Проектирование схемы для наблюдаемости
Мы рекомендуем пользователям всегда создавать собственную схему для логов и трейсов по следующим причинам:
- Выбор первичного ключа - Схемы по умолчанию используют
ORDER BY, оптимизированный под конкретные шаблоны доступа. Маловероятно, что ваши шаблоны доступа будут с ними совпадать. - Извлечение структуры - Пользователи могут захотеть извлекать новые столбцы из существующих столбцов, например столбца
Body. Это можно сделать с помощью материализованных столбцов (и материализованных представлений в более сложных случаях). Для этого требуются изменения схемы. - Оптимизация Map - Схемы по умолчанию используют тип Map для хранения атрибутов. Эти столбцы позволяют хранить произвольные метаданные. Хотя это критически важная возможность, поскольку метаданные событий часто не определены заранее и иначе не могут быть сохранены в строго типизированной базе данных, такой как ClickHouse, доступ к ключам Map и их значениям менее эффективен, чем доступ к обычному столбцу. Мы решаем эту проблему, модифицируя схему и вынося наиболее часто используемые ключи Map в столбцы верхнего уровня — см. раздел "Extracting structure with SQL". Для этого требуется изменение схемы.
- Упрощение доступа к ключам Map - Доступ к ключам в Map требует более многословного синтаксиса. Пользователи могут минимизировать это неудобство с помощью алиасов. См. раздел "Using Aliases", чтобы упростить запросы.
- Вторичные индексы - Схема по умолчанию использует вторичные индексы для ускорения доступа к Map и ускорения текстовых запросов. Обычно они не нужны и потребляют дополнительное дисковое пространство. Их можно использовать, но следует протестировать, чтобы убедиться, что они действительно необходимы. См. раздел "Secondary / Data Skipping indices".
- Использование Codecs - Пользователи могут захотеть настраивать кодеки для столбцов, если они понимают ожидаемые данные и имеют подтверждение, что это улучшает сжатие.
Ниже мы подробно описываем каждый из приведённых выше вариантов использования.
Важно: Хотя пользователям рекомендуется расширять и изменять свою схему для достижения оптимального сжатия и производительности запросов, по возможности им следует придерживаться соглашений об именовании схемы OTel для основных столбцов. Плагин ClickHouse для Grafana предполагает наличие некоторых базовых столбцов OTel для помощи в построении запросов, например Timestamp и SeverityText. Требуемые столбцы для логов и трейсов задокументированы здесь [1][2] и здесь соответственно. Вы можете переименовать эти столбцы, переопределив значения по умолчанию в конфигурации плагина.
Извлечение структуры с помощью SQL
Независимо от того, выполняется ли приём структурированных или неструктурированных логов, пользователям часто требуется возможность:
- Извлекать столбцы из строковых blob-объектов. Запросы к таким столбцам будут выполняться быстрее, чем использование строковых операций во время выполнения запроса.
- Извлекать ключи из map-структур. Базовая схема помещает произвольные атрибуты в столбцы типа Map. Этот тип предоставляет возможность работы без фиксированной схемы, что позволяет пользователям не определять заранее столбцы для атрибутов при описании логов и трейсов — часто это невозможно при сборе логов из Kubernetes и необходимости гарантировать сохранность меток подов для последующего поиска. Доступ к ключам map и их значениям медленнее, чем запрос по обычным столбцам ClickHouse. Поэтому извлечение ключей из map в корневые столбцы таблицы часто предпочтительно.
Рассмотрим следующие запросы:
Предположим, мы хотим посчитать, какие URL-пути получают больше всего POST-запросов, используя структурированные логи. JSON blob хранится в столбце Body как String. Дополнительно он может также храниться в столбце LogAttributes как Map(String, String), если пользователь включил json_parser в коллекторе.
Предположим, что LogAttributes доступен. Тогда запрос, который подсчитывает, какие URL‑пути сайта получают больше всего POST‑запросов:
Обратите внимание на использование здесь синтаксиса отображения (map), например LogAttributes['request_path'], а также функции path для удаления параметров запроса из URL.
Если пользователь не включил разбор JSON в коллекторе, то LogAttributes будет пустым, что вынудит нас использовать JSON-функции для извлечения столбцов из строки типа String Body.
В целом мы рекомендуем выполнять разбор JSON в ClickHouse для структурированных логов. Мы уверены, что ClickHouse обеспечивает самое быстрое выполнение разбора JSON. Однако мы понимаем, что пользователи могут хотеть отправлять логи в другие системы и не реализовывать эту логику в SQL.
Теперь рассмотрим то же для неструктурированных логов:
Для аналогичного запроса к неструктурированным логам необходимо использовать регулярные выражения через функцию extractAllGroupsVertical.
Повышенная сложность и ресурсоёмкость запросов для парсинга неструктурированных логов (обратите внимание на разницу в производительности) — причина, по которой мы рекомендуем пользователям по возможности всегда использовать структурированные логи.
Приведённый выше запрос можно оптимизировать, используя словари регулярных выражений. См. подробности в разделе Использование словарей.
Оба этих сценария могут быть реализованы в ClickHouse за счёт переноса описанной выше логики запроса на этап вставки данных. Ниже мы рассмотрим несколько подходов и укажем, когда каждый из них уместен.
Пользователи также могут выполнять обработку с использованием процессоров и операторов OTel collector, как описано здесь. В большинстве случаев пользователи увидят, что ClickHouse значительно эффективнее по использованию ресурсов и быстрее, чем процессоры OTel collector. Основной недостаток выполнения всей обработки событий с помощью SQL — это привязка вашего решения к ClickHouse. Например, пользователи могут захотеть отправлять обработанные логи из OTel collector в другие системы, например в S3.
Материализованные столбцы
Материализованные столбцы являются самым простым способом извлечь структуру из других столбцов. Значения таких столбцов всегда вычисляются во время вставки и не могут быть указаны в запросах INSERT.
Материализованные столбцы создают дополнительный расход дискового пространства, так как значения при вставке извлекаются в новые столбцы на диске.
Материализованные столбцы поддерживают любое выражение ClickHouse и могут использовать любые аналитические функции для обработки строк (включая регулярные выражения и поиск) и URL, выполнения преобразований типов, извлечения значений из JSON или математических операций.
Мы рекомендуем материализованные столбцы для базовой обработки. Они особенно полезны для извлечения значений из карт (Map), поднятия их в корневые столбцы и выполнения преобразований типов. Особенно эффективны они в очень простых схемах или при совместном использовании с материализованными представлениями. Рассмотрим следующую схему для логов, из которых сборщик извлёк JSON в столбец LogAttributes:
Эквивалентную схему для извлечения с использованием JSON-функций из строки Body можно найти здесь.
Наши три материализованных столбца извлекают запрашиваемую страницу, тип запроса и домен реферера. Они обращаются к ключам Map и применяют функции к их значениям. Наш последующий запрос выполняется значительно быстрее:
Материализованные столбцы по умолчанию не возвращаются в результате SELECT *. Это необходимо для сохранения свойства, что результат SELECT * всегда можно вставить обратно в таблицу с помощью команды INSERT. Такое поведение можно отключить, установив asterisk_include_materialized_columns=1, а также включить в Grafana (см. Additional Settings -> Custom Settings в конфигурации источника данных).
Материализованные представления
Материализованные представления предоставляют более мощный способ применения SQL-фильтрации и преобразований к логам и трейсам.
Материализованные представления позволяют перенести затраты на вычисления с момента выполнения запроса на момент вставки данных. Материализованное представление в ClickHouse — это просто триггер, который выполняет запрос над блоками данных по мере их вставки в таблицу. Результаты этого запроса вставляются во вторую «целевую» таблицу.
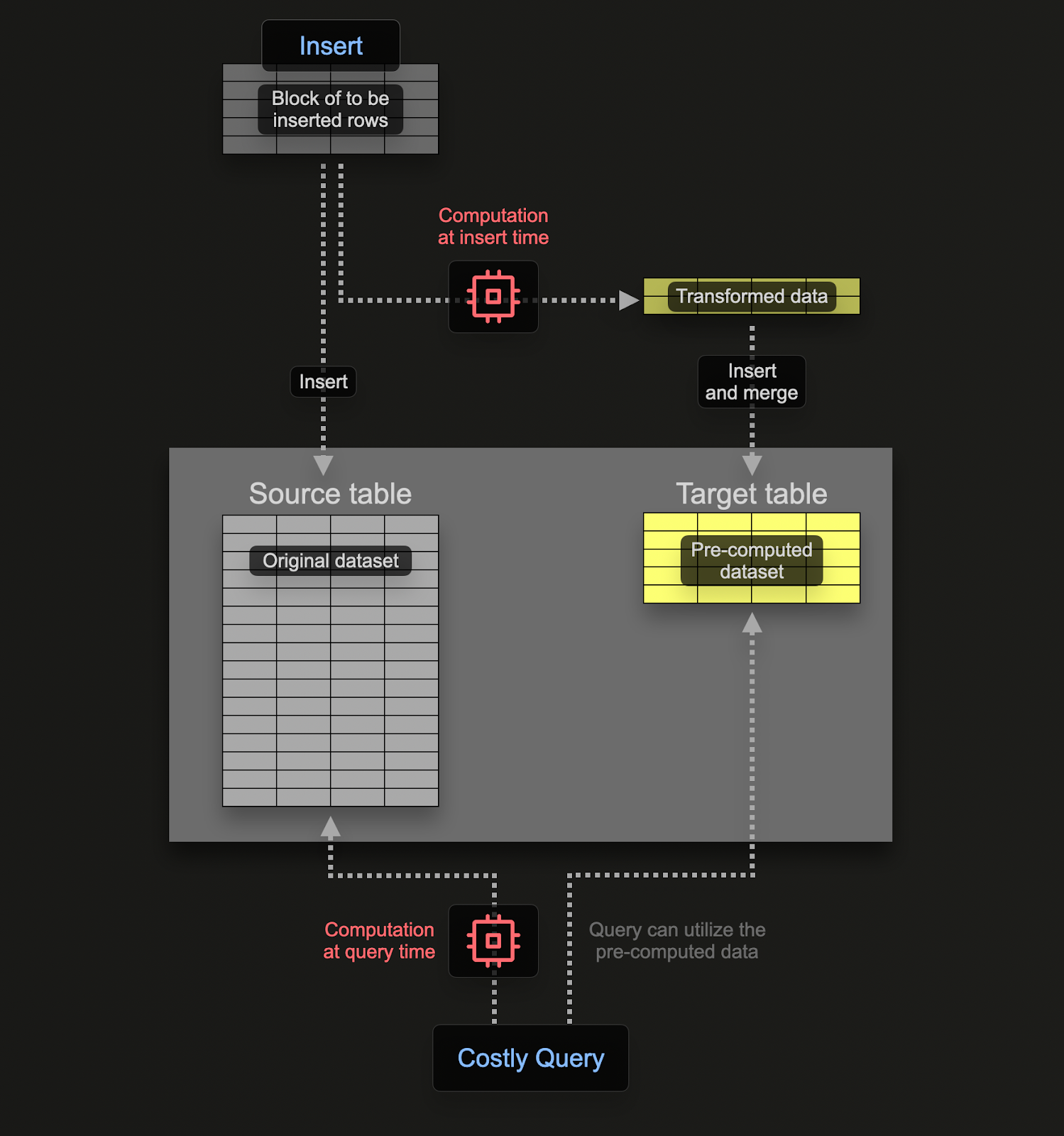
Материализованные представления в ClickHouse обновляются в реальном времени по мере поступления данных в таблицу, на которой они основаны, функционируя скорее как постоянно обновляющиеся индексы. Напротив, в других базах данных материализованные представления, как правило, представляют собой статичные снимки результата запроса, которые необходимо обновлять (аналогично ClickHouse Refreshable Materialized Views).
Запрос, связанный с материализованным представлением, теоретически может быть любым запросом, включая агрегацию, хотя существуют ограничения при использовании Joins. Для задач по преобразованию и фильтрации, необходимых для логов и трейсов, можно считать допустимым любой SELECT‑запрос.
Пользователям следует помнить, что запрос — это всего лишь триггер, выполняющийся над строками, вставляемыми в таблицу (исходную таблицу), а результаты отправляются в новую таблицу (целевую таблицу).
Чтобы гарантировать, что мы не будем сохранять данные дважды (в исходной и целевой таблицах), мы можем изменить движок исходной таблицы на Null table engine, сохранив исходную схему. Наши OTel collector будут продолжать отправлять данные в эту таблицу. Например, для логов таблица otel_logs становится:
Движок таблицы Null — это мощная оптимизация, по сути аналог устройства /dev/null. Эта таблица не будет хранить данные, но любые привязанные к ней материализованные представления всё равно будут выполняться над вставляемыми строками до того, как они будут отброшены.
Рассмотрим следующий запрос. Он преобразует строки в нужный нам формат, извлекая все столбцы из LogAttributes (предполагаем, что они заполняются коллектором с использованием оператора json_parser), а также устанавливая SeverityText и SeverityNumber (на основе некоторых простых условий и определения этих столбцов). В данном случае мы также выбираем только те столбцы, про которые знаем, что они будут заполнены, игнорируя такие столбцы, как TraceId, SpanId и TraceFlags.
Мы также извлекаем столбец Body в приведённом выше примере — на случай, если позже будут добавлены дополнительные атрибуты, которые не извлекаются нашим SQL. Этот столбец должен хорошо сжиматься в ClickHouse и будет редко запрашиваться, поэтому не повлияет на производительность запросов. Наконец, мы приводим Timestamp к типу DateTime (чтобы сэкономить место — см. «Optimizing Types») с помощью cast.
Обратите внимание на использование conditionals выше для извлечения SeverityText и SeverityNumber. Они чрезвычайно полезны для формулирования сложных условий и проверки, заданы ли значения в map-структурах — мы наивно предполагаем, что все ключи существуют в LogAttributes. Мы рекомендуем пользователям освоить их — это ваш лучший помощник при разборе логов, в дополнение к функциям для обработки null values!
Нам требуется таблица для приёма этих результатов. Приведённая ниже целевая таблица соответствует запросу выше:
Выбранные здесь типы основаны на оптимизациях, описанных в разделе "Optimizing types".
Обратите внимание, насколько сильно мы изменили нашу схему. На практике у пользователей, вероятно, также будут столбцы трассировок (Trace), которые они захотят сохранить, а также столбец ResourceAttributes (обычно он содержит метаданные Kubernetes). Grafana может использовать столбцы трассировок для связывания логов и трассировок — см. "Using Grafana".
Ниже мы создаём материализованное представление otel_logs_mv, которое выполняет указанную выше выборку для таблицы otel_logs и отправляет результаты в otel_logs_v2.
Все вышеописанное показано ниже:
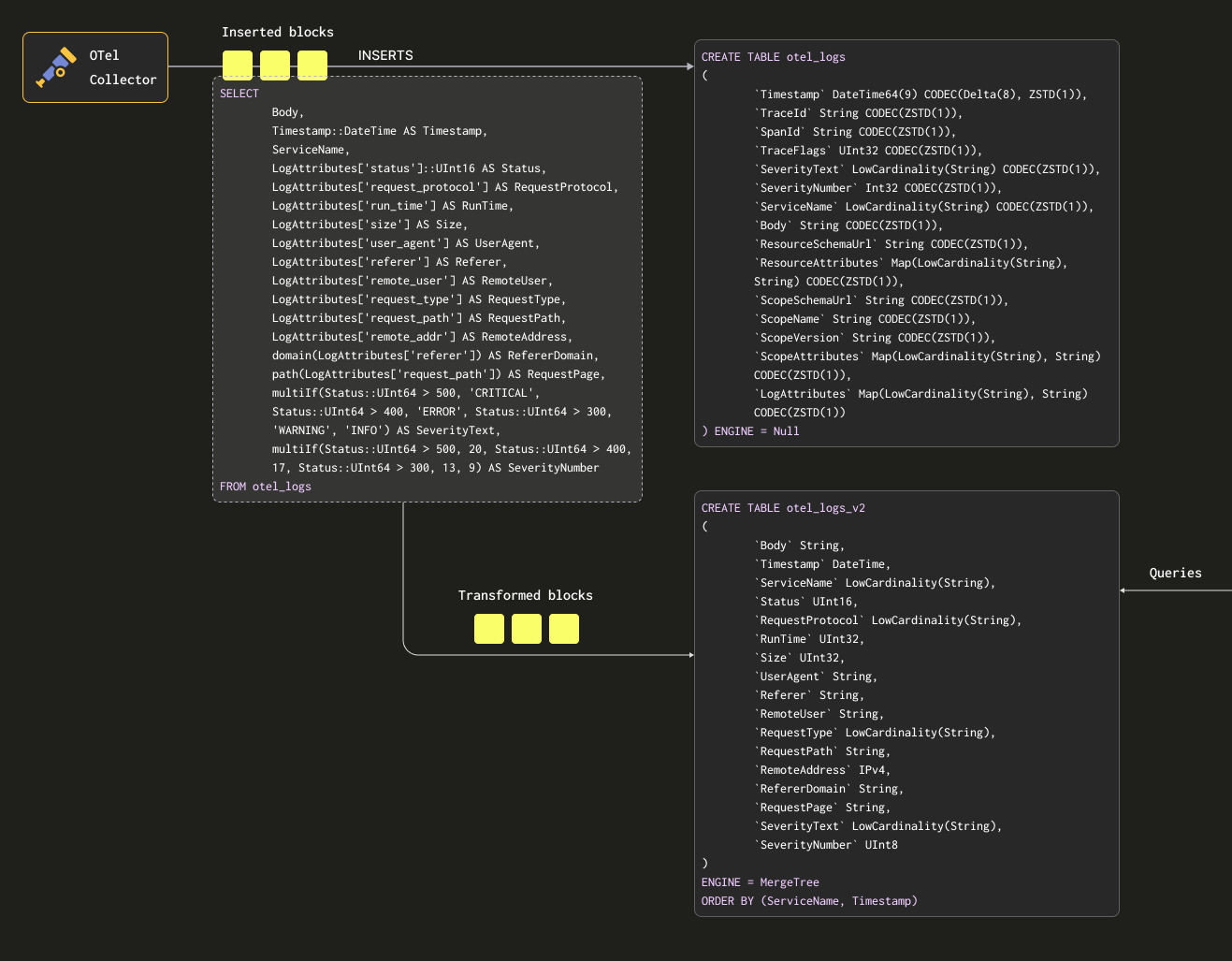
Если теперь перезапустить конфигурацию коллектора, используемую в разделе "Экспорт в ClickHouse", данные появятся в otel_logs_v2 в требуемом формате. Обратите внимание на использование типизированных функций извлечения JSON.
Эквивалентное материализованное представление, которое опирается на извлечение столбцов из колонки Body с помощью JSON-функций, показано ниже:
Осторожно с типами
Вышеописанные материализованные представления опираются на неявное приведение типов — особенно при использовании map LogAttributes. ClickHouse часто прозрачно приводит извлечённое значение к типу целевой таблицы, сокращая необходимый синтаксис. Однако мы рекомендуем всегда тестировать представления, выполняя их оператор SELECT совместно с оператором INSERT INTO в целевую таблицу с той же схемой. Это позволит убедиться, что типы обрабатываются корректно. Особое внимание следует уделить следующим случаям:
- Если ключ не существует в map, будет возвращена пустая строка. В случае числовых типов такие значения необходимо заменить на корректные. Это можно сделать с помощью условных выражений, например
if(LogAttributes['status'] = "", 200, LogAttributes['status']), или функций приведения типов, если допустимы значения по умолчанию, напримерtoUInt8OrDefault(LogAttributes['status']). - Некоторые типы не всегда будут приводиться, например строковые представления чисел не будут приводиться к значениям enum.
- Функции извлечения из JSON возвращают значения по умолчанию для своего типа, если значение не найдено. Убедитесь, что эти значения имеют смысл!
Избегайте использования Nullable в ClickHouse для данных наблюдаемости (Observability). В логах и трассировках редко требуется различать пустое значение и null. Эта возможность увеличивает накладные расходы на хранение и негативно сказывается на производительности запросов. Дополнительные подробности см. здесь.
Выбор первичного (упорядочивающего) ключа
После того как вы выделили нужные столбцы, можно переходить к оптимизации вашего упорядочивающего/первичного ключа.
Можно применить несколько простых правил, которые помогут выбрать упорядочивающий ключ. Следующие рекомендации иногда могут конфликтовать друг с другом, поэтому учитывайте их по порядку. В результате пользователи могут определить несколько ключей; обычно достаточно 4–5:
- Выбирайте столбцы, которые соответствуют вашим типичным фильтрам и паттернам доступа. Если пользователи обычно начинают расследования в Observability с фильтрации по определённому столбцу, например имени пода, этот столбец будет часто использоваться в предложениях
WHERE. Отдавайте приоритет включению таких столбцов в ключ по сравнению с теми, которые используются реже. - Предпочитайте столбцы, которые при фильтрации помогают исключить большой процент всех строк, тем самым уменьшая объём данных, который нужно прочитать. Часто хорошими кандидатами являются имена сервисов и коды статусов — во втором случае только если пользователи фильтруют по значениям, исключающим большую часть строк; например, фильтрация по 200-м в большинстве систем будет соответствовать большинству строк, в отличие от ошибок 500, которые будут соответствовать небольшой подвыборке.
- Предпочитайте столбцы, которые, вероятно, будут сильно коррелировать с другими столбцами в таблице. Это поможет обеспечить, что соответствующие значения также будут храниться непрерывно, улучшая сжатие.
- Операции
GROUP BYиORDER BYдля столбцов в упорядочивающем ключе могут быть сделаны более экономными по памяти.
Определив подмножество столбцов для упорядочивающего ключа, необходимо задать их в определённом порядке. Этот порядок может существенно влиять как на эффективность фильтрации по столбцам вторичного ключа в запросах, так и на коэффициент сжатия файлов данных таблицы. В общем случае лучше упорядочивать ключи в порядке возрастания их кардинальности. Это следует сбалансировать с тем фактом, что фильтрация по столбцам, которые появляются позже в упорядочивающем ключе, будет менее эффективной, чем фильтрация по тем, которые стоят раньше в кортеже. Сбалансируйте эти свойства и учитывайте ваши паттерны доступа. И самое важное — тестируйте варианты. Для более глубокого понимания упорядочивающих ключей и их оптимизации рекомендуем эту статью.
Мы рекомендуем определять упорядочивающие ключи после того, как вы структурировали свои логи. Не используйте ключи в картах атрибутов для упорядочивающего ключа или JSON-выражения для извлечения данных. Убедитесь, что ваши упорядочивающие ключи представлены как корневые столбцы в вашей таблице.
Использование map
В более ранних примерах показано использование синтаксиса map['key'] для доступа к значениям в столбцах типа Map(String, String). Помимо использования нотации map для доступа к вложенным ключам, в ClickHouse доступны специализированные функции работы с map для фильтрации или выборки данных из этих столбцов.
Например, следующий запрос выявляет все уникальные ключи, доступные в столбце LogAttributes, используя функцию mapKeys, а затем функцию groupArrayDistinctArray (комбинатор).
Мы не рекомендуем использовать точки в именах столбцов Map и в дальнейшем можем признать такое использование устаревшим. Используйте _.
Использование алиасов
Запросы к типам Map выполняются медленнее, чем к обычным столбцам — см. раздел "Ускорение запросов". Кроме того, синтаксис таких запросов более сложен и может быть неудобен для пользователей. Чтобы решить последнюю проблему, мы рекомендуем использовать столбцы типа ALIAS.
Столбцы типа ALIAS вычисляются во время выполнения запроса и не хранятся в таблице. Поэтому невозможно выполнить INSERT в столбец этого типа. Используя алиасы, мы можем обращаться к ключам Map и упростить синтаксис, прозрачно выводя элементы Map как обычные столбцы. Рассмотрим следующий пример:
У нас есть несколько материализованных столбцов и столбец ALIAS — RemoteAddr, который обращается к карте LogAttributes. Теперь мы можем запрашивать значения LogAttributes['remote_addr'] через этот столбец, тем самым упрощая запрос, например:
Кроме того, добавить ALIAS очень просто с помощью команды ALTER TABLE. Эти столбцы сразу становятся доступными, например:
По умолчанию SELECT * исключает столбцы типа ALIAS. Это поведение можно изменить, установив asterisk_include_alias_columns=1.
Оптимизация типов
Общие рекомендации ClickHouse по оптимизации типов также относятся к данному сценарию использования ClickHouse.
Использование кодеков
Помимо оптимизаций типов, пользователи могут следовать общим рекомендациям по использованию кодеков при оптимизации сжатия для схем ClickHouse Observability.
Как правило, кодек ZSTD очень хорошо подходит для наборов данных журналов и трассировок. Увеличение уровня сжатия по сравнению со значением по умолчанию 1 может улучшить степень сжатия. Однако это следует проверять, так как более высокие значения увеличивают нагрузку на CPU в момент вставки. На практике мы редко видим существенную выгоду от увеличения этого значения.
Кроме того, отметки времени, хотя и выигрывают от дельта-кодирования с точки зрения сжатия, по наблюдениям приводят к медленной работе запросов, если этот столбец используется в первичном ключе или ключе сортировки. Мы рекомендуем пользователям оценить баланс между степенью сжатия и производительностью запросов.
Использование словарей
Словари — это ключевая возможность ClickHouse, обеспечивающая хранящееся в памяти представление данных в формате key-value из различных внутренних и внешних источников, оптимизированное для запросов с крайне низкими задержками при поиске по ключу.
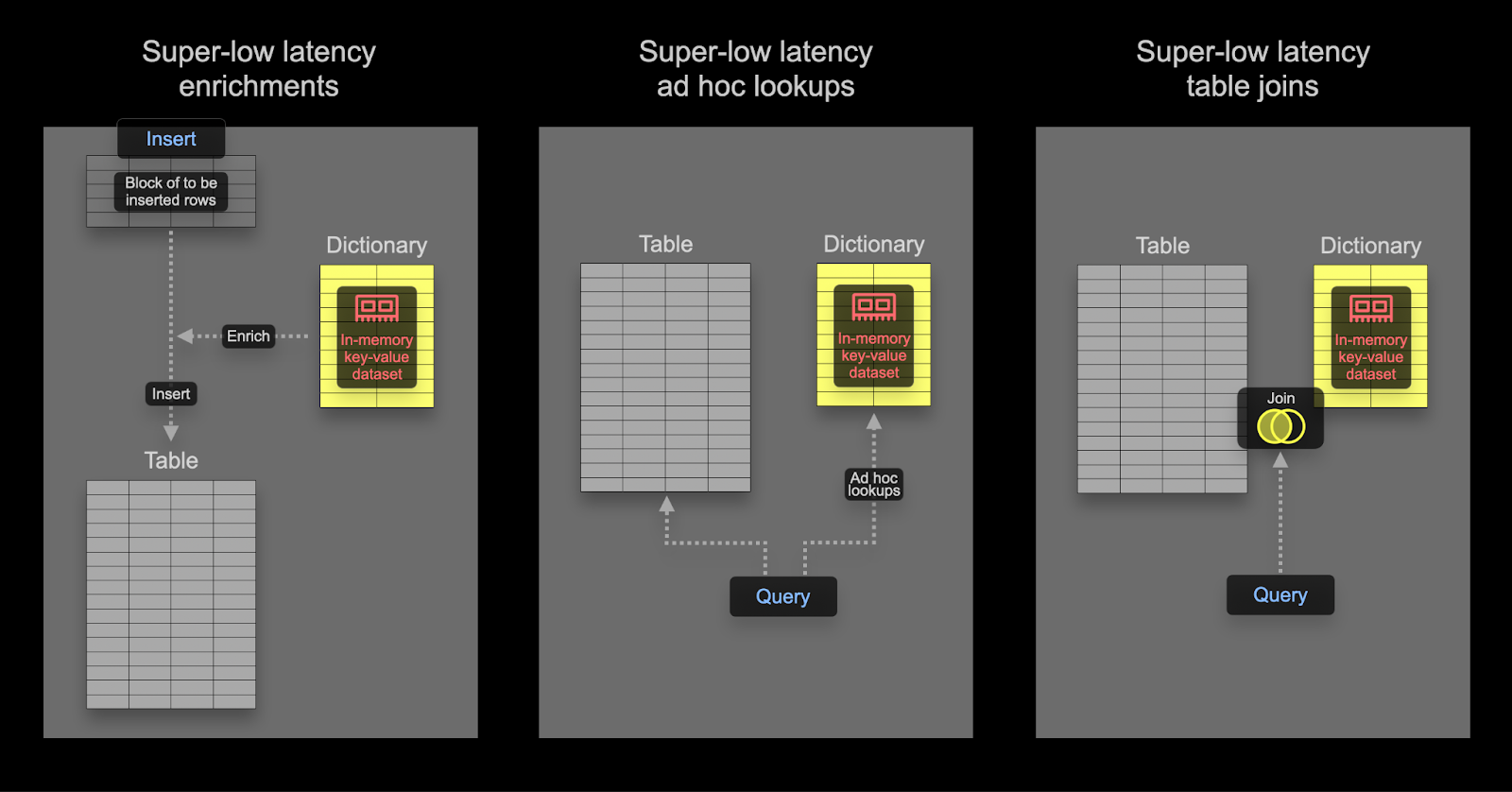
Это полезно в различных сценариях — от обогащения данных при их приёме «на лету» без замедления процесса ингестии до общего улучшения производительности запросов, особенно с использованием JOIN, где достигается наибольший выигрыш. Хотя JOIN-операции редко требуются в сценариях Observability, словари по-прежнему могут быть полезны для обогащения — как на этапе вставки, так и на этапе выполнения запросов. Ниже приведены примеры обоих подходов.
Пользователи, заинтересованные в ускорении JOIN-операций с помощью словарей, могут найти дополнительную информацию здесь.
Время вставки и время запроса
Словари можно использовать для обогащения наборов данных как во время запроса, так и во время вставки. У каждого из этих подходов есть свои преимущества и недостатки. Вкратце:
- Время вставки — Как правило, этот вариант подходит, если обогащающие значения не меняются и находятся во внешнем источнике, который можно использовать для заполнения словаря. В этом случае обогащение строки во время вставки позволяет избежать обращения к словарю во время запроса. Это происходит за счёт производительности вставки, а также дополнительных затрат на хранение, так как обогащённые значения будут храниться в отдельных столбцах.
- Время запроса — Если значения в словаре часто меняются, то обращения во время запроса обычно более целесообразны. Это позволяет избежать необходимости обновлять столбцы (и перезаписывать данные), если сопоставляемые значения изменяются. Такая гибкость достигается ценой обращений к словарю во время запроса. Эти затраты обычно ощутимы, если требуется поиск для большого количества строк, например, при использовании обращения к словарю в предикате фильтра. Для обогащения результата, т.е. в
SELECT, эта накладная стоимость, как правило, несущественна.
Мы рекомендуем пользователям ознакомиться с базовыми принципами работы со словарями. Словари предоставляют располагаемую в памяти таблицу поиска, из которой значения могут извлекаться с помощью специализированных функций.
Простые примеры обогащения см. в руководстве по словарям здесь. Ниже мы сосредоточимся на типичных задачах обогащения данных для обсервабилити.
Использование IP-словарей
Геообогащение логов и трейсов значениями широты и долготы по IP-адресам — распространённое требование в задачах Observability. Это можно реализовать с помощью структурированного словаря ip_trie.
Мы используем общедоступный датасет DB-IP с точностью до города, предоставляемый DB-IP.com на условиях лицензии CC BY 4.0.
Из файла readme видно, что данные имеют следующую структуру:
Учитывая такую структуру, давайте сначала посмотрим на данные с помощью табличной функции url():
Чтобы упростить себе жизнь, давайте используем табличный движок URL(), чтобы создать объект таблицы ClickHouse с нашими именами полей и подтвердить общее количество строк:
Поскольку наш словарь ip_trie требует, чтобы диапазоны IP-адресов задавались в формате CIDR, нам нужно будет преобразовать ip_range_start и ip_range_end.
CIDR-блок для каждого диапазона можно получить с помощью следующего запроса:
В приведённом выше запросе происходит много всего. Тем, кому интересно, рекомендуется прочитать это отличное объяснение. Иначе просто считайте, что выше вычисляется CIDR для диапазона IP-адресов.
Для наших целей нам понадобятся только диапазон IP-адресов, код страны и координаты, поэтому давайте создадим новую таблицу и добавим в неё наши данные GeoIP:
Чтобы выполнять низкозадержочный поиск по IP‑адресам в ClickHouse, мы будем использовать словари для хранения отображения ключ → атрибуты для наших GeoIP‑данных в памяти. ClickHouse предоставляет структуру словаря ip_trie (dictionary structure) для сопоставления наших сетевых префиксов (CIDR-блоков) с координатами и кодами стран. Следующий запрос задаёт словарь с такой структурой и использует приведённую выше таблицу в качестве источника.
Мы можем выбрать строки из словаря и убедиться, что этот набор данных доступен для обращений по ключу:
Справочники в ClickHouse периодически обновляются на основе данных базовой таблицы и использованного выше предложения lifetime. Чтобы обновить наш Geo IP-справочник в соответствии с последними изменениями в наборе данных DB-IP, нам достаточно повторно загрузить данные из удалённой таблицы geoip_url в таблицу geoip с применёнными преобразованиями.
Теперь, когда данные Geo IP загружены в наш справочник ip_trie (который для удобства также называется ip_trie), мы можем использовать его для геолокации по IP-адресу. Это можно сделать с помощью функции dictGet() следующим образом:
Обратите внимание на скорость выборки данных. Это позволяет нам обогащать логи. В данном случае мы выбираем вариант обогащения во время выполнения запроса.
Возвращаясь к нашему исходному набору логов, мы можем использовать описанное выше, чтобы агрегировать логи по странам. Далее предполагается, что мы используем схему, полученную из нашего ранее созданного материализованного представления, в которой есть извлечённый столбец RemoteAddress.
Поскольку соответствие IP-адреса географическому местоположению может меняться, пользователям, скорее всего, важно знать, откуда был отправлен запрос в момент его совершения, а не то, каково текущее географическое местоположение для того же адреса. По этой причине здесь, скорее всего, предпочтительно обогащение на этапе индексирования. Это можно сделать с помощью материализованных столбцов, как показано ниже, или в предложении SELECT материализованного представления:
Пользователям, скорее всего, понадобится, чтобы словарь обогащения IP-адресов периодически обновлялся на основе новых данных. Это можно реализовать с помощью параметра словаря LIFETIME, который приведёт к периодической перезагрузке словаря из базовой таблицы. Инструкции по обновлению базовой таблицы приведены в разделе "Обновляемые материализованные представления".
Указанные выше страны и координаты предоставляют возможности визуализации, выходящие за рамки простой группировки и фильтрации по стране. В качестве примера см. раздел "Визуализация геоданных".
Использование regex-словарей (разбор user agent)
Разбор строк user agent — это классическая задача для регулярных выражений и распространённое требование для наборов данных, основанных на логах и трассировках. ClickHouse предоставляет эффективный разбор строк user agent с использованием Regular Expression Tree Dictionaries.
Деревья регулярных выражений для словарей определяются в open-source-версии ClickHouse с использованием типа источника словаря YAMLRegExpTree, который указывает путь к YAML-файлу, содержащему дерево регулярных выражений. Если вы хотите использовать собственный словарь регулярных выражений, подробности о требуемой структуре можно найти здесь. Ниже мы сосредоточимся на разборе строк user agent с использованием uap-core и загрузим словарь в поддерживаемый CSV-формат. Этот подход совместим как с open-source-версией ClickHouse (OSS), так и с ClickHouse Cloud.
В примерах ниже мы используем актуальные на июнь 2024 года срезы регулярных выражений uap-core для разбора строк user agent. Последнюю версию файла, который время от времени обновляется, можно найти здесь. Пользователи могут выполнить шаги, описанные здесь, чтобы загрузить данные в CSV-файл, используемый ниже.
Создайте следующие таблицы типа Memory. Они будут содержать наши регулярные выражения для разбора устройств, браузеров и операционных систем.
Эти таблицы можно заполнить из следующих публично размещённых CSV-файлов с помощью табличной функции url:
После заполнения таблиц в памяти мы можем загрузить словари регулярных выражений. Обратите внимание, что необходимо указать значения ключей как столбцы — это будут атрибуты, которые мы сможем извлечь из строки User-Agent.
После загрузки словарей мы можем задать пример значения заголовка User-Agent и протестировать новые возможности извлечения данных с их помощью:
Учитывая, что правила, связанные с user agent, будут редко меняться и словарь потребуется обновлять только при появлении новых браузеров, операционных систем и устройств, имеет смысл выполнять это извлечение на этапе вставки данных.
Мы можем выполнить эту работу либо с помощью материализованного столбца, либо с помощью материализованного представления. Ниже мы модифицируем использовавшееся ранее материализованное представление:
Для этого нам нужно изменить схему целевой таблицы otel_logs_v2:
После перезапуска коллектора и приёма структурированных логов на основе ранее описанных шагов мы можем выполнять запросы к только что извлечённым столбцам Device, Browser и Os.
Обратите внимание на использование кортежей для этих столбцов user agent. Кортежи рекомендуются для сложных структур, иерархия которых известна заранее. Подстолбцы обеспечивают ту же производительность, что и обычные столбцы (в отличие от ключей Map), при этом поддерживают неоднородные типы данных.
Дополнительные материалы
Дополнительные примеры и подробности о словарях вы найдете в следующих статьях:
Ускорение запросов
ClickHouse поддерживает ряд методов для ускорения выполнения запросов. К следующим подходам следует прибегать только после выбора подходящего первичного/сортировочного ключа, оптимизированного под наиболее распространённые шаблоны доступа и обеспечивающего максимальное сжатие. Обычно именно это даёт наибольший прирост производительности при наименьших затратах усилий.
Использование материализованных представлений (инкрементальных) для агрегаций
В предыдущих разделах мы рассмотрели использование материализованных представлений для преобразования и фильтрации данных. Однако материализованные представления также можно использовать для предварительного вычисления агрегаций во время вставки данных и сохранения результата. Этот результат может обновляться при последующих вставках, что фактически позволяет выполнять предварительное вычисление агрегации на этапе вставки.
Основная идея заключается в том, что результаты зачастую представляют собой более компактное представление исходных данных (приближённый эскиз в случае агрегаций). В сочетании с более простым запросом для чтения результатов из целевой таблицы время выполнения запросов будет меньше, чем если бы те же вычисления выполнялись над исходными данными.
Рассмотрим следующий запрос, в котором мы вычисляем общий объём трафика по часам, используя наши структурированные логи:
Мы можем представить, что это типичный линейный график, который пользователи строят в Grafana. Этот запрос, надо признать, очень быстрый — набор данных всего 10 млн строк, и ClickHouse быстр! Однако, если мы масштабируем объём данных до миллиардов и триллионов строк, нам желательно сохранить такую производительность запросов.
Этот запрос был бы в 10 раз быстрее, если бы мы использовали таблицу otel_logs_v2, которая является результатом нашего ранее созданного материализованного представления, извлекающего ключ size из карты LogAttributes. Здесь мы используем «сырые» данные только в иллюстративных целях и рекомендуем использовать это представление, если такой запрос является типовым.
Нам нужна таблица для приёма результатов, если мы хотим выполнять такие вычисления во время вставки с использованием материализованного представления. Эта таблица должна хранить только по одной строке в час. Если для уже существующего часа получено обновление, остальные столбцы должны быть объединены со строкой этого часа. Чтобы произошло такое слияние инкрементальных состояний, частичные состояния для остальных столбцов должны быть сохранены.
Для этого требуется специальный тип движка в ClickHouse: SummingMergeTree. Он заменяет все строки с одинаковым ключом сортировки одной строкой, содержащей суммарные значения для числовых столбцов. Следующая таблица будет объединять любые строки с одинаковой датой, суммируя все числовые столбцы.
Чтобы продемонстрировать наше материализованное представление, предположим, что таблица bytes_per_hour пуста и пока не содержит никаких данных. Наше материализованное представление применяет приведенный выше запрос SELECT к данным, вставляемым в otel_logs (это выполняется по блокам заданного размера), а результаты записываются в bytes_per_hour. Синтаксис показан ниже:
Оператор TO здесь является ключевым — он указывает, куда будут отправляться результаты, то есть в bytes_per_hour.
Если мы перезапустим наш OTel collector и повторно отправим логи, таблица bytes_per_hour будет постепенно заполняться результатами приведённого выше запроса. По завершении мы можем проверить размер нашей bytes_per_hour — у нас должна быть по одной строке на каждый час:
Мы фактически сократили количество строк здесь с 10 млн (в otel_logs) до 113, сохранив результат нашего запроса. Важно, что если в таблицу otel_logs вставляются новые логи, новые значения будут отправлены в bytes_per_hour для соответствующего часа, где они будут автоматически асинхронно объединяться в фоновом режиме — за счёт хранения только одной строки в час bytes_per_hour таким образом всегда будет и небольшой, и актуальной.
Поскольку объединение строк выполняется асинхронно, при выполнении запроса пользователем может существовать более одной строки на час. Чтобы гарантировать, что все необъединённые строки будут объединены во время выполнения запроса, у нас есть два варианта:
- Использовать модификатор
FINALв запросе к таблице (что мы сделали для запроса подсчёта выше). - Агрегировать по ключу сортировки, используемому в нашей итоговой таблице, т.е. по
Timestamp, и суммировать метрики.
Как правило, второй вариант более эффективен и гибок (таблицу можно использовать и для других целей), но первый может быть проще для некоторых запросов. Ниже показаны оба варианта:
Это ускорило выполнение нашего запроса с 0,6 с до 0,008 с — более чем в 75 раз!
Выигрыш может быть ещё больше на больших наборах данных с более сложными запросами. Примеры см. здесь.
Более сложный пример
Приведённый выше пример агрегирует простое количество в час, используя SummingMergeTree. Статистика, выходящая за рамки простых сумм, требует другого движка целевой таблицы: AggregatingMergeTree.
Предположим, мы хотим вычислить количество уникальных IP-адресов (или уникальных пользователей) в день. Запрос для этого:
Для сохранения счетчика кардинальности при инкрементальном обновлении требуется использование движка AggregatingMergeTree.
Чтобы ClickHouse знал, что будут храниться состояния агрегатных функций, мы определяем столбец UniqueUsers как тип AggregateFunction, указывая агрегатную функцию, чьи частичные состояния сохраняются (uniq), и тип исходного столбца (IPv4). Как и в SummingMergeTree, строки с одинаковым значением ключа ORDER BY будут объединяться (Hour в примере выше).
Соответствующее материализованное представление использует ранее приведённый запрос:
Обратите внимание, что мы добавляем суффикс State к нашим агрегатным функциям. Это гарантирует, что будет возвращено состояние агрегатной функции, а не окончательный результат. Оно будет содержать дополнительную информацию, позволяющую объединять это частичное состояние с другими состояниями.
После того как данные были перезагружены путем перезапуска коллектора, мы можем убедиться, что в таблице unique_visitors_per_hour доступны 113 строк.
В итоговом запросе нужно использовать суффикс Merge для функций (поскольку столбцы хранят состояния частичной агрегации):
Обратите внимание, что здесь мы используем GROUP BY вместо FINAL.
Использование материализованных представлений (инкрементальных) для быстрых выборок
Пользователям следует учитывать свои шаблоны доступа при выборе ключа сортировки ClickHouse — включать в него столбцы, которые часто используются в условиях фильтрации и агрегации. Это может быть ограничивающим фактором в сценариях наблюдаемости, где у пользователей более разнообразные шаблоны доступа, которые невозможно выразить одним набором столбцов. Лучше всего это иллюстрируется на примере, встроенном в стандартные схемы OTel. Рассмотрим схему по умолчанию для трассировок:
Эта схема оптимизирована для фильтрации по ServiceName, SpanName и Timestamp. В трассировке пользователям также требуется возможность выполнять поиск по конкретному TraceId и получать спаны, относящиеся к соответствующему трейсу. Хотя это поле присутствует в ключе сортировки, его положение в конце означает, что фильтрация будет не такой эффективной и, вероятно, приведёт к необходимости сканировать значительные объёмы данных при получении одного трейса.
OTel collector также устанавливает материализованное представление и связанную таблицу для решения этой задачи. Таблица и представление показаны ниже:
Представление по сути гарантирует, что таблица otel_traces_trace_id_ts содержит минимальную и максимальную метку времени для каждого трейса. Эта таблица, упорядоченная по TraceId, позволяет эффективно извлекать эти метки времени. В свою очередь, эти диапазоны меток времени могут использоваться при выполнении запросов к основной таблице otel_traces. Конкретнее, при получении трейса по его идентификатору Grafana использует следующий запрос:
Здесь CTE определяет минимальное и максимальное значения временной метки для идентификатора трейса ae9226c78d1d360601e6383928e4d22d, после чего эти значения используются для фильтрации основной таблицы otel_traces по соответствующим спанам.
Тот же подход можно применить для похожих паттернов доступа. Аналогичный пример по моделированию данных разбирается здесь.
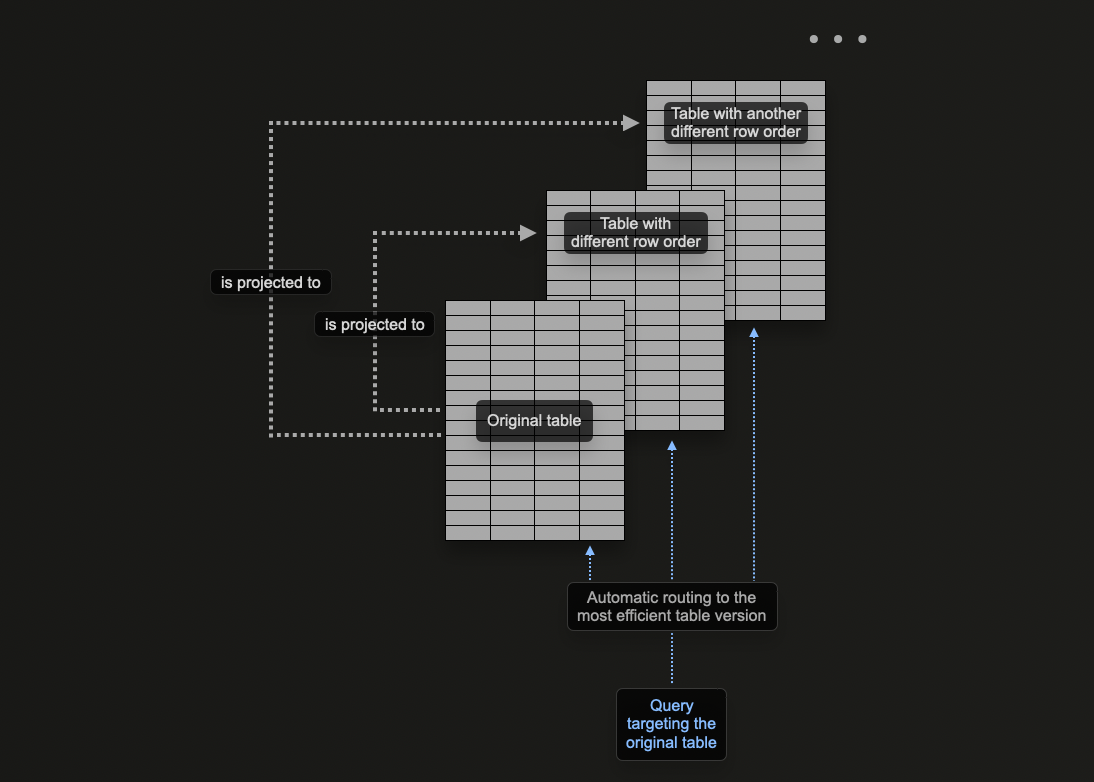
Использование проекций
Проекции ClickHouse позволяют указать несколько предложений ORDER BY для таблицы.
В предыдущих разделах мы рассмотрели, как материализованные представления могут использоваться в ClickHouse для предварительного вычисления агрегаций, преобразования строк и оптимизации запросов наблюдаемости для различных паттернов доступа.
Мы предоставили пример, в котором материализованное представление отправляет строки в целевую таблицу с ключом сортировки, отличающимся от ключа исходной таблицы, принимающей вставки, чтобы оптимизировать поиск по идентификатору трассировки.
Проекции можно использовать для решения той же задачи, что позволяет оптимизировать запросы по столбцам, не входящим в первичный ключ.
Теоретически эту возможность можно использовать для создания нескольких ключей сортировки для таблицы, однако у неё есть существенный недостаток: дублирование данных. Данные потребуется записывать как в порядке основного первичного ключа, так и в порядке, заданном для каждой проекции. Это замедлит операции вставки и увеличит потребление дискового пространства.
Проекции предоставляют многие из тех же возможностей, что и материализованные представления, однако их следует применять с осторожностью — в большинстве случаев предпочтительнее использовать материализованные представления. Необходимо понимать ограничения проекций и сценарии их корректного применения. Например, хотя проекции можно использовать для предварительного вычисления агрегаций, мы рекомендуем применять для этого материализованные представления.
Рассмотрим следующий запрос, который фильтрует таблицу otel_logs_v2 по кодам ошибок 500. Это типичный сценарий доступа при работе с логами, когда пользователи хотят отфильтровать записи по кодам ошибок:
Здесь мы не выводим результаты, используя FORMAT Null. Это принудительно читает все результаты без их возврата, предотвращая досрочное завершение запроса из-за LIMIT. Это необходимо только для того, чтобы показать время, затраченное на сканирование всех 10 млн строк.
Приведенный выше запрос требует линейного сканирования при использовании выбранного нами ключа сортировки (ServiceName, Timestamp). Хотя мы могли бы добавить Status в конец ключа сортировки для улучшения производительности этого запроса, альтернативным решением является добавление проекции.
Обратите внимание, что сначала необходимо создать проекцию, а затем материализовать её. Эта команда приводит к двойному сохранению данных на диске в двух различных порядках сортировки. Проекцию также можно определить при создании таблицы, как показано ниже, и она будет автоматически поддерживаться при вставке данных.
Важно: если проекция создается через ALTER, то при выполнении команды MATERIALIZE PROJECTION её создание происходит асинхронно. Пользователи могут отслеживать ход выполнения этой операции следующим запросом, ожидая is_done=1.
Если повторить указанный выше запрос, можно увидеть, что производительность значительно улучшилась за счёт дополнительного использования хранилища (см. "Измерение размера таблицы и сжатия").
В приведённом выше примере мы указываем в проекции столбцы, использованные в предыдущем запросе. Это означает, что только эти столбцы будут храниться на диске как часть проекции и будут упорядочены по Status. Если бы мы вместо этого использовали здесь SELECT *, сохранялись бы все столбцы. Хотя это позволило бы большему числу запросов (использующих любые подмножества столбцов) воспользоваться проекцией, потребовалось бы дополнительное дисковое пространство. Для измерения занимаемого дискового пространства и степени сжатия см. "Measuring table size & compression".
Вторичные индексы / индексы пропуска данных
Независимо от того, насколько хорошо настроен первичный ключ в ClickHouse, некоторые запросы неизбежно будут требовать полного сканирования таблицы. Хотя необходимость таких сканирований можно снизить с помощью материализованных представлений (и проекций для некоторых запросов), они требуют дополнительного обслуживания, а пользователи должны знать об их наличии, чтобы эффективно их использовать. В то время как традиционные реляционные базы данных решают эту задачу с помощью вторичных индексов, в колоночных базах данных, таких как ClickHouse, они неэффективны. Вместо этого ClickHouse использует индексы пропуска данных (skip indexes), которые могут существенно повысить производительность запросов, позволяя базе данных пропускать крупные блоки данных без подходящих значений.
Стандартные схемы OTel используют вторичные индексы в попытке ускорить доступ к значениям в map-полях. Хотя на практике мы считаем их в целом неэффективными и не рекомендуем копировать их в вашу собственную схему, индексы пропуска данных по‑прежнему могут быть полезны.
Перед тем как пытаться их применять, пользователям следует прочитать и понять руководство по индексам пропуска данных.
В целом они эффективны, когда существует сильная корреляция между первичным ключом и целевым непервичным столбцом/выражением, а пользователи выполняют поиск по редким значениям, то есть по тем, которые не встречаются во многих гранулах.
Фильтры Блума для текстового поиска
Для запросов наблюдаемости вторичные индексы могут быть полезны, когда требуется выполнять текстовый поиск. В частности, индексы фильтров Блума на основе n-грамм и токенов ngrambf_v1 и tokenbf_v1 можно использовать для ускорения поиска по столбцам типа String с операторами LIKE, IN и hasToken. Важно отметить, что индекс на основе токенов генерирует токены, используя неалфавитно-цифровые символы в качестве разделителей. Это означает, что во время выполнения запроса могут быть найдены только токены (или целые слова). Для более детального поиска можно использовать фильтр Блума на основе N-грамм. Он разбивает строки на n-граммы указанного размера, что позволяет выполнять поиск по частям слов.
Для оценки токенов, которые будут созданы и сопоставлены, используйте функцию tokens:
Функция ngram предоставляет аналогичные возможности, при этом размер ngram можно указать вторым параметром:
ClickHouse также имеет экспериментальную поддержку инвертированных индексов в качестве вторичного индекса. В настоящее время мы не рекомендуем их использовать для логов, но ожидаем, что они заменят bloom-фильтры на основе токенов после выхода в production.
В данном примере используется набор данных структурированных логов. Предположим, требуется подсчитать логи, где столбец Referer содержит ultra.
Здесь необходимо выполнить сопоставление с размером n-граммы, равным 3. Поэтому создаём индекс ngrambf_v1.
Индекс ngrambf_v1(3, 10000, 3, 7) принимает четыре параметра. Последний из них (значение 7) представляет собой начальное значение (seed). Остальные параметры представляют размер n-граммы (3), значение m (размер фильтра) и количество хеш-функций k (7). Параметры k и m требуют настройки и зависят от количества уникальных n-грамм/токенов и вероятности того, что фильтр вернёт истинно отрицательный результат, тем самым подтверждая отсутствие значения в грануле. Рекомендуем использовать эти функции для определения этих значений.
Если всё настроено должным образом, прирост производительности может быть существенным:
Приведённый выше пример служит исключительно для иллюстрации. Мы рекомендуем пользователям извлекать структуру из логов на этапе вставки, а не пытаться оптимизировать текстовый поиск с помощью блум‑фильтров на основе токенов. Однако существуют случаи, когда у пользователей есть трассировки стека или другие большие строки, для которых текстовый поиск может быть полезен из‑за менее детерминированной структуры.
Некоторые общие рекомендации по использованию блум‑фильтров:
Цель блум‑фильтра — отфильтровывать гранулы, избегая необходимости загружать все значения столбца и выполнять линейное сканирование. Оператор EXPLAIN с параметром indexes=1 можно использовать для определения количества гранул, которые были пропущены. Рассмотрите приведённые ниже ответы для исходной таблицы otel_logs_v2 и таблицы otel_logs_bloom с блум‑фильтром ngram.
Фильтр Блума обычно будет быстрее только в том случае, если он меньше самого столбца. Если он больше, выигрыш в производительности, скорее всего, будет незначительным. Сравните размер фильтра с размером столбца, используя следующие запросы:
В приведённых выше примерах мы видим, что вторичный индекс блум-фильтра имеет размер 12 МБ — почти в 5 раз меньше сжатого размера самого столбца, равного 56 МБ.
Блум-фильтры могут требовать значительной настройки. Мы рекомендуем следовать примечаниям здесь, которые помогут подобрать оптимальные параметры. Блум-фильтры также могут быть ресурсоёмкими при вставке и слиянии данных. Перед добавлением блум-фильтров в продуктивную среду рекомендуется оценить влияние на производительность вставки.
Дополнительные сведения о вторичных пропускающих индексах можно найти здесь.
Извлечение из типов Map
Тип Map широко используется в схемах OTel. Для этого типа требуется, чтобы значения и ключи имели один и тот же тип — этого достаточно для метаданных, таких как метки Kubernetes. Имейте в виду, что при запросе подключа типа Map загружается весь родительский столбец. Если Map содержит много ключей, это может привести к существенному снижению производительности запроса, поскольку с диска нужно прочитать больше данных, чем если бы ключ существовал как отдельный столбец.
Если вы часто запрашиваете определённый ключ, рассмотрите возможность вынести его в отдельный столбец верхнего уровня. Обычно это делается в ответ на распространённые шаблоны доступа и уже после развертывания, и может быть сложно предсказать это до выхода в продакшн. См. раздел "Управление изменениями схемы" о том, как изменять схему после развертывания.
Измерение размера таблицы и степени сжатия
Одна из основных причин, по которой ClickHouse используют для задач наблюдаемости (Observability), — это сжатие.
Помимо значительного сокращения затрат на хранение, меньшее количество данных на диске означает меньше операций ввода-вывода (I/O) и более быстрые запросы и вставки. Снижение объёма I/O перевешивает накладные расходы любого алгоритма сжатия с точки зрения нагрузки на CPU. Поэтому улучшение сжатия данных должно быть первой задачей при обеспечении высокой скорости выполнения запросов в ClickHouse.
Подробности об измерении степени сжатия можно найти здесь.
