ClickHouse Kafka Connect Sink
Если вам нужна помощь, создайте обращение (issue) в репозитории или задайте вопрос в публичном Slack ClickHouse.
ClickHouse Kafka Connect Sink — это коннектор Kafka, который доставляет данные из топика Kafka в таблицу ClickHouse.
Лицензия
Kafka Connector Sink распространяется под лицензией Apache 2.0
Требования к среде
В среде должен быть установлен фреймворк Kafka Connect версии 2.7 или новее.
Матрица совместимости версий
| ClickHouse Kafka Connect version | ClickHouse version | Kafka Connect | Confluent platform |
|---|---|---|---|
| 1.0.0 | > 23.3 | > 2.7 | > 6.1 |
Основные возможности
- Поставляется с готовой семантикой exactly-once. Она основана на новой функции ядра ClickHouse под названием KeeperMap (используется коннектором как хранилище состояния) и позволяет использовать минималистичную архитектуру.
- Поддержка сторонних хранилищ состояния: по умолчанию используется In-memory, но может использовать KeeperMap (поддержка Redis будет добавлена позже).
- Глубокая интеграция: разрабатывается, сопровождается и поддерживается ClickHouse.
- Непрерывно тестируется с ClickHouse Cloud.
- Вставка данных с объявленной схемой и без неё.
- Поддержка всех типов данных ClickHouse.
Инструкции по установке
Сбор параметров подключения
Чтобы подключиться к ClickHouse по HTTP(S), вам потребуется следующая информация:
| Параметр(ы) | Описание |
|---|---|
HOST и PORT | Обычно используется порт 8443 при использовании TLS или 8123 при отсутствии TLS. |
DATABASE NAME | По умолчанию существует база данных default; используйте имя базы данных, к которой вы хотите подключиться. |
USERNAME и PASSWORD | По умолчанию имя пользователя — default. Используйте имя пользователя, соответствующее вашему сценарию. |
Сведения о вашем сервисе ClickHouse Cloud доступны в консоли ClickHouse Cloud. Выберите сервис и нажмите Connect:
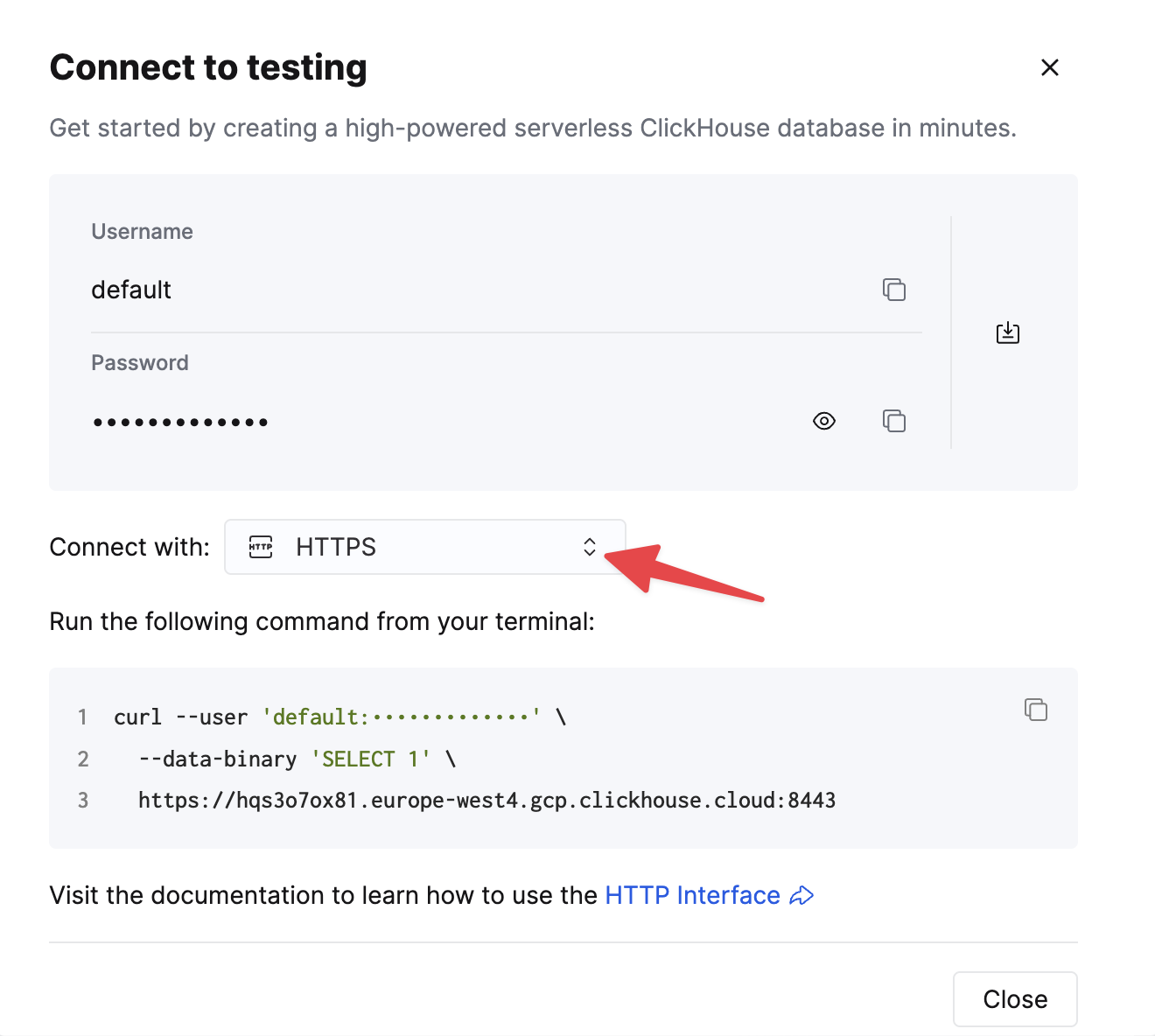
Выберите HTTPS. Параметры подключения отображаются в примере команды curl.
Если вы используете самостоятельное (self-managed) развертывание ClickHouse, параметры подключения задаются администратором ClickHouse.
Общие инструкции по установке
Коннектор распространяется как единый JAR-файл, содержащий все классы, необходимые для запуска плагина.
Чтобы установить плагин, выполните следующие шаги:
- Скачайте ZIP-архив, содержащий JAR-файл коннектора, со страницы Releases репозитория ClickHouse Kafka Connect Sink.
- Извлеките содержимое ZIP-файла и скопируйте его в нужное место.
- Добавьте путь к директории с плагином в параметр конфигурации plugin.path в вашем файле свойств Connect, чтобы Confluent Platform могла найти плагин.
- Укажите имя топика, имя хоста экземпляра ClickHouse и пароль в конфигурации.
- Перезапустите Confluent Platform.
- Если вы используете Confluent Platform, войдите в Confluent Control Center, чтобы убедиться, что ClickHouse Sink доступен в списке коннекторов.
Параметры конфигурации
Чтобы подключить ClickHouse Sink к серверу ClickHouse, необходимо указать:
- параметры подключения: hostname (обязательно) и port (необязательно)
- учетные данные пользователя: password (обязательно) и username (необязательно)
- класс коннектора:
com.clickhouse.kafka.connect.ClickHouseSinkConnector(обязательно) - topics или topics.regex: Kafka topics для опроса — имена topics должны совпадать с именами таблиц (обязательно)
- конвертеры ключей и значений (key и value converters): задаются в зависимости от типа данных в ваших topics. Обязательны, если еще не определены в конфигурации worker.
Полная таблица параметров конфигурации:
| Property Name | Description | Default Value |
|---|---|---|
hostname (Required) | Имя хоста или IP-адрес сервера | N/A |
port | Порт ClickHouse — по умолчанию 8443 (для HTTPS в облаке), но для HTTP (значение по умолчанию для self-hosted) должен быть 8123 | 8443 |
ssl | Включить SSL-подключение к ClickHouse | true |
jdbcConnectionProperties | Свойства подключения при подключении к ClickHouse. Должны начинаться с ? и объединяться с помощью & между param=value | "" |
username | Имя пользователя базы данных ClickHouse | default |
password (Required) | Пароль базы данных ClickHouse | N/A |
database | Имя базы данных ClickHouse | default |
connector.class (Required) | Класс коннектора (явно задаётся и остаётся значением по умолчанию) | "com.clickhouse.kafka.connect.ClickHouseSinkConnector" |
tasks.max | Количество задач коннектора | "1" |
errors.retry.timeout | Таймаут повторных попыток ClickHouse JDBC | "60" |
exactlyOnce | Включение режима exactly-once | "false" |
topics (Required) | Топики Kafka для опроса — имена топиков должны совпадать с именами таблиц | "" |
key.converter (Required* - See Description) | Устанавливается в соответствии с типами ваших ключей. Обязательно здесь, если вы передаёте ключи (и параметр не задан в конфигурации worker). | "org.apache.kafka.connect.storage.StringConverter" |
value.converter (Required* - See Description) | Устанавливается на основе типа данных в вашем топике. Поддерживаются форматы: JSON, String, Avro или Protobuf. Обязательно здесь, если параметр не задан в конфигурации worker. | "org.apache.kafka.connect.json.JsonConverter" |
value.converter.schemas.enable | Поддержка схем для конвертера значений коннектора | "false" |
errors.tolerance | Допустимый уровень ошибок коннектора. Поддерживаются значения: none, all | "none" |
errors.deadletterqueue.topic.name | Если задан (при errors.tolerance=all), для неудачных пакетов будет использоваться DLQ (см. Troubleshooting) | "" |
errors.deadletterqueue.context.headers.enable | Добавляет дополнительные заголовки для DLQ | "" |
clickhouseSettings | Разделённый запятыми список настроек ClickHouse (например, «insert_quorum=2, и т. д.») | "" |
topic2TableMap | Разделённый запятыми список, который сопоставляет имена топиков именам таблиц (например, «topic1=table1, topic2=table2, и т. д.») | "" |
tableRefreshInterval | Время (в секундах) для обновления кэша определения таблицы | 0 |
keeperOnCluster | Позволяет настраивать параметр ON CLUSTER для self-hosted экземпляров (например, ON CLUSTER clusterNameInConfigFileDefinition) для таблицы connect_state в режиме exactly-once (см. Distributed DDL Queries | "" |
bypassRowBinary | Позволяет отключить использование RowBinary и RowBinaryWithDefaults для данных на основе схемы (Avro, Protobuf и т. д.) — следует использовать только тогда, когда в данных будут отсутствующие столбцы и Nullable/Default неприемлемы | "false" |
dateTimeFormats | Форматы даты и времени для парсинга полей схемы типа DateTime64, разделённые с помощью ; (например, someDateField=yyyy-MM-dd HH:mm:ss.SSSSSSSSS;someOtherDateField=yyyy-MM-dd HH:mm:ss). | "" |
tolerateStateMismatch | Позволяет коннектору отбрасывать записи «раньше» текущего смещения, сохранённого AFTER_PROCESSING (например, если отправлено смещение 5, а последнее зафиксированное смещение — 250) | "false" |
ignorePartitionsWhenBatching | Игнорирует раздел (partition) при сборе сообщений для вставки (но только если exactlyOnce имеет значение false). Примечание по производительности: чем больше задач коннектора, тем меньше разделов Kafka назначается на задачу — это может приводить к убывающей отдаче. | "false" |
Целевые таблицы
ClickHouse Connect Sink читает сообщения из топиков Kafka и записывает их в соответствующие таблицы. ClickHouse Connect Sink записывает данные в уже существующие таблицы. Пожалуйста, убедитесь, что целевая таблица с подходящей схемой создана в ClickHouse до начала вставки данных в неё.
Для каждого топика требуется отдельная целевая таблица в ClickHouse. Имя целевой таблицы должно совпадать с именем исходного топика.
Предварительная обработка
Если вам нужно трансформировать исходящие сообщения перед тем, как они будут отправлены в ClickHouse Kafka Connect Sink, используйте Kafka Connect Transformations.
Поддерживаемые типы данных
При объявленной схеме:
| Тип Kafka Connect | Тип ClickHouse | Поддерживается | Примитивный |
|---|---|---|---|
| STRING | String | ✅ | Да |
| STRING | JSON. См. ниже (1) | ✅ | Да |
| INT8 | Int8 | ✅ | Да |
| INT16 | Int16 | ✅ | Да |
| INT32 | Int32 | ✅ | Да |
| INT64 | Int64 | ✅ | Да |
| FLOAT32 | Float32 | ✅ | Да |
| FLOAT64 | Float64 | ✅ | Да |
| BOOLEAN | Boolean | ✅ | Да |
| ARRAY | Array(T) | ✅ | Нет |
| MAP | Map(Primitive, T) | ✅ | Нет |
| STRUCT | Variant(T1, T2, ...) | ✅ | Нет |
| STRUCT | Tuple(a T1, b T2, ...) | ✅ | Нет |
| STRUCT | Nested(a T1, b T2, ...) | ✅ | Нет |
| STRUCT | JSON. См. ниже (1), (2) | ✅ | Нет |
| BYTES | String | ✅ | Нет |
| org.apache.kafka.connect.data.Time | Int64 / DateTime64 | ✅ | Нет |
| org.apache.kafka.connect.data.Timestamp | Int32 / Date32 | ✅ | Нет |
| org.apache.kafka.connect.data.Decimal | Decimal | ✅ | Нет |
-
(1) JSON поддерживается только когда в настройках ClickHouse установлено значение
input_format_binary_read_json_as_string=1. Это работает только для семейства форматов RowBinary, и настройка влияет на все столбцы в запросеINSERT, поэтому все они должны быть строковыми. В этом случае коннектор будет конвертировать STRUCT в JSON-строку. -
(2) Когда STRUCT содержит union-поля, такие как
oneof, конвертер должен быть настроен так, чтобы НЕ добавлять префикс/суффикс к именам полей. Для этого есть настройкаgenerate.index.for.unions=falseвProtobufConverter.
Без объявленной схемы:
Запись конвертируется в JSON и отправляется в ClickHouse как значение в формате JSONEachRow.
Рецепты конфигурации
Ниже приведено несколько типовых рецептов конфигурации, которые помогут вам быстро начать работу.
Базовая конфигурация
Самая простая конфигурация для начала работы — предполагается, что вы запускаете Kafka Connect в распределённом режиме и у вас работает сервер ClickHouse на localhost:8443 с включённым SSL, а данные представлены в виде JSON без схемы.
Базовая конфигурация с несколькими топиками
Коннектор может потреблять данные из нескольких топиков.
Базовая конфигурация с DLQ
Использование с различными форматами данных
Поддержка схем Avro
Поддержка схемы Protobuf
Обратите внимание: если вы столкнётесь с проблемами, связанными с отсутствующими классами, учтите, что не во всех средах доступен protobuf-конвертер, и вам может потребоваться альтернативная сборка jar-файла, в которую включены зависимости.
Поддержка схем JSON
Поддержка строк
Коннектор поддерживает String Converter для различных форматов ClickHouse: JSON, CSV и TSV.
Логирование
Логирование автоматически обеспечивается платформой Kafka Connect. Место назначения и формат логов можно настроить в файле конфигурации Kafka Connect.
При использовании Confluent Platform логи можно просматривать, запустив CLI-команду:
Для получения дополнительных сведений ознакомьтесь с официальным руководством.
Мониторинг
ClickHouse Kafka Connect экспортирует метрики времени выполнения через Java Management Extensions (JMX). JMX по умолчанию включён в коннекторе Kafka.
Метрики, специфичные для ClickHouse
Коннектор предоставляет пользовательские метрики под следующим именем MBean:
| Metric Name | Type | Description |
|---|---|---|
receivedRecords | long | Общее количество полученных записей. |
recordProcessingTime | long | Общее время в наносекундах, затраченное на группировку и преобразование записей в единую структуру. |
taskProcessingTime | long | Общее время в наносекундах, затраченное на обработку и вставку данных в ClickHouse. |
Метрики Kafka Producer/Consumer
Коннектор экспортирует стандартные метрики продюсера и консюмера Kafka, которые дают представление о потоке данных, пропускной способности и производительности.
Метрики на уровне топика:
records-sent-total: Общее количество записей, отправленных в топикbytes-sent-total: Общий объем данных (в байтах), отправленных в топикrecord-send-rate: Средняя скорость отправки записей в секундуbyte-rate: Средняя скорость отправки данных в байтах в секундуcompression-rate: Достигнутый коэффициент сжатия
Метрики на уровне партиций:
records-sent-total: Общее количество записей, отправленных в партициюbytes-sent-total: Общее количество байт, отправленных в партициюrecords-lag: Текущее отставание в партицииrecords-lead: Текущее опережение в партицииreplica-fetch-lag: Информация об отставании реплик
Метрики подключений на уровне узлов:
connection-creation-total: Общее количество подключений, установленных к узлу Kafkaconnection-close-total: Общее количество закрытых подключенийrequest-total: Общее количество запросов, отправленных на узелresponse-total: Общее количество ответов, полученных от узлаrequest-rate: Средняя частота запросов в секундуresponse-rate: Средняя частота ответов в секунду
Эти метрики помогают отслеживать:
- Пропускную способность: Скорости ингестии данных
- Отставание: Узкие места и задержки обработки
- Сжатие: Эффективность сжатия данных
- Состояние подключений: Сетевую доступность и стабильность
Метрики фреймворка Kafka Connect
Коннектор интегрируется с фреймворком Kafka Connect и предоставляет метрики для жизненного цикла задач и отслеживания ошибок.
Метрики статуса задач:
task-count: Общее количество задач в коннектореrunning-task-count: Количество задач, которые сейчас выполняютсяpaused-task-count: Количество задач, которые сейчас на паузеfailed-task-count: Количество задач, завершившихся с ошибкойdestroyed-task-count: Количество уничтоженных задачunassigned-task-count: Количество неназначенных задач
Возможные значения статуса задач: running, paused, failed, destroyed, unassigned
Метрики ошибок:
deadletterqueue-produce-failures: Количество неудачных записей в DLQdeadletterqueue-produce-requests: Общее количество попыток записи в DLQlast-error-timestamp: Временная метка последней ошибкиrecords-skip-total: Общее количество записей, пропущенных из‑за ошибокrecords-retry-total: Общее количество записей, которые были повторно обработаныerrors-total: Общее количество возникших ошибок
Метрики производительности:
offset-commit-failures: Количество неудачных фиксаций смещенийoffset-commit-avg-time-ms: Среднее время фиксации смещенийoffset-commit-max-time-ms: Максимальное время фиксации смещенийput-batch-avg-time-ms: Среднее время обработки батчаput-batch-max-time-ms: Максимальное время обработки батчаsource-record-poll-total: Общее количество опрошенных записей
Рекомендации по мониторингу
- Отслеживайте отставание потребителя: Мониторьте
records-lagпо партициям для выявления узких мест обработки - Отслеживайте уровень ошибок: Наблюдайте за
errors-totalиrecords-skip-total, чтобы выявлять проблемы с качеством данных - Контролируйте состояние задач: Отслеживайте метрики статуса задач, чтобы убедиться, что задачи выполняются корректно
- Измеряйте пропускную способность: Используйте
records-send-rateиbyte-rateдля отслеживания производительности ингестии - Отслеживайте состояние подключений: Проверяйте метрики подключений на уровне узлов для выявления сетевых проблем
- Отслеживайте эффективность сжатия: Используйте
compression-rateдля оптимизации передачи данных
Подробные определения JMX-метрик и информацию об интеграции с Prometheus см. в конфигурационном файле jmx-export-connector.yml.
Ограничения
- Удаление записей не поддерживается.
- Размер батча наследуется из свойств Kafka Consumer.
- При использовании KeeperMap для exactly-once и изменении или перемотке смещения необходимо удалить содержимое KeeperMap для соответствующего топика. (См. руководство по устранению неполадок ниже для получения дополнительной информации)
Настройка производительности и оптимизация пропускной способности
В этом разделе рассматриваются стратегии настройки производительности для ClickHouse Kafka Connect Sink. Настройка производительности важна при работе с сценариями высокой пропускной способности или когда необходимо оптимизировать использование ресурсов и минимизировать отставание.
Когда требуется настройка производительности?
Настройка производительности, как правило, требуется в следующих сценариях:
- Высоконагруженные сценарии: При обработке миллионов событий в секунду из топиков Kafka
- Отставание потребителя: Когда коннектор не успевает за скоростью генерации данных, что приводит к росту отставания
- Ограниченные ресурсы: Когда нужно оптимизировать использование CPU, памяти или сети
- Несколько топиков: При одновременном потреблении из нескольких высоконагруженных топиков
- Малый размер сообщений: При работе с большим количеством маленьких сообщений, которые выигрывают от серверного батчинга
Настройка производительности обычно НЕ требуется, когда:
- Обрабатываются небольшие или умеренные объёмы (< 10 000 сообщений/секунду)
- Отставание потребителя стабильно и приемлемо для вашего сценария
- Стандартные настройки коннектора уже удовлетворяют требованиям по пропускной способности
- Ваш кластер ClickHouse без труда справляется с входящей нагрузкой
Понимание потока данных
Перед началом настройки важно понять, как данные проходят через коннектор:
- Kafka Connect Framework в фоновом режиме читает сообщения из топиков Kafka
- Коннектор опрашивает сообщения из внутреннего буфера фреймворка
- Коннектор формирует пакеты сообщений на основе размера выборки (poll size)
- ClickHouse получает пакетную вставку по HTTP/S
- ClickHouse обрабатывает вставку (синхронно или асинхронно)
Производительность можно оптимизировать на каждом из этих этапов.
Настройка размера пакета в Kafka Connect
Первый уровень оптимизации — управление объёмом данных, который коннектор получает за один пакет из Kafka.
Параметры выборки (Fetch)
Kafka Connect (фреймворк) выбирает сообщения из топиков Kafka в фоновом режиме, независимо от коннектора:
fetch.min.bytes: Минимальный объём данных, прежде чем фреймворк передаст данные коннектору (по умолчанию: 1 байт)fetch.max.bytes: Максимальный объём данных для выборки за один запрос (по умолчанию: 52428800 / 50 MB)fetch.max.wait.ms: Максимальное время ожидания перед возвратом данных, еслиfetch.min.bytesне достигнут (по умолчанию: 500 мс)
Параметры опроса (Poll)
Коннектор опрашивает сообщения из буфера фреймворка:
max.poll.records: Максимальное количество записей, возвращаемых за один опрос (по умолчанию: 500)max.partition.fetch.bytes: Максимальный объём данных на партицию (по умолчанию: 1048576 / 1 MB)
Рекомендуемые настройки для высокой пропускной способности
Для оптимальной работы с ClickHouse ориентируйтесь на более крупные пакеты:
Увеличить размер выборки раздела до 5 МБ
consumer.max.partition.fetch.bytes=5242880
Необязательно: увеличьте минимальный размер получаемых данных, чтобы дожидаться большего объёма (1 МБ)
consumer.fetch.min.bytes=1048576
Необязательно: уменьшите время ожидания, если задержка критична
consumer.fetch.max.wait.ms=300
Ключевые настройки:
async_insert=1: Включить асинхронные вставкиwait_for_async_insert=1(рекомендуется): Коннектор ждёт, пока данные не будут сброшены в хранилище ClickHouse, прежде чем подтвердить приём данных. Обеспечивает гарантии доставки.wait_for_async_insert=0: Коннектор подтверждает приём сразу после буферизации. Более высокая производительность, но данные могут быть потеряны при сбое сервера до выполнения сброса.
Настройка поведения асинхронных вставок
Вы можете тонко настроить поведение сброса при асинхронных вставках:
Общие параметры настройки:
async_insert_max_data_size(по умолчанию: 10485760 / 10 MB): Максимальный размер буфера перед сбросомasync_insert_busy_timeout_ms(по умолчанию: 1000): Максимальное время (мс) до сбросаasync_insert_stale_timeout_ms(по умолчанию: 0): Время (мс) с момента последней вставки до сбросаasync_insert_max_query_number(по умолчанию: 100): Максимальное количество запросов до сброса
Компромиссы:
- Преимущества: Меньше частей, лучшая производительность слияний, меньшая нагрузка на CPU, улучшенная пропускная способность при высокой конкурентности
- Особенности: Данные не сразу доступны для запросов, немного увеличенная сквозная задержка
- Риски: Потеря данных при сбое сервера, если
wait_for_async_insert=0, повышенная нагрузка на память при больших буферах
Асинхронные вставки с семантикой exactly-once
При использовании exactlyOnce=true с асинхронными вставками:
Важно: Всегда используйте wait_for_async_insert=1 с режимом «exactly-once», чтобы фиксация смещений выполнялась только после сохранения данных.
Дополнительную информацию об асинхронных вставках см. в документации ClickHouse по асинхронным вставкам.
Параллелизм коннектора
Увеличьте параллелизм, чтобы повысить пропускную способность:
Задачи на коннектор
Каждая задача обрабатывает подмножество разделов топика. Больше задач = выше уровень параллелизма, но:
- Максимально эффективное число задач = количество разделов топика
- Каждая задача поддерживает собственное соединение с ClickHouse
- Больше задач = большие накладные расходы и потенциальная конкуренция за ресурсы
Рекомендация: Начните с значения tasks.max, равного количеству разделов топика, затем корректируйте его на основе метрик по CPU и пропускной способности.
Игнорирование разделов при пакетировании
По умолчанию коннектор формирует пакеты сообщений по разделам. Для более высокой пропускной способности можно пакетировать сообщения по нескольким разделам:
Предупреждение: Используйте только при exactlyOnce=false. Этот параметр может повысить пропускную способность за счёт формирования более крупных пакетов, но при этом теряются гарантии порядка внутри раздела (partition).
Несколько топиков с высокой пропускной способностью
Если ваш коннектор настроен на подписку на несколько топиков, вы используете topic2TableMap для отображения топиков в таблицы и сталкиваетесь с узким местом при вставке, приводящим к отставанию консьюмера, рассмотрите возможность создания отдельного коннектора для каждого топика.
Основная причина этого в том, что в текущей реализации пакеты вставляются в каждую таблицу последовательно.
Рекомендация: Для нескольких высоконагруженных топиков разверните по одному экземпляру коннектора на каждый топик, чтобы максимизировать параллельную скорость вставки.
Особенности выбора движка таблиц ClickHouse
Выберите подходящий движок таблиц ClickHouse для вашего сценария использования:
MergeTree: Оптимален для большинства сценариев, обеспечивает баланс между производительностью запросов и вставокReplicatedMergeTree: Необходим для высокой доступности, но добавляет накладные расходы на репликацию*MergeTreeс корректнымORDER BY: Оптимизируйте под ваши шаблоны запросов
Параметры, которые стоит рассмотреть:
Параметры вставки на уровне коннектора:
Пул подключений и тайм-ауты
Коннектор поддерживает HTTP‑подключения к ClickHouse. Настройте тайм-ауты для сетей с высокой задержкой:
socket_timeout(по умолчанию: 30000 мс): Максимальное время ожидания операций чтенияconnection_timeout(по умолчанию: 10000 мс): Максимальное время ожидания установления соединения
Увеличьте эти значения, если вы сталкиваетесь с ошибками тайм-аута при работе с крупными пакетами данных.
Мониторинг и устранение неполадок, связанных с производительностью
Отслеживайте следующие ключевые метрики:
- Задержка потребителя (consumer lag): Используйте инструменты мониторинга Kafka для отслеживания задержки по разделам (partition)
- Метрики коннектора: Отслеживайте
receivedRecords,recordProcessingTime,taskProcessingTimeчерез JMX (см. Monitoring) - Метрики ClickHouse:
system.asynchronous_inserts: Отслеживайте использование буфера асинхронных вставокsystem.parts: Отслеживайте количество частей (parts) для выявления проблем со слияниямиsystem.merges: Отслеживайте активные слиянияsystem.events: ОтслеживайтеInsertedRows,InsertedBytes,FailedInsertQuery
Распространённые проблемы с производительностью:
| Симптом | Возможная причина | Решение |
|---|---|---|
| Большое отставание consumer'а | Слишком маленькие батчи | Увеличьте max.poll.records, включите async inserts |
| Ошибки "Too many parts" | Частые мелкие вставки | Включите async inserts, увеличьте размер батча |
| Ошибки тайм-аута | Большой размер батча, медленная сеть | Уменьшите размер батча, увеличьте socket_timeout, проверьте сеть |
| Высокая загрузка CPU | Слишком много мелких частей | Включите async inserts, увеличьте настройки merge |
| Ошибки OutOfMemory | Слишком большой размер батча | Уменьшите max.poll.records, max.partition.fetch.bytes |
| Неравномерная нагрузка на задачи | Неравномерное распределение партиций | Перебалансируйте партиции или скорректируйте tasks.max |
Краткое резюме передовых практик
- Начните со значений по умолчанию, затем измеряйте и настраивайте на основе фактической производительности
- Предпочитайте более крупные батчи: по возможности нацеливайтесь на 10 000–100 000 строк на вставку
- Используйте async inserts, когда отправляете много мелких батчей или при высокой конкурентности
- Всегда используйте
wait_for_async_insert=1при необходимости строгой семантики exactly-once - Масштабируйтесь горизонтально: увеличивайте
tasks.maxвплоть до количества партиций - По одному коннектору на топик с высоким трафиком для максимальной пропускной способности
- Непрерывно отслеживайте: мониторьте отставание consumer'а, количество частей и активность операций merge
- Тщательно тестируйте: всегда проверяйте изменения конфигурации под реалистичной нагрузкой перед промышленным развертыванием
Пример: конфигурация для высокой пропускной способности
Ниже приведён полный пример, оптимизированный для высокой пропускной способности:
Эта конфигурация:
- Обрабатывает до 10 000 записей за один опрос
- Формирует батчи по нескольким партициям для более крупных вставок
- Использует асинхронные вставки с буфером 16 MB
- Запускает 8 параллельных задач (подберите значение под количество партиций)
- Оптимизирована на максимальную пропускную способность, а не на строгий порядок
Устранение неполадок
"State mismatch for topic [someTopic] partition [0]"
Это происходит, когда смещение, хранящееся в KeeperMap, отличается от смещения, хранящегося в Kafka, обычно когда топик был удалён или смещение было изменено вручную. Чтобы исправить это, необходимо удалить старые значения, сохранённые для данного топика и партиции.
ПРИМЕЧАНИЕ: Это изменение может повлиять на семантику exactly-once.
"What errors will the connector retry?"
Сейчас внимание сосредоточено на определении ошибок, которые являются временными и могут быть повторно выполнены, включая:
ClickHouseException— это общее исключение, которое может быть выброшено ClickHouse. Обычно оно выбрасывается, когда сервер перегружен, и следующие коды ошибок считаются особенно подходящими для повторной попытки:- 3 - UNEXPECTED_END_OF_FILE
- 159 - TIMEOUT_EXCEEDED
- 164 - READONLY
- 202 - TOO_MANY_SIMULTANEOUS_QUERIES
- 203 - NO_FREE_CONNECTION
- 209 - SOCKET_TIMEOUT
- 210 - NETWORK_ERROR
- 242 - TABLE_IS_READ_ONLY
- 252 - TOO_MANY_PARTS
- 285 - TOO_FEW_LIVE_REPLICAS
- 319 - UNKNOWN_STATUS_OF_INSERT
- 425 - SYSTEM_ERROR
- 999 - KEEPER_EXCEPTION
- 1002 - UNKNOWN_EXCEPTION
SocketTimeoutException— выбрасывается, когда соединение по сокету превышает таймаут.UnknownHostException— выбрасывается, когда не удаётся разрешить имя хоста.IOException— выбрасывается, когда возникает проблема с сетью.
"Все мои данные пустые/нули"
Скорее всего, поля в ваших данных не соответствуют полям в таблице — это особенно часто встречается с CDC (фиксацией изменений данных) и форматом Debezium.
Один из распространённых способов решения — добавить преобразование flatten в конфигурацию вашего коннектора:
Это преобразует данные из вложенного JSON в плоский JSON (используя _ в качестве разделителя). Поля в таблице затем будут иметь формат "field1_field2_field3" (например, "before_id", "after_id" и т. д.).
"Я хочу использовать свои Kafka-ключи в ClickHouse"
Ключи Kafka по умолчанию не хранятся в поле value, но вы можете использовать преобразование KeyToValue, чтобы переместить ключ в поле value (под новым именем поля _key):
