Инкрементное материализованное представление
Общие сведения
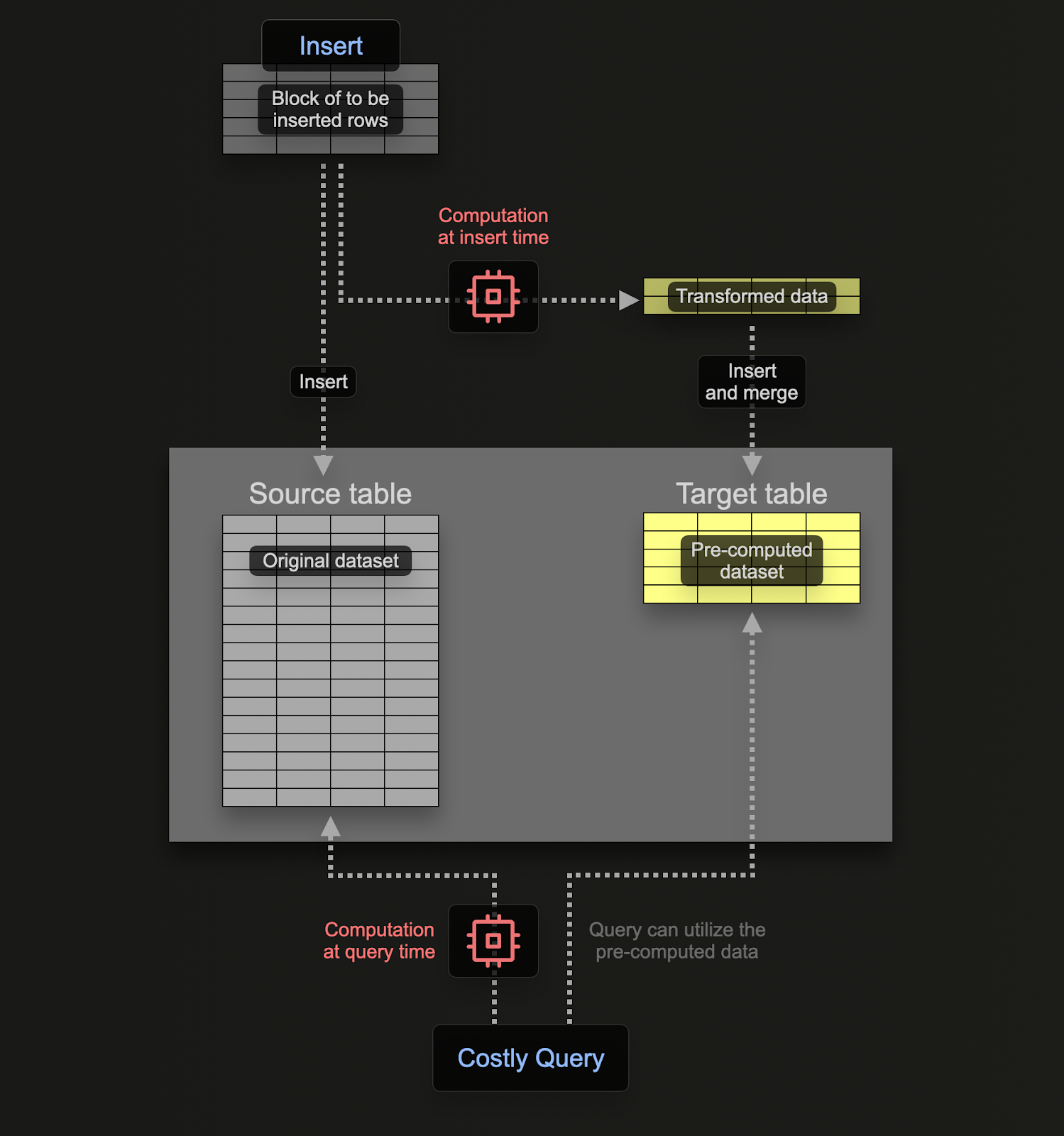
Инкрементальные материализованные представления (Materialized Views) позволяют перенести вычислительные затраты с момента выполнения запроса на момент вставки данных, что приводит к более быстрым запросам SELECT.
В отличие от транзакционных баз данных, таких как Postgres, материализованное представление в ClickHouse — это по сути триггер, который выполняет запрос над блоками данных по мере их вставки в таблицу. Результат этого запроса вставляется во вторую, «целевую» таблицу. При вставке новых строк результаты снова отправляются в целевую таблицу, где промежуточные результаты обновляются и объединяются. Этот объединённый результат эквивалентен выполнению запроса над всеми исходными данными.
Основная идея использования материализованных представлений заключается в том, что результаты, вставляемые в целевую таблицу, представляют собой результаты агрегации, фильтрации или трансформации строк. Эти результаты часто являются более компактным представлением исходных данных (частичным «эскизом» в случае агрегаций). Это, вместе с простотой итогового запроса для чтения результатов из целевой таблицы, обеспечивает более быстрое выполнение запросов по сравнению с выполнением тех же вычислений над исходными данными, перенося вычисления (и, следовательно, задержку запроса) с момента выполнения запроса на момент вставки.
Материализованные представления в ClickHouse обновляются в режиме реального времени по мере поступления данных в базовую таблицу, функционируя скорее как постоянно обновляемые индексы. В отличие от этого, в других базах данных материализованные представления обычно представляют собой статические снимки результата запроса, которые необходимо обновлять (аналогично ClickHouse обновляемым материализованным представлениям).
Пример
В качестве примера мы будем использовать датасет Stack Overflow, описанный в разделе "Проектирование схемы".
Предположим, что мы хотим получить количество голосов «за» и «против» по дням для записи.
Это довольно простой запрос в ClickHouse благодаря функции toStartOfDay:
Этот запрос уже выполняется быстро благодаря ClickHouse, но можно ли сделать ещё лучше?
Если мы хотим выполнять этот расчёт на момент вставки с использованием материализованного представления, нам нужна таблица, которая будет принимать результаты. Эта таблица должна содержать только одну строку на каждый день. Если для уже существующего дня поступает обновление, остальные столбцы должны быть объединены с существующей строкой за этот день. Чтобы такое объединение инкрементальных состояний было возможным, для остальных столбцов необходимо хранить частичные состояния.
Для этого в ClickHouse требуется специальный тип движка таблицы: SummingMergeTree. Он заменяет все строки с одинаковым ключом сортировки одной строкой, которая содержит суммарные значения для числовых столбцов. Следующая таблица будет объединять любые строки с одинаковой датой, суммируя значения во всех числовых столбцах:
Чтобы продемонстрировать наше материализованное представление, предположим, что таблица votes пуста и в нее еще не было вставлено ни одной строки. Наше материализованное представление выполняет указанный выше запрос SELECT по данным, вставляемым в votes, а результаты отправляются в up_down_votes_per_day:
Здесь ключевую роль играет предложение TO, которое определяет, куда будут отправлены результаты — в up_down_votes_per_day.
Мы можем заново заполнить нашу таблицу votes, повторив предыдущий оператор INSERT:
По завершении мы можем проверить количество строк в таблице up_down_votes_per_day — у нас должна быть одна строка на каждый день:
Мы фактически сократили количество строк здесь с 238 миллионов (в votes) до 5000, сохранив результат нашего запроса. Однако важно то, что если в таблицу votes вставляются новые голоса, новые значения будут записаны в up_down_votes_per_day для соответствующего дня, где они будут автоматически асинхронно слиты в фоновом режиме — при этом сохраняется только одна строка на день. Таким образом, up_down_votes_per_day всегда будет и небольшой по размеру, и актуальной.
Поскольку слияние строк выполняется асинхронно, при выполнении запроса пользователем может существовать более одной строки с голосами за день. Чтобы гарантировать, что все несведённые строки будут объединены во время запроса, у нас есть два варианта:
- Использовать модификатор
FINALв запросе к таблице. Мы сделали это для запросаCOUNT, приведённого выше. - Агрегировать по ключу сортировки, используемому в нашей итоговой таблице, т.е. по
CreationDate, и суммировать метрики. Как правило, это более эффективно и гибко (таблицу можно использовать и для других задач), но первый вариант может быть проще для некоторых запросов. Ниже мы приводим оба подхода:
Это ускорило выполнение нашего запроса с 0,133 с до 0,004 с — более чем в 25 раз!
ORDER BY = GROUP BYВ большинстве случаев столбцы, используемые в предложении GROUP BY при трансформации материализованного представления, должны совпадать со столбцами, указанными в предложении ORDER BY целевой таблицы при использовании движков таблиц SummingMergeTree или AggregatingMergeTree. Эти движки полагаются на столбцы ORDER BY для объединения строк с идентичными значениями во время фоновых операций слияния данных. Несоответствие между столбцами GROUP BY и ORDER BY может привести к неэффективному выполнению запросов, неоптимальным слияниям или даже несоответствиям в данных.
Более сложный пример
В приведённом выше примере используются материализованные представления для вычисления и ведения двух дневных сумм. Суммы представляют собой простейшую форму агрегирования для поддержания частичных состояний — мы можем просто добавлять новые значения к существующим по мере их поступления. Однако материализованные представления ClickHouse могут использоваться для любых типов агрегирования.
Предположим, мы хотим вычислить некоторые статистические показатели по постам за каждый день: 99.9-й перцентиль для поля Score и среднее значение по CommentCount. Запрос для вычисления этого может выглядеть следующим образом:
Как и раньше, мы можем создать материализованное представление, которое будет выполнять приведённый выше запрос при вставке новых постов в таблицу posts.
В качестве примера и чтобы избежать загрузки данных о постах из S3, мы создадим дублирующую таблицу posts_null с той же схемой, что и posts. Однако эта таблица не будет хранить никакие данные и будет использоваться материализованным представлением только при вставке строк. Чтобы предотвратить хранение данных, мы можем использовать тип движка таблицы Null.
Движок таблиц Null — это мощная оптимизация — думайте о нём как о /dev/null. Наше материализованное представление будет вычислять и сохранять сводную статистику, когда таблица posts_null получает строки при вставке — по сути, это триггер. Однако сырые данные сохраняться не будут. Хотя в нашем случае мы, вероятно, всё же захотим хранить исходные записи, такой подход можно использовать для вычисления агрегатов, избегая накладных расходов на хранение сырых данных.
Таким образом, материализованное представление приобретает следующий вид:
Обратите внимание, что мы добавляем суффикс State в конец наших агрегатных функций. Это гарантирует, что возвращается агрегатное состояние функции, а не конечный результат. Это состояние будет содержать дополнительную информацию, позволяющую объединить его с другими частичными состояниями. Например, в случае вычисления среднего сюда войдут количество и сумма по столбцу.
Частичные состояния агрегации необходимы для вычисления корректных результатов. Например, при вычислении среднего простое усреднение средних значений по поддиапазонам даёт некорректный результат.
Теперь мы создаём целевую таблицу для этого представления post_stats_per_day, которая будет хранить эти частичные агрегатные состояния:
Хотя ранее SummingMergeTree было достаточно для хранения счётчиков, для других функций нам нужен более продвинутый тип движка: AggregatingMergeTree.
Чтобы ClickHouse знал, что будут храниться состояния агрегатных функций, мы определяем Score_quantiles и AvgCommentCount как тип AggregateFunction, указывая функцию, формирующую частичные состояния, и тип их исходных столбцов. Как и в случае с SummingMergeTree, строки с одинаковым значением ключа ORDER BY будут объединяться (в приведённом выше примере — по Day).
Чтобы заполнить таблицу post_stats_per_day через наше материализованное представление, мы можем просто вставить все строки из posts в posts_null:
В продакшене вы, скорее всего, создавали бы материализованное представление для таблицы
posts. Здесь мы использовалиposts_null, чтобы продемонстрировать null-таблицу.
Наш итоговый запрос должен использовать суффикс Merge в функциях (так как столбцы хранят состояния частичной агрегации):
Обратите внимание, что здесь мы используем GROUP BY вместо FINAL.
Другие применения
Выше основное внимание уделялось использованию материализованных представлений для инкрементального обновления частичных агрегатов данных, тем самым перенося вычисления с момента выполнения запроса на момент вставки. Помимо этого распространённого варианта использования, материализованные представления имеют ряд других применений.
Фильтрация и преобразование
В некоторых ситуациях нам может потребоваться при вставке записывать только подмножество строк и столбцов. В этом случае наша таблица posts_null может принимать вставки, а запрос SELECT будет фильтровать строки перед вставкой в таблицу posts. Например, предположим, что мы хотим преобразовать столбец Tags в нашей таблице posts. Он содержит разделённый вертикальной чертой список имён тегов. Преобразовав его в массив, мы сможем проще выполнять агрегацию по отдельным значениям тегов.
Мы могли бы выполнить это преобразование при выполнении
INSERT INTO SELECT. Материализованное представление позволяет инкапсулировать эту логику в ClickHouse DDL и сделать нашINSERTпростым, с применением преобразования ко всем новым строкам.
Наше материализованное представление для этого преобразования показано ниже:
Таблица соответствий
Пользователям следует учитывать свои шаблоны доступа при выборе ключа сортировки в ClickHouse. Следует использовать столбцы, которые часто используются в предложениях фильтрации и агрегации. Это может стать ограничением в сценариях, когда у пользователей более разнообразные шаблоны доступа, которые нельзя выразить одним набором столбцов. Например, рассмотрим следующую таблицу comments:
Ключ сортировки в данном случае оптимизирует таблицу для запросов, которые фильтруют по PostId.
Предположим, что пользователь хочет отфильтровать данные по конкретному UserId и вычислить его среднее значение Score:
Хотя запрос выполняется быстро (объём данных для ClickHouse небольшой), по количеству обработанных строк — 90,38 млн — мы видим, что требуется полное сканирование таблицы. Для более крупных наборов данных мы можем использовать материализованное представление, чтобы получать значения нашего ключа сортировки PostId для фильтрации по столбцу UserId. Затем эти значения можно использовать для эффективного поиска.
В этом примере наше материализованное представление может быть очень простым: оно выбирает только PostId и UserId из comments при вставке. Затем эти результаты записываются в таблицу comments_posts_users, которая упорядочена по UserId. Ниже мы создаём пустую версию таблицы Comments и используем её для заполнения нашего представления и таблицы comments_posts_users:
Теперь мы можем использовать это представление во вложенном запросе, чтобы ускорить выполнение нашего предыдущего запроса:
1 строка в наборе. Время: 0.012 сек. Обработано 88.61 тыс. строк, 771.37 КБ (7.09 млн строк/с, 61.73 МБ/с.)
Материализованные представления и JOIN
Следующее относится только к инкрементным материализованным представлениям (Incremental Materialized Views). Обновляемые материализованные представления (Refreshable Materialized Views) периодически выполняют свой запрос по всему целевому набору данных и полностью поддерживают JOIN. Рассмотрите возможность их использования для сложных JOIN, если допустимо снижение актуальности результатов.
Инкрементные материализованные представления в ClickHouse полностью поддерживают операции JOIN, но с одним ключевым ограничением: материализованное представление срабатывает только при вставках в исходную таблицу (самую левую таблицу в запросе). Таблицы справа в JOIN не инициируют обновления, даже если их данные изменяются. Это поведение особенно важно при построении инкрементных материализованных представлений, где данные агрегируются или трансформируются во время вставки.
Когда инкрементное материализованное представление определяется с использованием JOIN, самая левая таблица в запросе SELECT выступает в роли источника. Когда в эту таблицу вставляются новые строки, ClickHouse выполняет запрос материализованного представления только с этими новыми строками. Таблицы справа в JOIN читаются целиком во время этого выполнения, но изменения только в них не инициируют обновление представления.
Такое поведение делает операции JOIN в материализованных представлениях похожими на snapshot-join по статическим таблицам измерений.
Это хорошо подходит для обогащения данных с помощью справочных или таблиц измерений. Однако любые обновления таблиц справа (например, пользовательских метаданных) не будут задним числом обновлять материализованное представление. Чтобы увидеть обновлённые данные, в исходную таблицу должны поступить новые вставки.
Пример
Рассмотрим конкретный пример с использованием набора данных Stack Overflow. Мы будем использовать материализованное представление для вычисления ежедневного количества бейджей для каждого пользователя, включая отображаемое имя пользователя из таблицы users.
Напомним, наши схемы таблиц выглядят так:
Предположим, что таблица users уже заполнена:
Материализованное представление и связанная с ним целевая таблица определяются так:
Предложение GROUP BY в материализованном представлении должно включать DisplayName, UserId и Day, чтобы соответствовать ORDER BY в целевой таблице SummingMergeTree. Это обеспечивает корректную агрегацию и объединение строк. Пропуск любого из этих столбцов может привести к некорректным результатам или неэффективным слияниям.
Если теперь заполнить бейджи, представление будет срабатывать и заполнять нашу таблицу daily_badges_by_user.
Предположим, мы хотим просмотреть бейджи, полученные конкретным пользователем, — для этого можно выполнить следующий запрос:
Теперь, если этот пользователь получит новый бейдж и будет вставлена новая строка, наше представление будет обновлено:
Обратите внимание на задержку вставки. Вставленная строка пользователя соединяется со всей таблицей users, что существенно снижает производительность вставки. Ниже мы предлагаем подходы к решению этой проблемы в разделе "Использование исходной таблицы в фильтрах и соединениях".
Напротив, если мы сначала вставим бейдж для нового пользователя, а затем строку для этого пользователя, наше материализованное представление не сможет зафиксировать метрики этого пользователя.
Представление в этом случае выполняется только при вставке бейджа до того, как будет создана строка пользователя. Если мы вставим ещё один бейдж для пользователя, строка будет вставлена, как и ожидалось:
Однако обратите внимание, что этот результат некорректен.
Рекомендуемые практики использования JOIN в материализованных представлениях
-
Используйте самую левую таблицу как триггер. Только таблица слева в операторе
SELECTинициирует материализованное представление. Изменения в таблицах справа не будут вызывать обновления. -
Предварительно вставляйте объединённые данные. Убедитесь, что данные в таблицах, участвующих в JOIN, уже существуют до вставки строк в исходную таблицу. JOIN вычисляется в момент вставки, поэтому отсутствие данных приведёт к несовпадающим строкам или значениям null.
-
Ограничивайте набор колонок, получаемых из JOIN. Выбирайте только необходимые колонки из присоединённых таблиц, чтобы минимизировать использование памяти и сократить задержку вставки (см. ниже).
-
Оценивайте производительность вставки. JOIN увеличивает стоимость операций вставки, особенно при больших таблицах справа. Проводите тестирование скоростей вставки на репрезентативных production-данных.
-
Предпочитайте словари для простых поисков. Используйте Dictionaries для key-value-поиска (например, сопоставления user ID и имени), чтобы избежать дорогостоящих операций JOIN.
-
Согласуйте
GROUP BYиORDER BYдля эффективности слияний. При использованииSummingMergeTreeилиAggregatingMergeTreeубедитесь, чтоGROUP BYсовпадает с выражениемORDER BYв целевой таблице, чтобы обеспечить эффективное слияние строк. -
Используйте явные псевдонимы колонок. Когда в таблицах есть совпадающие имена колонок, используйте псевдонимы, чтобы устранить неоднозначность и гарантировать корректные результаты в целевой таблице.
-
Учитывайте объём и частоту вставок. JOIN хорошо работает при умеренной нагрузке на вставку. Для высокопроизводительной ингестии рассмотрите использование промежуточных таблиц, предварительного объединения (pre-join) или других подходов, таких как Dictionaries и Refreshable Materialized Views.
Использование исходной таблицы в фильтрах и JOIN
При работе с материализованными представлениями в ClickHouse важно понимать, как исходная таблица обрабатывается во время выполнения запроса материализованного представления. В частности, исходная таблица в запросе материализованного представления заменяется вставляемым блоком данных. Если не учитывать эту особенность, такое поведение может приводить к неожиданным результатам.
Пример сценария
Рассмотрим следующую конфигурацию:
Пояснение
В приведённом выше примере у нас есть два материализованных представления mvw1 и mvw2, которые выполняют схожие операции, но с небольшим отличием в том, как они ссылаются на исходную таблицу t0.
В mvw1 таблица t0 напрямую используется во вложенном запросе (SELECT * FROM t0) в правой части JOIN. Когда данные вставляются в t0, запрос материализованного представления выполняется с блоком вставленных данных вместо t0. Это означает, что операция JOIN выполняется только над вновь вставленными строками, а не над всей таблицей.
Во втором случае, при соединении с vt0, представление читает все данные из t0. Это гарантирует, что операция JOIN учитывает все строки в t0, а не только вновь вставленный блок.
Ключевое отличие заключается в том, как ClickHouse обрабатывает исходную таблицу в запросе материализованного представления. Когда материализованное представление срабатывает при вставке данных, исходная таблица (в данном случае t0) заменяется блоком вставленных данных. Это поведение можно использовать для оптимизации запросов, но при этом необходимо внимательно его учитывать, чтобы избежать неожиданных результатов.
Сценарии использования и ограничения
На практике вы можете использовать это поведение для оптимизации материализованных представлений, которым нужно обрабатывать лишь подмножество данных исходной таблицы. Например, можно использовать подзапрос для фильтрации исходной таблицы перед её соединением с другими таблицами. Это может помочь сократить объём данных, обрабатываемых материализованным представлением, и улучшить производительность.
В этом примере множество, построенное из подзапроса IN (SELECT id FROM t0), содержит только вновь вставленные строки, что может помочь при фильтрации t1 по этому множеству.
Пример со Stack Overflow
Рассмотрим наш предыдущий пример с материализованным представлением для вычисления ежедневных бейджей для каждого пользователя, включая отображаемое имя пользователя из таблицы users.
Это представление значительно увеличивало задержку вставки в таблицу badges, например:
Используя описанный выше подход, мы можем оптимизировать данное представление. Мы добавим фильтр к таблице users, используя идентификаторы пользователей из вставленных строк с бейджами:
Это не только ускоряет первоначальную вставку бейджей:
0 строк в наборе. Затрачено: 132,118 с. Обработано 323,43 млн строк, 4,69 ГБ (2,45 млн строк/с, 35,49 МБ/с). Пиковое использование памяти: 1,99 ГиБ.
В приведённой выше операции из таблицы users извлекается только одна строка для пользователя с идентификатором 2936484. Этот поиск также оптимизирован с помощью ключа сортировки таблицы по столбцу Id.
Материализованные представления и операции UNION
Запросы с UNION ALL обычно используются для объединения данных из нескольких исходных таблиц в единый результирующий набор.
Хотя UNION ALL напрямую не поддерживается в инкрементальных материализованных представлениях, того же результата можно добиться, создав отдельное материализованное представление для каждой ветви запроса SELECT и записывая их результаты в общую целевую таблицу.
В нашем примере мы будем использовать набор данных Stack Overflow. Рассмотрим таблицы badges и comments ниже, которые отражают значки, полученные пользователем, и комментарии, которые он оставляет к публикациям:
Их можно заполнить, выполнив следующие команды INSERT INTO:
Предположим, мы хотим создать единое представление активности пользователей, показывающее последнюю активность каждого пользователя, объединив эти две таблицы:
Допустим, у нас есть целевая таблица для получения результатов этого запроса. Обратите внимание на использование движка таблицы AggregatingMergeTree и типа данных AggregateFunction для обеспечения корректного объединения результатов:
Если мы хотим, чтобы эта таблица обновлялась по мере вставки новых строк либо в badges, либо в comments, наивный подход к решению этой задачи заключался бы в попытке создать материализованное представление на основе предыдущего запроса с UNION:
Хотя это синтаксически корректно, оно приведёт к непреднамеренным результатам — представление будет инициировать вставки только в таблицу comments. Например:
┌─UserId──┬─description──────┬─activity_type─┬───────────last_activity─┐ │ 2936484 │ Ответ — 42 │ comment │ 2025-04-15 09:56:19.000 │ └─────────┴──────────────────┴───────────────┴─────────────────────────┘
1 строка в наборе. Затрачено: 0.005 сек.
Чтобы решить эту задачу, мы просто создаём материализованное представление для каждого запроса SELECT:
Теперь вставка в любую из таблиц даёт корректные результаты. Например, если вставить данные в таблицу comments:
Аналогично, операции INSERT в таблицу badges отражаются в таблице user_activity:
Параллельная и последовательная обработка
Как показано в предыдущем примере, таблица может использоваться как источник для нескольких материализованных представлений. Порядок их выполнения зависит от настройки parallel_view_processing.
По умолчанию значение этой настройки равно 0 (false), что означает, что материализованные представления выполняются последовательно в порядке их uuid.
Например, рассмотрим следующую таблицу source и три материализованных представления, каждое из которых отправляет строки в таблицу target:
Обратите внимание, что каждое представление делает паузу на 1 секунду перед вставкой своих строк в таблицу target, одновременно добавляя свое имя и время вставки.
Вставка строки в таблицу source занимает примерно 3 секунды, при этом каждое представление выполняется последовательно:
Мы можем подтвердить поступление строк из каждого источника с помощью запроса SELECT:
Это соответствует значению uuid представлений:
Для сравнения рассмотрим, что произойдет, если мы вставим строку при включенном parallel_view_processing=1. В этом режиме представления выполняются параллельно, и порядок, в котором строки поступают в целевую таблицу, не гарантируется:
Хотя порядок поступления строк из каждого представления у нас одинаковый, это не гарантируется — что видно по близким значениям времени вставки для каждой строки. Также обратите внимание на улучшившуюся производительность вставки.
Когда использовать параллельную обработку
Включение parallel_view_processing=1 может существенно повысить пропускную способность вставки, как показано выше, особенно когда к одной таблице прикреплено несколько материализованных представлений. Однако важно понимать существующие компромиссы:
- Повышенная нагрузка при вставке: Все материализованные представления выполняются одновременно, что увеличивает использование CPU и памяти. Если каждое представление выполняет ресурсоёмкие вычисления или JOIN-операции, это может перегрузить систему.
- Необходимость строгого порядка выполнения: В редких рабочих процессах, где порядок выполнения представлений имеет значение (например, каскадные зависимости), параллельное выполнение может привести к несогласованному состоянию или гонкам. Хотя можно спроектировать систему в обход этой проблемы, такие конфигурации хрупки и могут сломаться в будущих версиях.
Последовательное выполнение долгое время было значением по умолчанию, частично из-за сложности обработки ошибок. Исторически сбой в одном материализованном представлении мог помешать выполнению остальных. В новых версиях это улучшено за счёт изоляции сбоев на уровне блоков, но последовательное выполнение по-прежнему обеспечивает более понятную семантику отказов.
В общем случае включайте parallel_view_processing=1, когда:
- У вас есть несколько независимых материализованных представлений
- Вы стремитесь максимизировать производительность вставки
- Вы учитываете возможности системы по обработке одновременного выполнения представлений
Оставляйте его выключенным, когда:
- Между материализованными представлениями есть взаимозависимости
- Вам требуется предсказуемое, упорядоченное выполнение
- Вы отлаживаете или проверяете поведение вставки и хотите детерминированное воспроизведение
Материализованные представления и Common Table Expressions (CTE)
Нерекурсивные Common Table Expressions (CTE) поддерживаются в материализованных представлениях.
ClickHouse не материализует CTE; вместо этого он подставляет определение CTE непосредственно в запрос, что может приводить к многократному выполнению одного и того же выражения (если CTE используется более одного раза).
Рассмотрим следующий пример, который вычисляет ежедневную активность для каждого типа поста.
Хотя CTE здесь, строго говоря, не требуется, для примера представление будет работать как ожидается:
В ClickHouse CTE подставляются инлайн, то есть фактически копируются и вставляются в запрос во время оптимизации и не материализуются. Это означает:
- Если ваш CTE ссылается на другую таблицу, отличную от исходной таблицы (то есть той, к которой привязано материализованное представление), и используется в выражении
JOINилиIN, он будет вести себя как подзапрос или соединение, а не как триггер. - Материализованное представление по‑прежнему будет срабатывать только при вставках в основную исходную таблицу, но CTE будет выполняться заново при каждой вставке, что может приводить к лишним накладным расходам, особенно если таблица, на которую идёт ссылка, большая.
Например,
В этом случае CTE users повторно вычисляется при каждой вставке в posts, и материализованное представление не будет обновляться при добавлении новых записей в users — только при добавлении записей в posts.
Как правило, используйте CTE для логики, которая работает с той же исходной таблицей, к которой привязано материализованное представление, или убедитесь, что участвующие таблицы небольшие и вряд ли станут узким местом производительности. В качестве альтернативы рассмотрите те же оптимизации, что и для JOIN в материализованных представлениях.
