помощью простого запроса к системной таблице:
У нас может быть дополнительная таблица otel_logs_archive, которую мы используем для хранения более старых данных. Данные могут быть эффективно перемещены в эту таблицу по разделам (это всего лишь изменение метаданных).
В отличие от других методов, при которых пришлось бы использовать INSERT INTO SELECT и переписывать данные в новую целевую таблицу.
Перемещение партиций между таблицами требует выполнения нескольких условий; в частности, таблицы должны иметь одинаковую структуру, ключ партиционирования, первичный ключ и индексы/проекции. Подробные сведения о том, как указывать партиции в ALTER DDL, можно найти здесь.
Кроме того, данные можно эффективно удалять по партициям. Это значительно менее ресурсоёмко, чем альтернативные методы (мутации или облегчённые удаления) и должно рассматриваться как предпочтительный вариант.
Эта возможность используется механизмом TTL при включении настройки ttl_only_drop_parts=1. Дополнительную информацию см. в разделе Управление данными с помощью TTL.
Применения
Выше показано, как данные могут эффективно перемещаться и обрабатываться на уровне партиций. На практике пользователи чаще всего будут использовать операции с партициями в сценариях наблюдаемости в двух случаях:
- Многоуровневые архитектуры — перемещение данных между уровнями хранилища (см. Уровни хранилища), что позволяет строить архитектуры с горячим и холодным хранилищем.
- Эффективное удаление — когда данные достигают заданного TTL (см. Управление данными с помощью TTL)
Оба этих сценария мы подробно рассматриваем ниже.
Производительность запросов
Хотя разбиение на партиции может помочь с производительностью запросов, это в значительной степени зависит от характера доступа к данным. Если запросы обращаются только к нескольким партициям (в идеале — к одной), производительность потенциально может улучшиться. Это, как правило, полезно только в том случае, если ключ партиционирования не входит в первичный ключ и по нему выполняется фильтрация. Однако запросы, которым необходимо охватить множество партиций, могут работать хуже, чем без разбиения на партиции (так как потенциально может быть больше частей — parts). Преимущество обращения к одной партиции будет слабо выражено или вовсе отсутствовать, если ключ партиционирования уже является одним из первых столбцов в первичном ключе. Разбиение на партиции также может использоваться для оптимизации запросов GROUP BY, если значения в каждой партиции уникальны. Однако в общем случае пользователям следует в первую очередь оптимизировать первичный ключ и рассматривать партиционирование как технику оптимизации запросов только в исключительных ситуациях, когда характер запросов предполагает доступ к конкретному предсказуемому подмножеству данных, например, при партиционировании по дням, когда большинство запросов приходится на последний день. Пример такого поведения приведён здесь.
Управление данными с помощью TTL (Time-to-live)
Time-to-Live (TTL) — это ключевая функция в решениях для наблюдаемости на базе ClickHouse, обеспечивающая эффективное хранение и управление данными, особенно в условиях постоянной генерации огромных объёмов данных. Реализация TTL в ClickHouse обеспечивает автоматическое истечение срока действия и удаление устаревших данных, гарантируя оптимальное использование хранилища и поддержание производительности без ручного вмешательства. Эта возможность имеет ключевое значение для того, чтобы база данных оставалась компактной, снижались затраты на хранение и запросы оставались быстрыми и эффективными за счёт работы преимущественно с наиболее актуальными и свежими данными. Кроме того, TTL помогает соблюдать политики хранения данных путём систематического управления жизненным циклом данных, что в целом повышает устойчивость и масштабируемость решения для наблюдаемости.
TTL в ClickHouse может задаваться как на уровне таблицы, так и на уровне столбца.
TTL на уровне таблицы
Схема по умолчанию как для логов, так и для трейсов включает TTL для удаления данных по истечении заданного периода. Он задаётся в экспортёре ClickHouse в ключе ttl, например:
Этот синтаксис в настоящее время поддерживает синтаксис длительностей Golang. Мы рекомендуем использовать суффикс h и убедиться, что это соответствует периоду партиционирования. Например, если вы партиционируете по дням, убедитесь, что значение кратно суткам, например 24h, 48h, 72h. Это автоматически гарантирует, что к таблице будет добавлено предложение TTL, например при ttl: 96h.
По умолчанию данные с истёкшим TTL удаляются, когда ClickHouse объединяет части данных. Когда ClickHouse обнаруживает, что срок действия данных истёк, он выполняет внеплановое слияние.
TTLs применяются не сразу, а по расписанию, как отмечено выше. Настройка таблицы MergeTree merge_with_ttl_timeout задаёт минимальную задержку в секундах перед повторным выполнением слияния с TTL на удаление. Значение по умолчанию — 14400 секунд (4 часа). Но это только минимальная задержка, может пройти больше времени, прежде чем будет инициировано слияние по TTL. Если значение слишком низкое, будет выполняться множество внеплановых слияний, которые могут потреблять много ресурсов. Принудительно применить TTL можно с помощью команды ALTER TABLE my_table MATERIALIZE TTL.
**Важно: мы рекомендуем использовать настройку ttl_only_drop_parts=1 ** (применяется в схеме по умолчанию). Когда эта настройка включена, ClickHouse удаляет целую часть, если все строки в ней имеют истёкший TTL. Удаление целых частей вместо частичной очистки строк с истёкшим TTL (достигаемой с помощью ресурсоёмких мутаций при ttl_only_drop_parts=0) позволяет использовать меньшие значения merge_with_ttl_timeout и снижать влияние на производительность системы. Если данные разбиваются на партиции по той же единице, по которой у вас настроено истечение TTL, например по дням, части естественным образом будут содержать данные только из заданного интервала. Это гарантирует, что ttl_only_drop_parts=1 может эффективно применяться.
TTL на уровне столбца
В приведённом выше примере срок жизни задаётся на уровне таблицы. Пользователи также могут задавать срок жизни данных на уровне столбца. По мере устаревания данных это можно использовать для удаления столбцов, ценность которых для расследований не оправдывает ресурсных затрат на их хранение. Например, мы рекомендуем сохранять столбец Body на случай, если будут добавлены новые динамические метаданные, которые не были извлечены во время вставки, например новая метка Kubernetes. После некоторого периода, например одного месяца, может стать очевидно, что эти дополнительные метаданные не полезны — и, следовательно, нет смысла продолжать хранить столбец Body.
Ниже показано, как можно удалить столбец Body через 30 дней.
Указание TTL на уровне столбца требует от пользователей самостоятельного определения собственной схемы. Это нельзя настроить в OTel collector.
Повторное сжатие данных
Хотя для наборов данных наблюдаемости мы обычно рекомендуем ZSTD(1), пользователи могут экспериментировать с другими алгоритмами сжатия или более высокими уровнями сжатия, например ZSTD(3). Помимо возможности указать это при создании схемы, сжатие можно настроить так, чтобы оно изменялось по истечении заданного периода времени. Это может быть целесообразно, если кодек или алгоритм сжатия обеспечивает более высокую степень сжатия, но ухудшает производительность запросов. Такой компромисс может быть приемлем для более старых данных, к которым обращаются реже, но не для свежих данных, которые используются чаще, в том числе при расследованиях инцидентов.
Пример этого показан ниже: вместо удаления данных мы сжимаем их с помощью ZSTD(3) по прошествии 4 дней.
Мы рекомендуем всегда оценивать влияние различных уровней и алгоритмов сжатия как на производительность вставки, так и на производительность выполнения запросов. Например, дельта‑кодеки могут быть полезны для сжатия временных меток. Однако если они являются частью первичного ключа, производительность фильтрации может снизиться.
Дополнительные сведения и примеры по настройке TTL см. здесь. Примеры добавления и изменения TTL для таблиц и столбцов приведены здесь. О том, как TTL позволяет реализовывать иерархии хранилища, такие как архитектуры hot‑warm, см. раздел Уровни хранилища.
Уровни хранения
В ClickHouse пользователи могут создавать уровни хранения на разных дисках, например «горячие»/недавние данные на SSD и более старые данные в S3. Такая архитектура позволяет использовать более дешевое хранилище для старых данных, для которых допустимы более высокие SLA по запросам из‑за их редкого использования при расследованиях.
ClickHouse Cloud использует единственную копию данных, хранящуюся в S3, с кешами узлов на SSD. Таким образом, уровни хранения в ClickHouse Cloud не требуются.
Создание уровней хранения требует от пользователей сначала создать диски, которые затем используются для формирования политик хранения с томами, указываемыми при создании таблиц. Данные могут автоматически переноситься между дисками на основе степени заполнения, размеров частей и приоритетов томов. Дополнительную информацию можно найти здесь.
Хотя данные можно вручную перемещать между дисками с помощью команды ALTER TABLE MOVE PARTITION, перемещение данных между томами также может управляться с использованием TTL. Полный пример можно найти здесь.
Управление изменениями схемы
Схемы логов и трейсов неизбежно будут меняться на протяжении жизненного цикла системы, например по мере того, как пользователи начинают мониторить новые системы с другими метаданными или метками подов. Благодаря генерации данных по схеме OTel и сохранению исходных данных событий в структурированном формате схемы ClickHouse будут устойчивы к этим изменениям. Однако по мере появления новых метаданных и изменения шаблонов выполнения запросов пользователи будут стремиться обновлять схемы, чтобы отражать эти изменения.
Чтобы избежать простоя во время изменений схемы, у пользователей есть несколько вариантов, которые мы рассмотрим ниже.
Использование значений по умолчанию
Столбцы можно добавлять в схему, используя значения DEFAULT. Указанное значение по умолчанию будет использоваться, если оно не задано при выполнении INSERT.
Изменения схемы можно внести до изменения любой логики трансформации материализованного представления или конфигурации OTel collector, которые приводят к отправке данных в эти новые столбцы.
После изменения схемы пользователи могут перенастроить экземпляры OTel collector. Предполагая, что пользователи используют рекомендуемый процесс, описанный в разделе «Извлечение структуры с помощью SQL», когда OTel collectors отправляют данные в табличный движок Null, а материализованное представление отвечает за извлечение целевой схемы и отправку результатов в целевую таблицу для хранения, представление можно изменить, используя синтаксис ALTER TABLE ... MODIFY QUERY. Предположим, у нас есть целевая таблица ниже с соответствующим материализованным представлением (аналогичным используемому в разделе «Извлечение структуры с помощью SQL»), которое извлекает целевую схему из структурированных логов OTel:
Предположим, мы хотим извлечь новый столбец Size из LogAttributes. Мы можем добавить его в схему таблицы с помощью оператора ALTER TABLE, указав значение по умолчанию:
В приведённом выше примере мы задаём значение по умолчанию через ключ size в LogAttributes (это будет 0, если этого ключа не существует). Это означает, что запросы, обращающиеся к этому столбцу для строк, в которых значение не было записано, должны будут обращаться к Map и, соответственно, выполняться медленнее. Мы также могли бы просто указать это как константу, например 0, уменьшая стоимость последующих запросов к строкам, где значение отсутствует. Запрос к этой таблице показывает, что значение заполняется, как и ожидается, из Map:
Чтобы обеспечить запись этого значения для всех будущих данных, мы можем изменить наше материализованное представление с помощью синтаксиса ALTER TABLE, как показано ниже:
Для последующих строк значение в столбце Size будет заполняться в момент вставки.
Создание новых таблиц
В качестве альтернативы описанному выше процессу пользователи могут просто создать новую целевую таблицу с новой схемой. Любые материализованные представления затем можно изменить так, чтобы они использовали эту новую таблицу, с помощью вышеупомянутой команды ALTER TABLE MODIFY QUERY. При таком подходе пользователи могут версионировать свои таблицы, например otel_logs_v3.
Этот подход оставляет пользователям несколько таблиц, по которым нужно выполнять запросы. Чтобы выполнять запросы по нескольким таблицам, пользователи могут использовать функцию merge, которая принимает шаблоны с подстановочными символами для имени таблицы. Ниже мы демонстрируем это, выполняя запрос к версиям v2 и v3 таблицы otel_logs:
Если пользователи хотят избежать использования функции merge и предоставить конечным пользователям таблицу, объединяющую несколько таблиц, можно использовать движок таблиц Merge. Ниже показан пример:
Это можно обновлять при добавлении новой таблицы с использованием синтаксиса EXCHANGE для таблиц. Например, чтобы добавить таблицу версии v4, можно создать новую таблицу и атомарно подменить ею предыдущую версию.
