Как ClickHouse выполняет запросы параллельно
ClickHouse создан для высокой скорости. Он выполняет запросы в высокопараллельном режиме, используя все доступные ядра CPU, распределяя данные по потокам обработки и часто подводя оборудование к пределам его возможностей.
В этом руководстве рассматривается, как устроен параллелизм выполнения запросов в ClickHouse и как вы можете настраивать или отслеживать его, чтобы повысить производительность при больших нагрузках.
Для иллюстрации ключевых концепций мы используем агрегирующий запрос к набору данных uk_price_paid_simple.
Пошагово: как ClickHouse параллелизует агрегирующий запрос
Когда ClickHouse ① выполняет агрегирующий запрос с фильтром по первичному ключу таблицы, он ② загружает первичный индекс в память, чтобы ③ определить, какие гранулы нужно обработать, а какие можно безопасно пропустить:
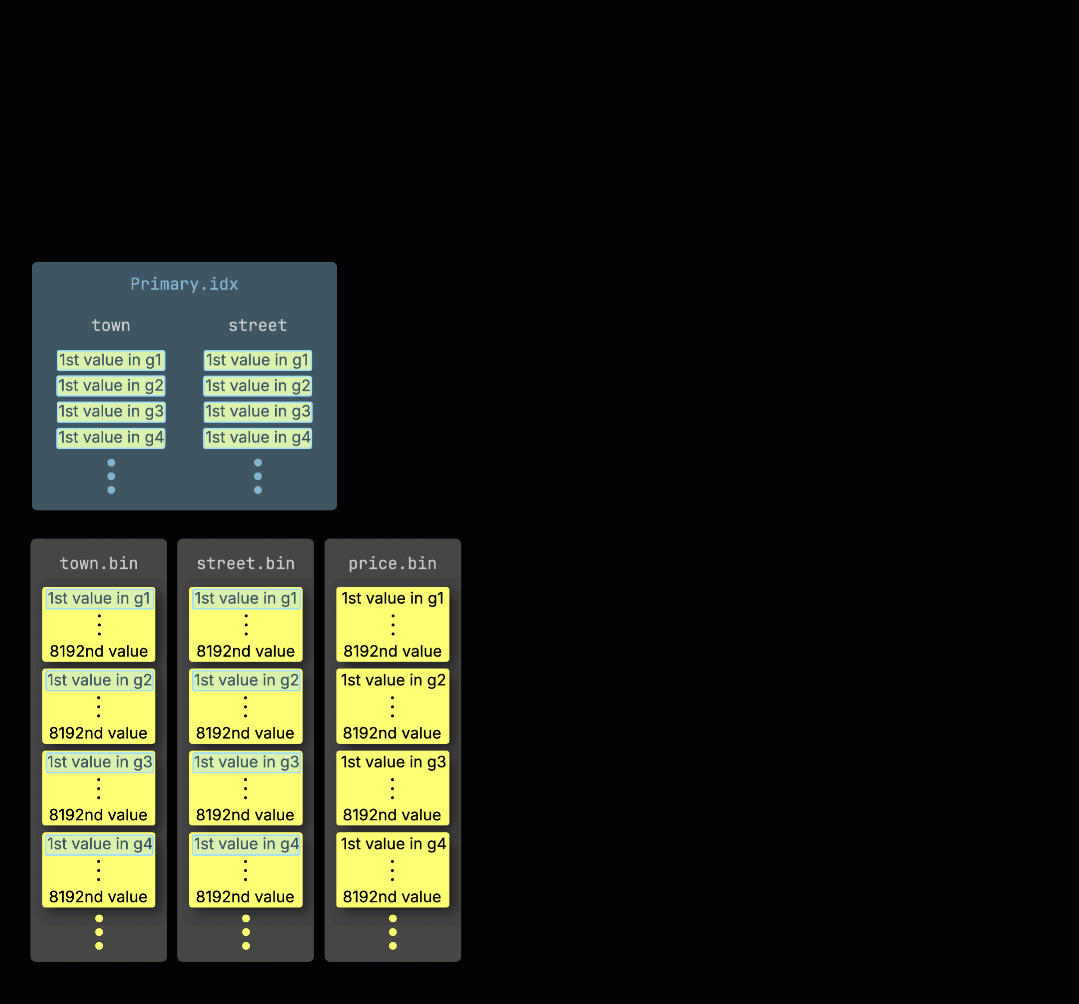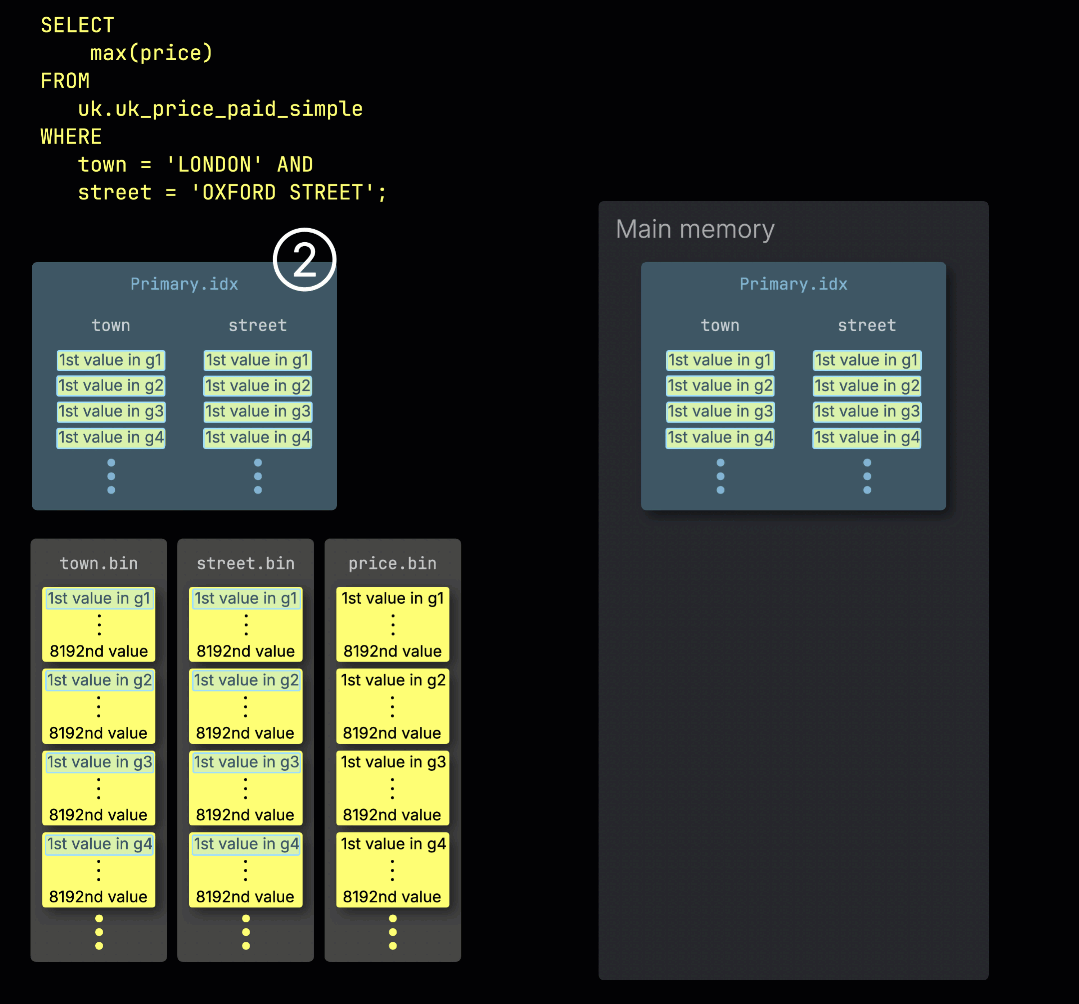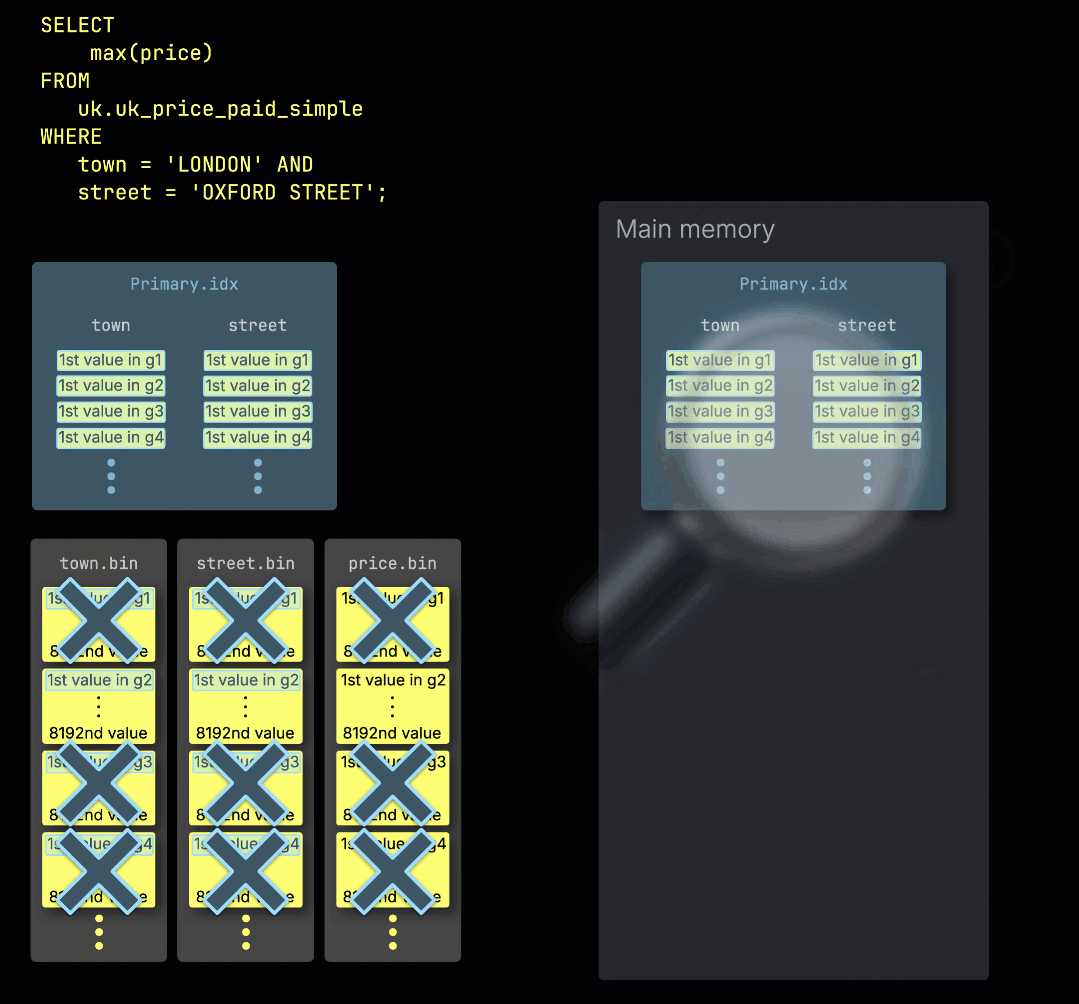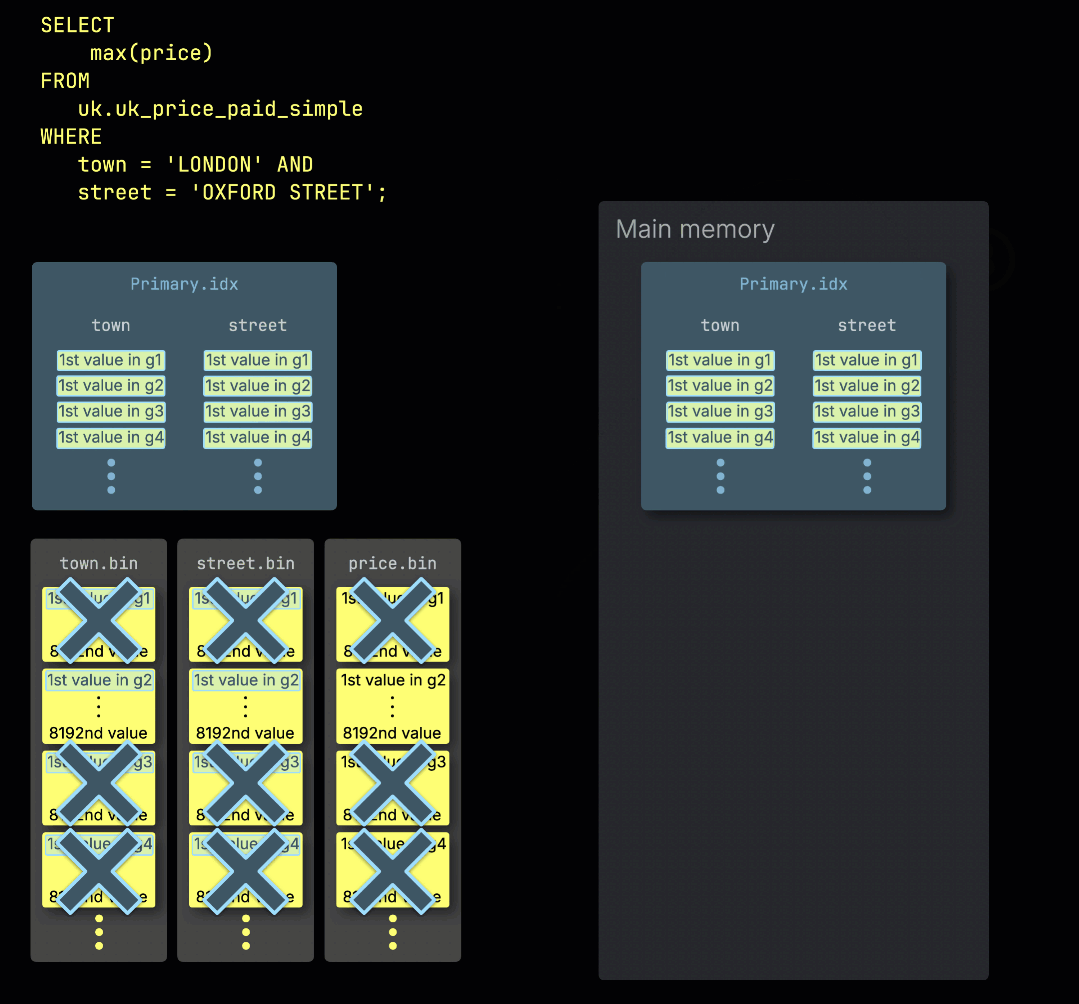
Распределение работы по линиям обработки
Затем выбранные данные динамически распределяются по n параллельным линиям обработки, которые потоково читают и обрабатывают данные блок за блоком, формируя итоговый результат:
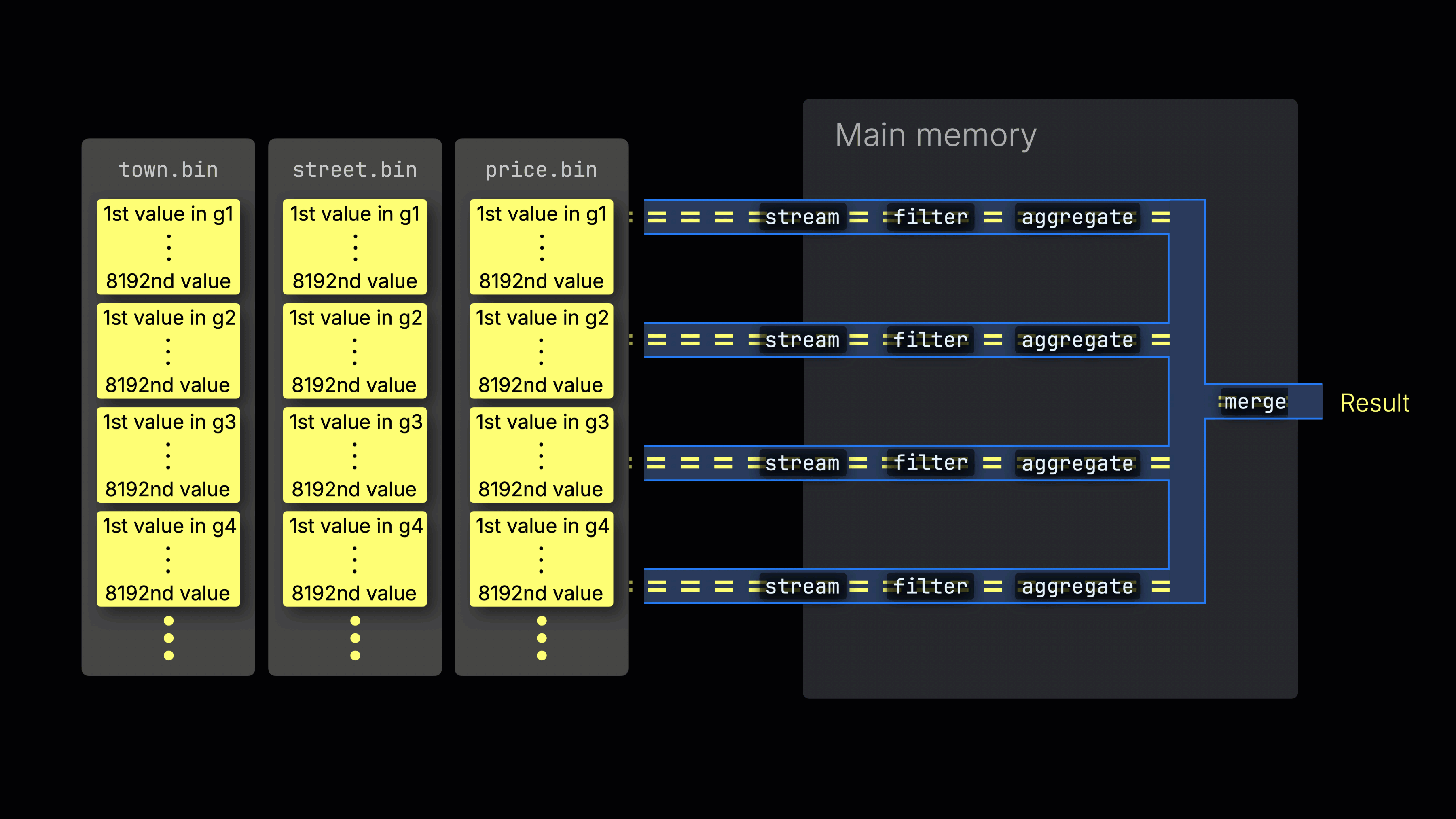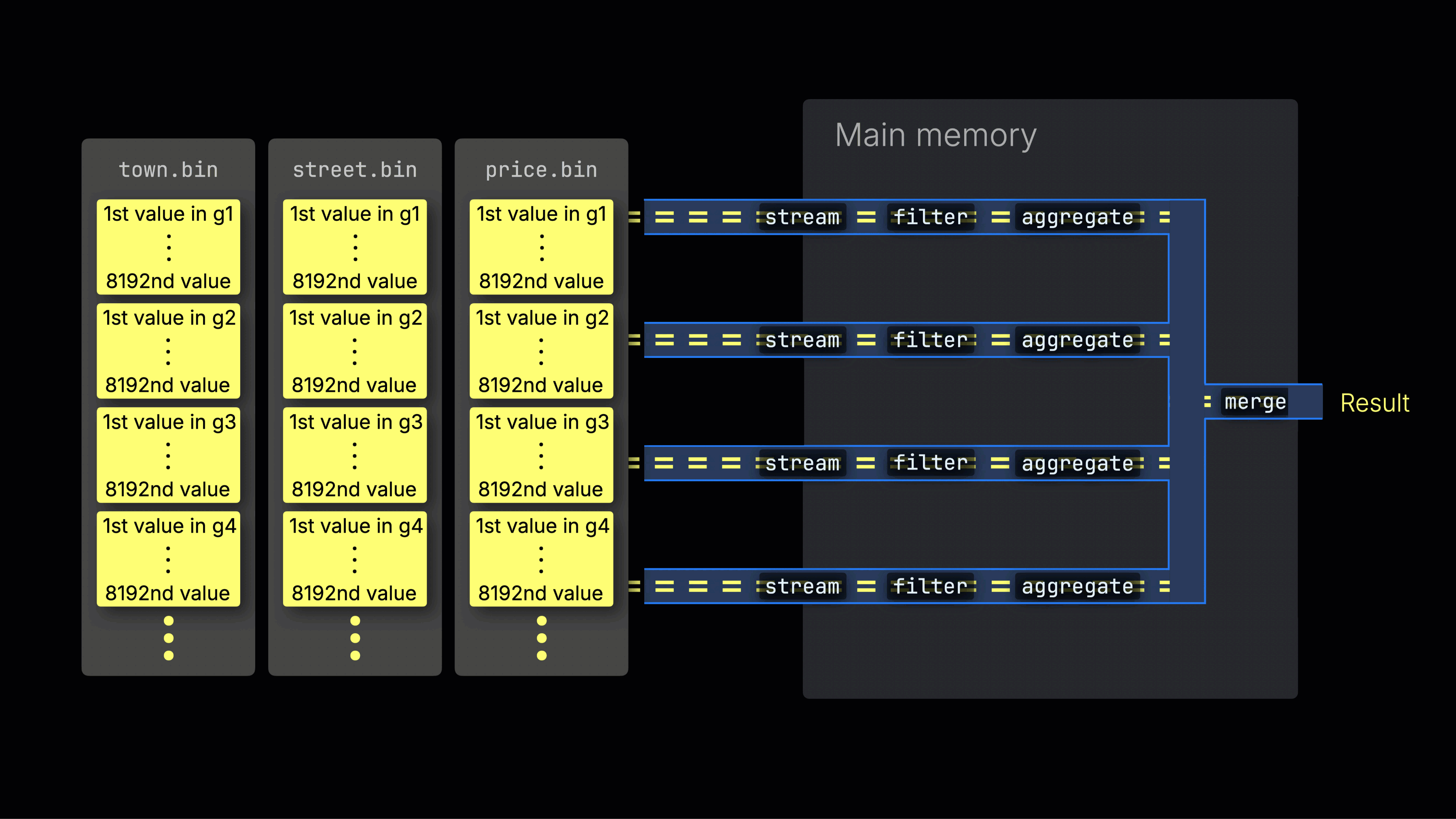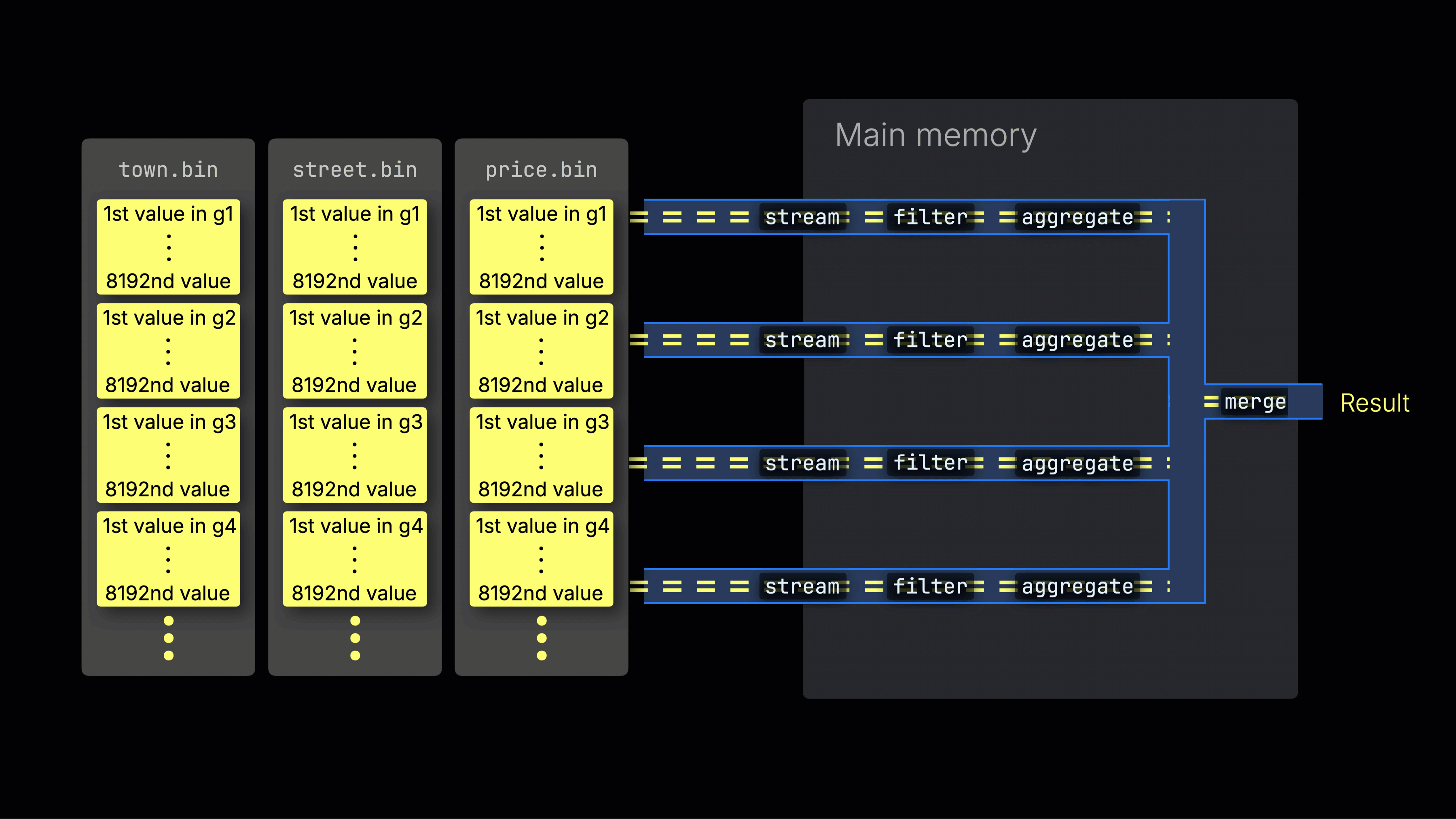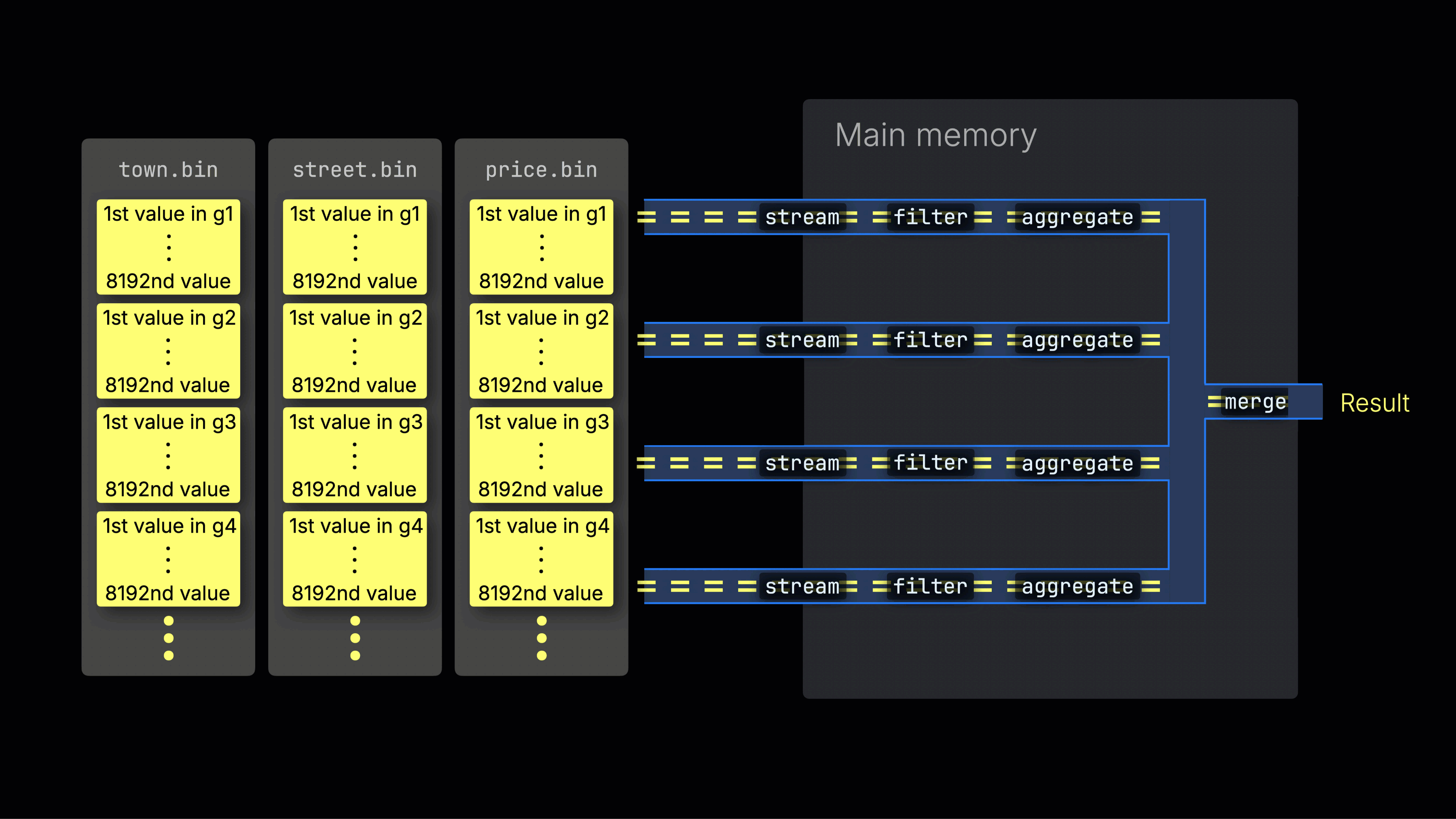
Количество n параллельных линий обработки контролируется настройкой max_threads, которая по умолчанию соответствует числу ядер CPU, доступных ClickHouse на сервере. В примере выше предполагается наличие 4 ядер.
На машине с 8 ядрами пропускная способность обработки запросов примерно удвоится (но использование памяти соответственно возрастет), так как больше линий обрабатывают данные параллельно:
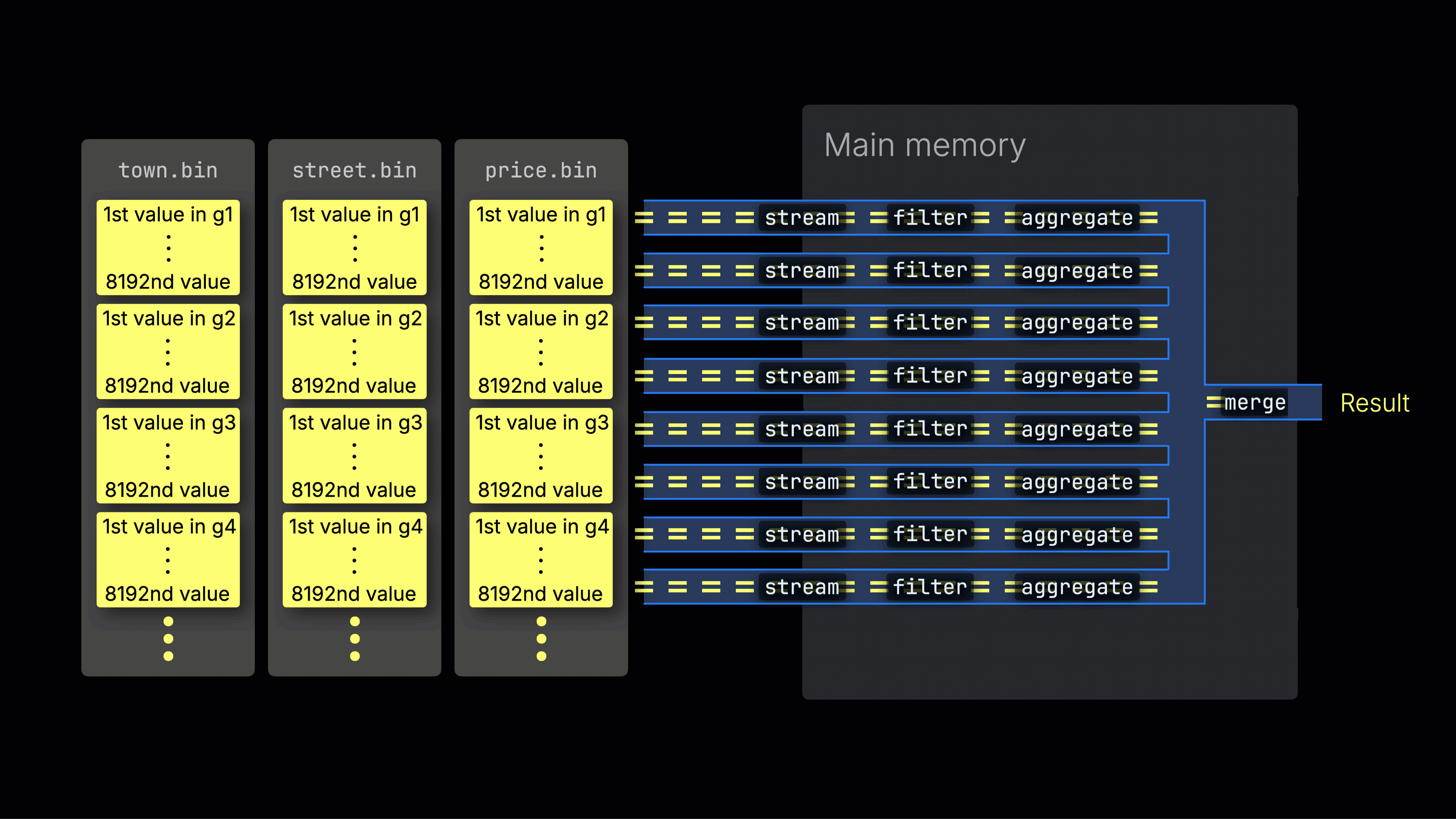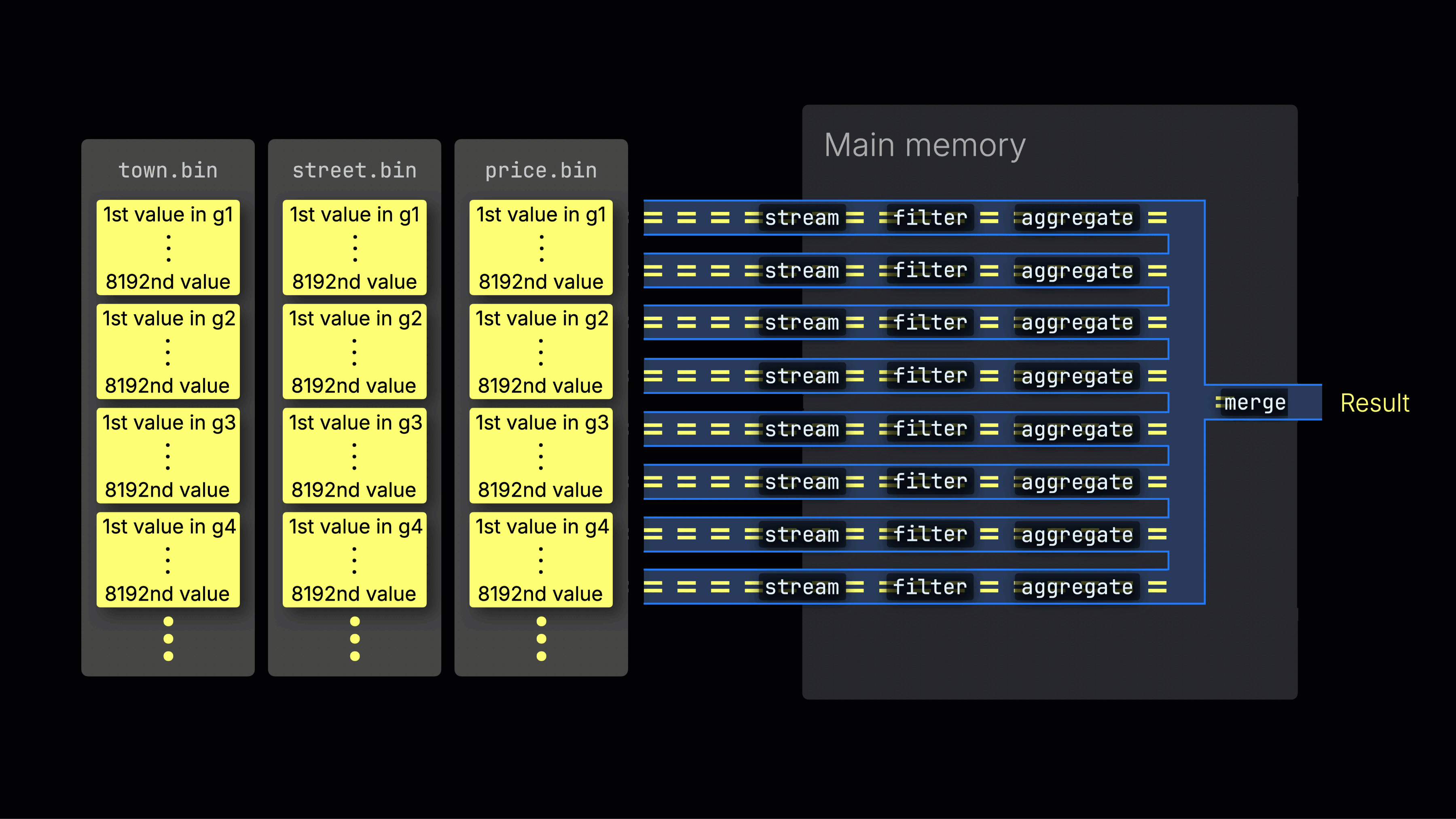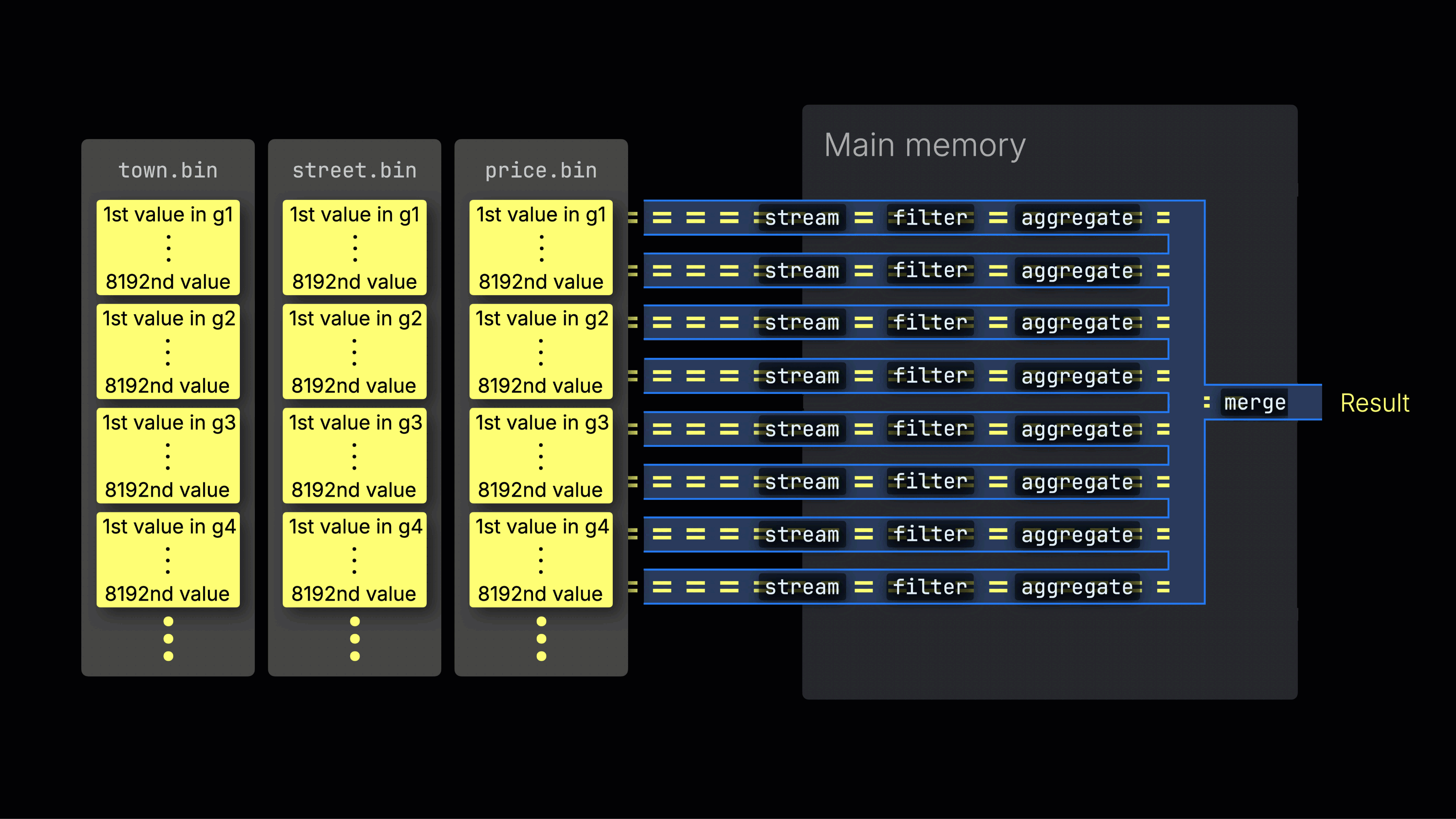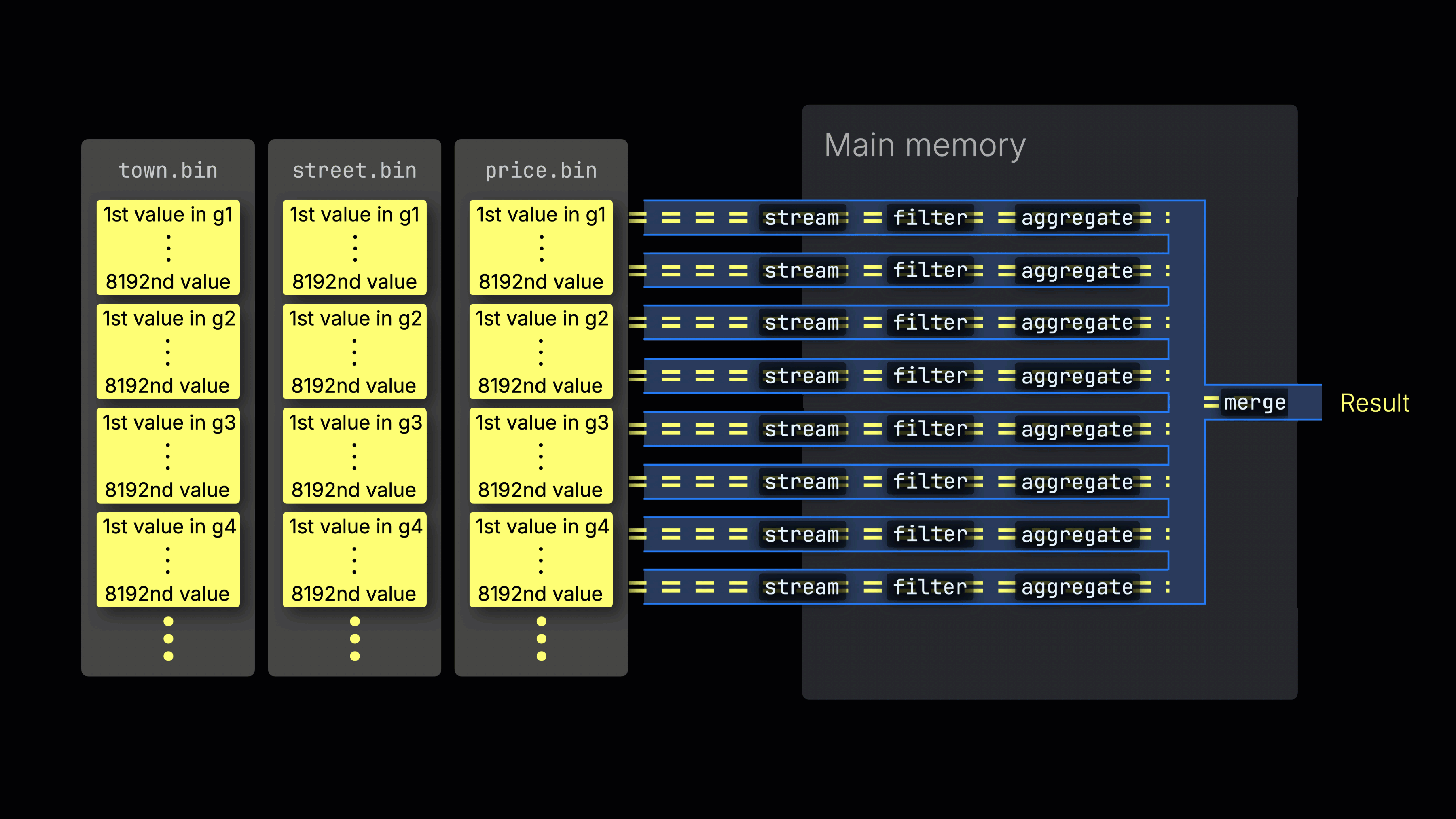
Эффективное распределение по линиям является ключом к максимизации загрузки CPU и сокращению общего времени выполнения запроса.
Обработка запросов на шардированных таблицах
Когда данные таблицы распределены по нескольким серверам в виде шардов, каждый сервер обрабатывает свой шард параллельно. На каждом сервере локальные данные обрабатываются с использованием параллельных линий обработки так же, как описано выше:
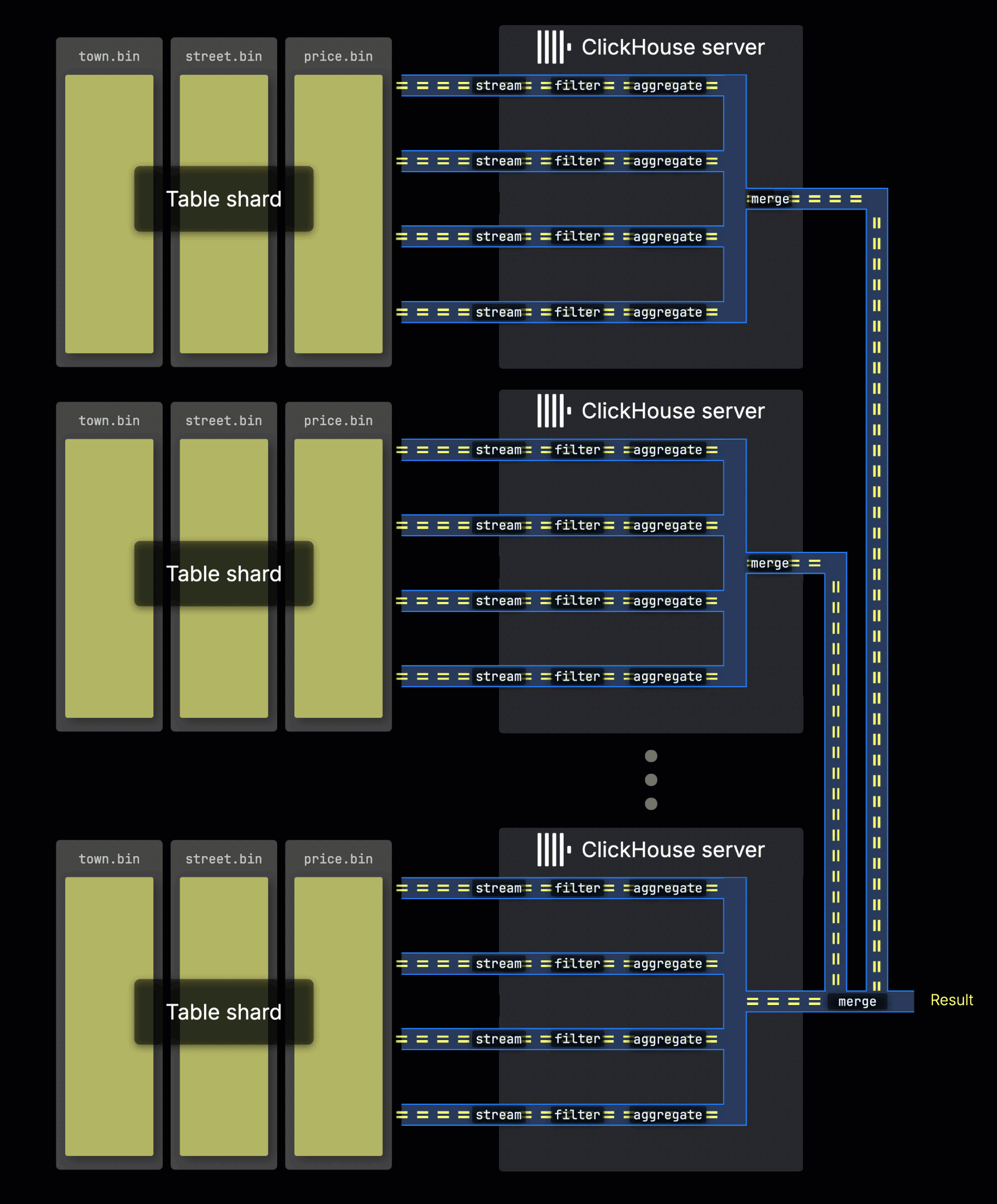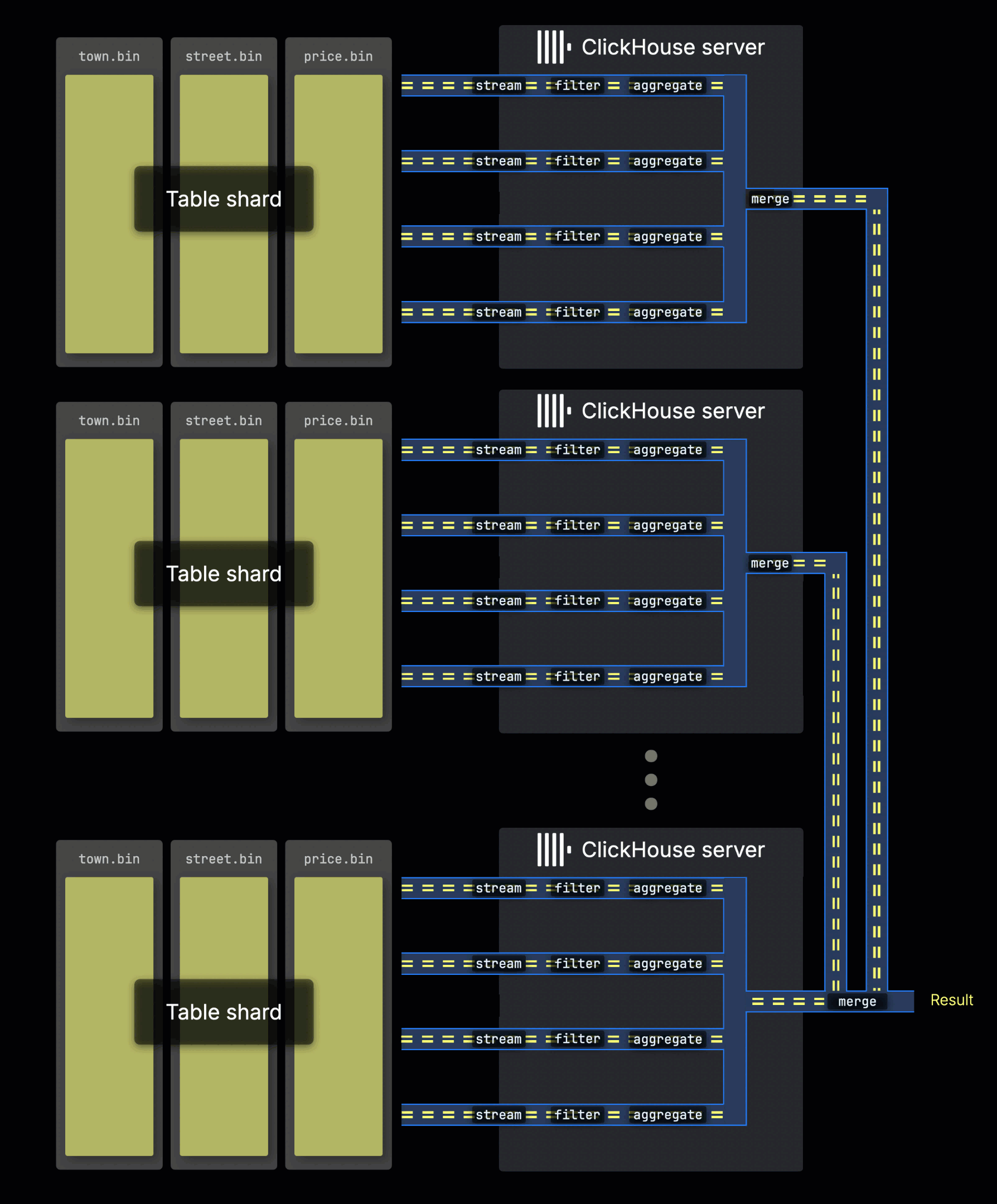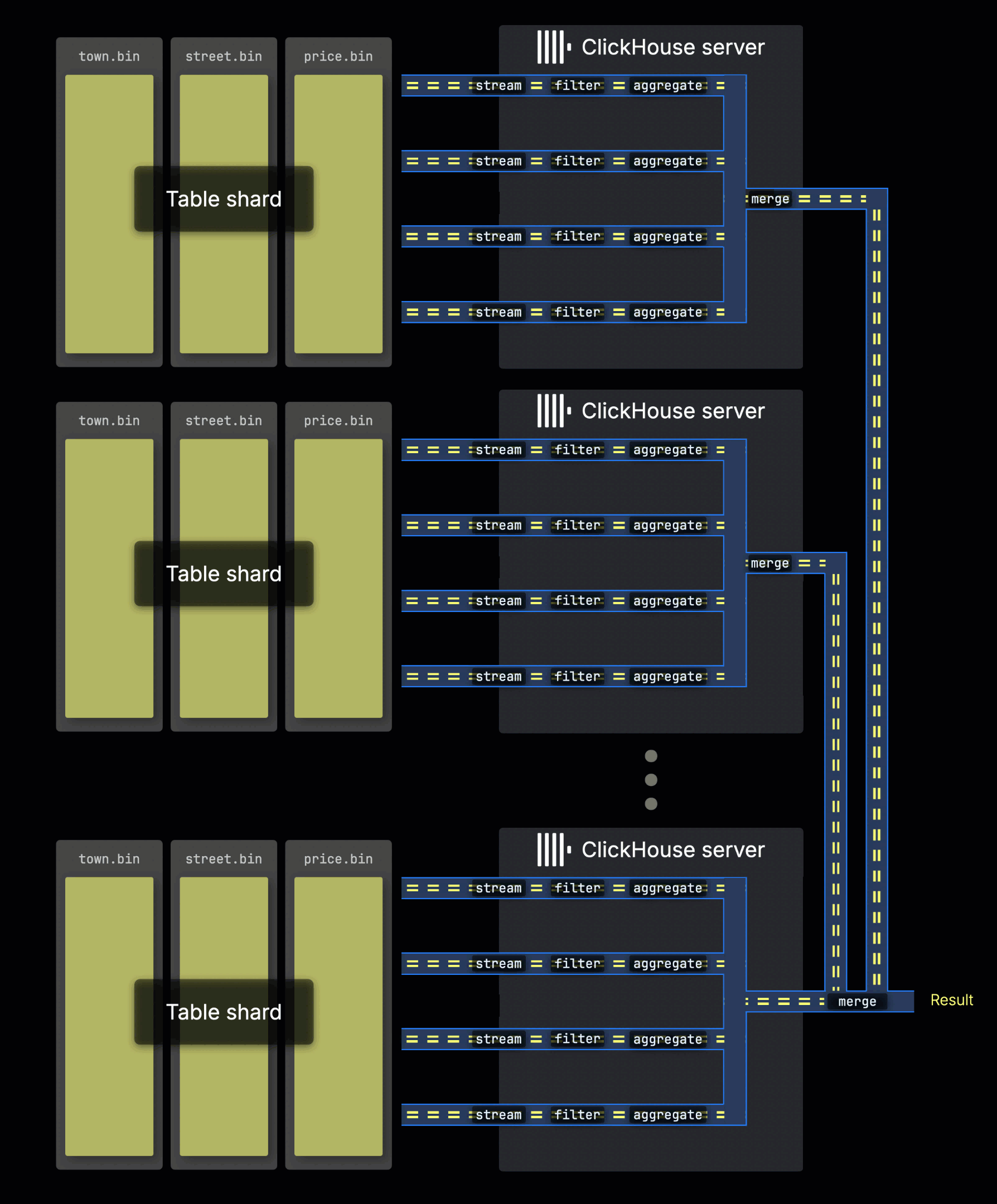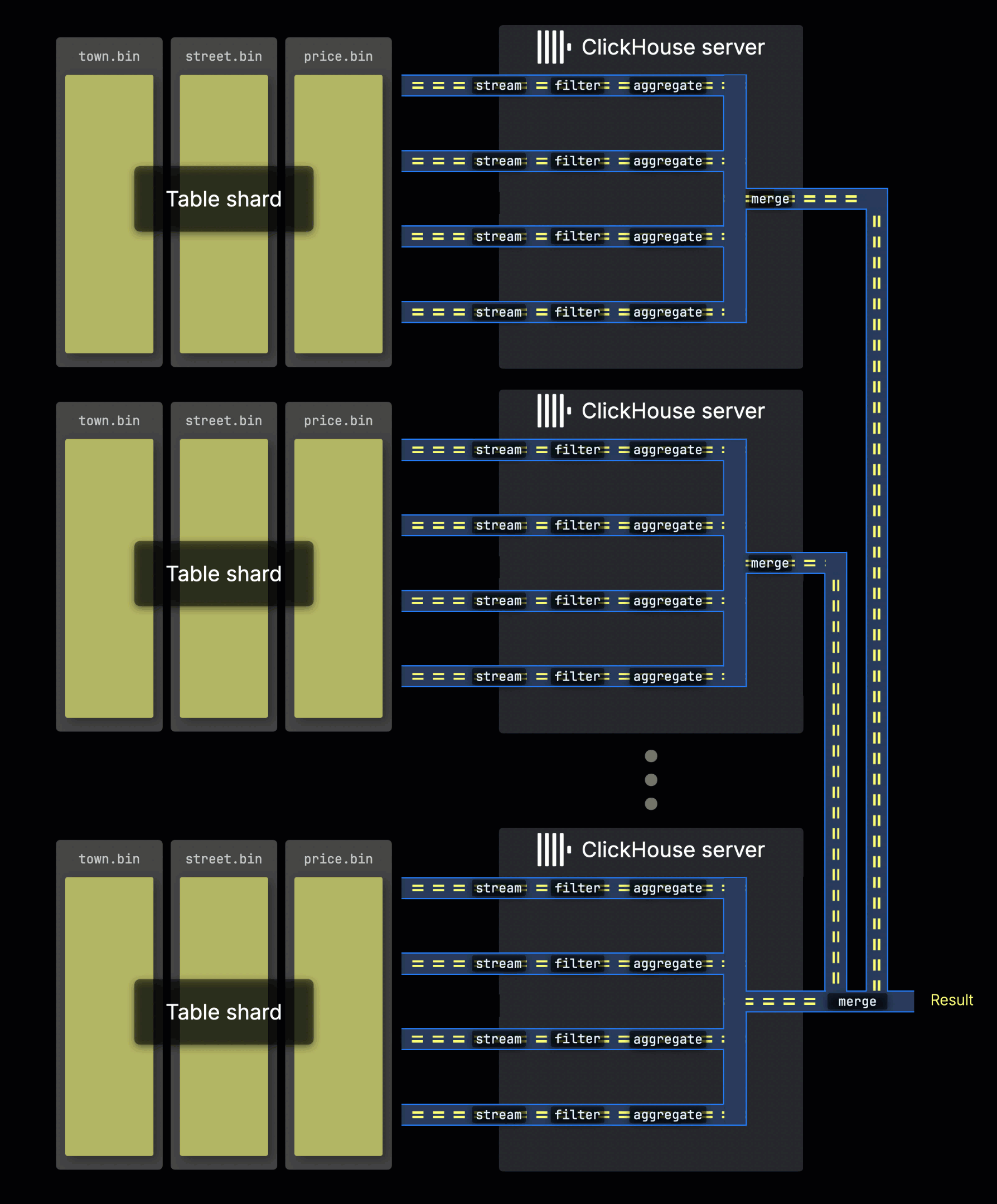
Сервер, который изначально получает запрос, собирает все частичные результаты с шардов и объединяет их в итоговый глобальный результат.
Распределение нагрузки запросов по шардам позволяет горизонтально масштабировать параллелизм, особенно в средах с высокой пропускной способностью.
В ClickHouse Cloud тот же параллелизм достигается с помощью параллельных реплик, которые работают аналогично шардам в кластерах с архитектурой shared-nothing. Каждая реплика ClickHouse Cloud — вычислительный узел без сохранения состояния — обрабатывает часть данных параллельно и вносит вклад в итоговый результат, так же как это делал бы независимый шард.
Мониторинг параллелизма запросов
Используйте эти инструменты, чтобы убедиться, что ваш запрос полностью задействует доступные ресурсы CPU и диагностировать случаи, когда это не так.
Мы выполняем это на тестовом сервере с 59 ядрами CPU, что позволяет ClickHouse в полной мере продемонстрировать параллелизм выполнения запросов.
Чтобы увидеть, как выполняется пример запроса, мы можем настроить сервер ClickHouse так, чтобы он возвращал все записи журнала уровня trace во время агрегирующего запроса. Для этой демонстрации мы убрали условие в запросе — в противном случае было бы обработано только 3 гранулы, чего недостаточно, чтобы ClickHouse смог задействовать более чем несколько параллельных потоков обработки:
Мы видим, что
- ① ClickHouse нужно прочитать 3 609 гранул (обозначенных как «marks» в журналах трассировки) в пределах 3 диапазонов данных.
- ② Имея 59 ядер CPU, он распределяет эту работу между 59 параллельными потоками обработки — по одному на каждую линию.
В качестве альтернативы мы можем использовать оператор EXPLAIN, чтобы изучить план физических операторов — также известный как «конвейер запроса» — для агрегирующего запроса:
Примечание: читайте план операторов выше снизу вверх. Каждая строка представляет собой стадию физического плана выполнения, начиная с чтения данных из хранилища внизу и заканчивая финальными этапами обработки вверху. Операторы, помеченные × 59, выполняются параллельно на непересекающихся диапазонах данных в 59 параллельных конвейерах обработки. Это отражает значение max_threads и показывает, как каждая стадия запроса распараллеливается по ядрам CPU.
Встроенный веб-интерфейс ClickHouse (доступен по эндпоинту /play) может отобразить приведённый выше физический план в виде графической визуализации. В этом примере мы установили max_threads равным 4, чтобы сделать визуализацию компактной, показывая только 4 параллельных конвейера обработки:

Примечание: читайте визуализацию слева направо. Каждая строка представляет параллельный конвейер обработки, который передаёт данные блок за блоком, применяя преобразования, такие как фильтрация, агрегация и финальные стадии обработки. В этом примере вы видите четыре параллельных конвейера, соответствующих настройке max_threads = 4.
Балансировка нагрузки между конвейерами обработки
Обратите внимание, что операторы Resize в физическом плане выше переразбивают на части и перераспределяют потоки блоков данных между конвейерами обработки, чтобы поддерживать их равномерную загрузку. Такое перебалансирование особенно важно, когда диапазоны данных различаются по количеству строк, удовлетворяющих предикатам запроса, иначе некоторые конвейеры могут быть перегружены, в то время как другие простаивают. Перераспределяя работу, более быстрые конвейеры фактически помогают более медленным, оптимизируя общее время выполнения запроса.
Почему max_threads не всегда соблюдается
Как отмечалось выше, количество параллельных потоков обработки n контролируется параметром max_threads, который по умолчанию равен числу ядер CPU, доступных ClickHouse на сервере:
Однако значение max_threads может игнорироваться в зависимости от объёма выбранных для обработки данных:
Как видно из приведённого выше фрагмента плана операторов, хотя значение max_threads установлено в 59, ClickHouse использует только 30 параллельных потоков для сканирования данных.
Теперь запустим запрос:
Как видно из вывода выше, запрос обработал 2,31 миллиона строк и прочитал 13,66 МБ данных. Это связано с тем, что на этапе анализа индекса ClickHouse выбрал для обработки 282 гранулы, каждая из которых содержит 8 192 строки, что в сумме дает приблизительно 2,31 миллиона строк:
Независимо от заданного значения max_threads, ClickHouse выделяет дополнительные параллельные конвейеры обработки только тогда, когда данных достаточно, чтобы это было оправдано. «Max» в max_threads означает верхний предел, а не гарантированное количество используемых потоков.
То, что считается «достаточным количеством данных», в первую очередь определяется двумя настройками, которые задают минимальное количество строк (163 840 по умолчанию) и минимальное количество байт (2 097 152 по умолчанию), обрабатываемых каждым конвейером:
Для кластеров с архитектурой shared-nothing:
Для кластеров с общей подсистемой хранения (shared storage), например ClickHouse Cloud:
- merge_tree_min_rows_for_concurrent_read_for_remote_filesystem
- merge_tree_min_bytes_for_concurrent_read_for_remote_filesystem
Кроме того, существует жёсткий нижний предел размера задачи чтения, который контролируется настройками:
Мы не рекомендуем изменять эти настройки в продакшене. Они приведены здесь только для того, чтобы показать, почему max_threads не всегда определяет фактический уровень параллелизма.
В демонстрационных целях давайте рассмотрим физический план с переопределёнными настройками, чтобы принудительно задать максимальный уровень параллелизма:
Теперь ClickHouse использует 59 одновременных потоков для сканирования данных, строго соблюдая значение параметра max_threads.
Это показывает, что для запросов к небольшим наборам данных ClickHouse намеренно ограничивает уровень параллелизма. Используйте переопределения настроек только для тестирования — не в продакшене, — поскольку они могут приводить к неэффективному выполнению или конфликтам за ресурсы.
Основные выводы
- ClickHouse параллелизует запросы с помощью линий обработки, количество которых привязано к
max_threads. - Фактическое число линий зависит от объёма данных, выбранных для обработки.
- Используйте
EXPLAIN PIPELINEи трассировочные логи для анализа использования линий.
Где найти дополнительную информацию
Если вы хотите глубже разобраться в том, как ClickHouse выполняет запросы параллельно и достигает высокой производительности при масштабировании, ознакомьтесь со следующими материалами:
-
Слой обработки запросов – статья VLDB 2024 (веб-версия) — подробный разбор внутренней модели исполнения ClickHouse, включая планирование, конвейерную обработку и конструирование операторов.
-
Состояния частичной агрегации: подробное объяснение — подробный технический разбор того, как состояния частичной агрегации обеспечивают эффективное параллельное выполнение по нескольким потокам обработки.
-
Видеоурок с подробным разбором всех шагов обработки запросов в ClickHouse:
