Автоматическое масштабирование
Масштабирование — это возможность изменять доступные ресурсы в соответствии с запросами клиентов. Сервисы уровней Scale и Enterprise (со стандартным профилем 1:4) могут масштабироваться горизонтально через программные вызовы API или путем изменения настроек в пользовательском интерфейсе для регулирования системных ресурсов. Эти сервисы также могут автоматически масштабироваться вертикально в соответствии с потребностями приложений.
Automatic vertical scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Уровни Scale и Enterprise поддерживают как сервисы с одной репликой, так и с несколькими репликами, тогда как уровень Basic поддерживает только сервисы с одной репликой. Сервисы с одной репликой имеют фиксированный размер и не допускают вертикального или горизонтального масштабирования. Пользователи могут перейти на уровень Scale или Enterprise, чтобы масштабировать свои сервисы.
Как работает масштабирование в ClickHouse Cloud
В настоящее время ClickHouse Cloud поддерживает вертикальное автомасштабирование и ручное горизонтальное масштабирование для сервисов уровня Scale.
Для сервисов уровня Enterprise масштабирование работает следующим образом:
- Горизонтальное масштабирование: ручное горизонтальное масштабирование доступно для всех стандартных и пользовательских профилей на уровне Enterprise.
- Вертикальное масштабирование:
- Стандартные профили (1:4) поддерживают вертикальное автомасштабирование.
- Пользовательские профили (
highMemoryиhighCPU) не поддерживают вертикальное автомасштабирование или ручное вертикальное масштабирование. Однако вертикальное масштабирование таких сервисов возможно по обращению в службу поддержки.
Масштабирование в ClickHouse Cloud реализовано по принципу, который мы называем "Make Before Break" (MBB). При этом сначала добавляется одна или несколько реплик нового размера, а затем удаляются старые реплики, что предотвращает потерю ресурсов во время операций масштабирования. Исключая разрыв между удалением существующих реплик и добавлением новых, MBB обеспечивает более плавный и менее заметный для пользователей процесс масштабирования. Подход особенно полезен при масштабировании "вверх", когда высокая утилизация ресурсов вызывает необходимость в дополнительной мощности, так как преждевременное удаление реплик только усугубило бы дефицит ресурсов. В рамках этого подхода мы ждём до часа, чтобы позволить существующим запросам завершиться на старых репликах, прежде чем удалять их. Это позволяет сбалансировать необходимость завершения текущих запросов с необходимостью не держать старые реплики слишком долго.
Обратите внимание, что в рамках этого изменения:
- Исторические данные системных таблиц сохраняются максимум за последние 30 дней в рамках событий масштабирования. Кроме того, любые данные системных таблиц старше 19 декабря 2024 года для сервисов на AWS или GCP и старше 14 января 2025 года для сервисов на Azure не будут сохранены в рамках миграции на новые уровни организаций.
- Для сервисов, использующих TDE (Transparent Data Encryption), данные системных таблиц в настоящее время не сохраняются после операций MBB. Мы работаем над устранением этого ограничения.
Вертикальное автомасштабирование
Automatic vertical scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Сервисы уровней Scale и Enterprise поддерживают автомасштабирование на основе использования CPU и памяти. Мы постоянно отслеживаем историческое использование сервиса в окне анализа (за последние 30 часов), чтобы принимать решения о масштабировании. Если использование превышает или опускается ниже определённых порогов, мы масштабируем сервис соответствующим образом, чтобы сопоставить выделенные ресурсы с нагрузкой.
Для сервисов без MBB автомасштабирование по CPU срабатывает, когда загрузка CPU превышает верхний порог в диапазоне 50–75% (фактический порог зависит от размера кластера). В этот момент выделение CPU кластеру удваивается. Если загрузка CPU опускается ниже половины верхнего порога (например, до 25% при верхнем пороге 50%), выделение CPU уменьшается вдвое.
Для сервисов, уже использующих подход масштабирования MBB, масштабирование вверх происходит при пороге загрузки CPU 75%, а масштабирование вниз — при половине этого значения, то есть 37,5%.
Автомасштабирование по памяти увеличивает размер кластера до 125% от максимального использования памяти или до 150%, если возникают ошибки OOM (out of memory).
Выбирается большее из рекомендуемых значений по CPU или памяти, и CPU и память, выделенные сервису, масштабируются синхронно, шагами по 1 CPU и 4 GiB памяти.
Настройка вертикального автомасштабирования
Масштабирование сервисов ClickHouse Cloud уровня Scale или Enterprise может настраиваться участниками организации с ролью Admin. Чтобы настроить вертикальное автомасштабирование, перейдите на вкладку Settings вашего сервиса и измените минимальные и максимальные значения памяти, а также параметры CPU, как показано ниже.
Сервисы с одной репликой не поддерживают масштабирование ни в одном из уровней.
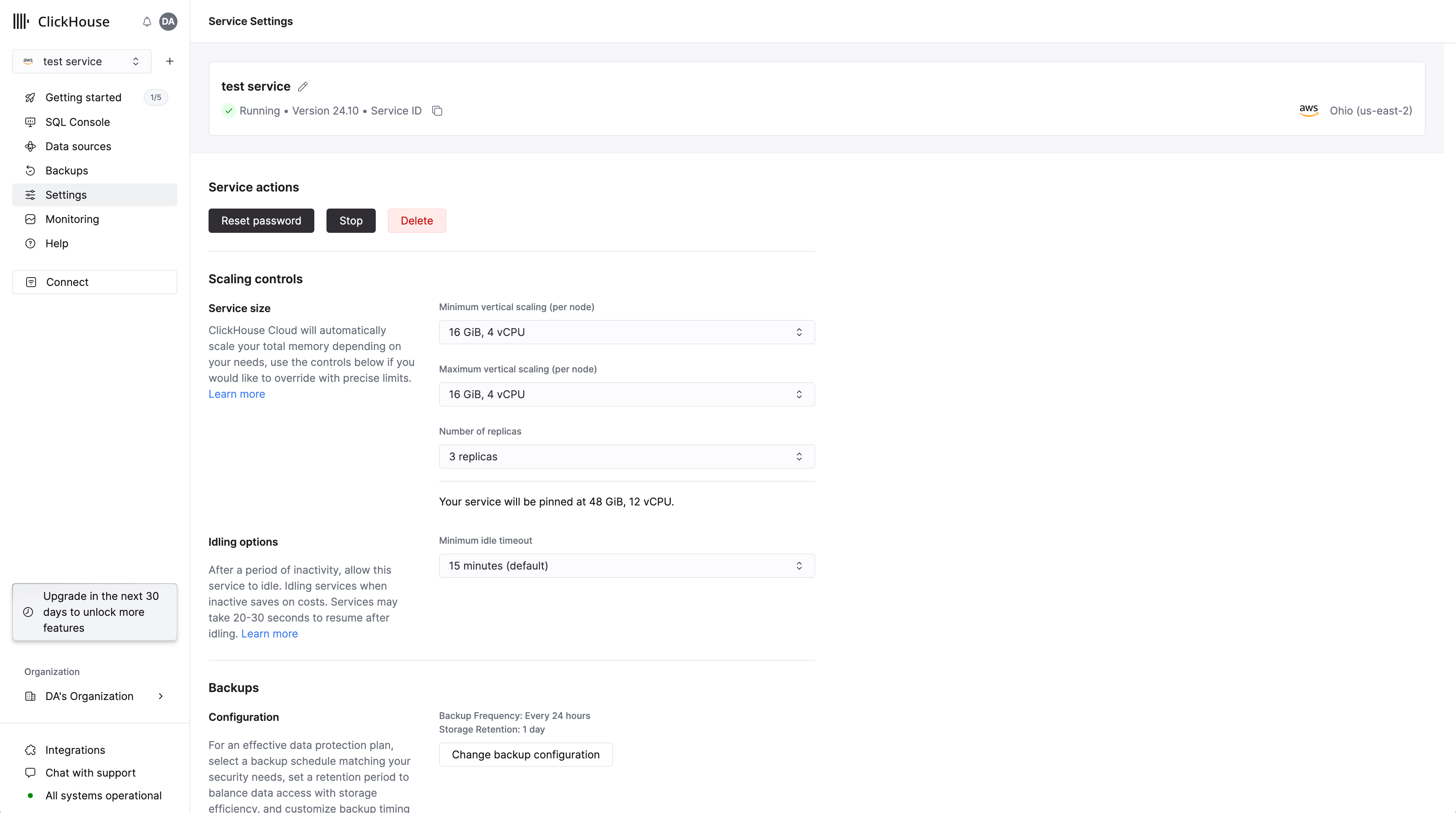
Установите значение Maximum memory для ваших реплик выше, чем Minimum memory. Тогда сервис будет масштабироваться по мере необходимости в пределах этих границ. Эти параметры также доступны во время начального процесса создания сервиса. Каждой реплике в вашем сервисе будут выделены одинаковые ресурсы памяти и CPU.
Вы также можете установить одинаковые значения, фактически "зафиксировав" сервис на конкретной конфигурации. Это сразу же приведёт к масштабированию до выбранного вами размера.
Важно отметить, что это отключит любое автомасштабирование кластера, и ваш сервис не будет защищён от роста использования CPU или памяти сверх этих настроек.
Для сервисов уровня Enterprise стандартные профили 1:4 поддерживают вертикальное автомасштабирование. Пользовательские профили на начальном этапе не поддерживают вертикальное автомасштабирование или ручное вертикальное масштабирование. Однако вертикальное масштабирование таких сервисов возможно по обращению в службу поддержки.
Ручное горизонтальное масштабирование
Manual horizontal scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Вы можете использовать публичные API ClickHouse Cloud, чтобы масштабировать сервис, обновив его настройки масштабирования, или изменить количество реплик из облачной консоли.
Тарифы Scale и Enterprise также поддерживают сервисы с одной репликой. Сервисы, которые были масштабированы горизонтально, можно уменьшить обратно до минимального значения — одной реплики. Обратите внимание, что сервисы с одной репликой обладают сниженной доступностью и не рекомендуются для использования в продуктивной среде.
Сервисы могут масштабироваться горизонтально максимум до 20 реплик. Если вам требуется большее число реплик, свяжитесь с нашей службой поддержки.
Горизонтальное масштабирование через API
Для горизонтального масштабирования кластера отправьте запрос PATCH через API, чтобы изменить количество реплик. Скриншоты ниже показывают вызов API для масштабирования кластера с 3 реплик до 6 реплик и соответствующий ответ.
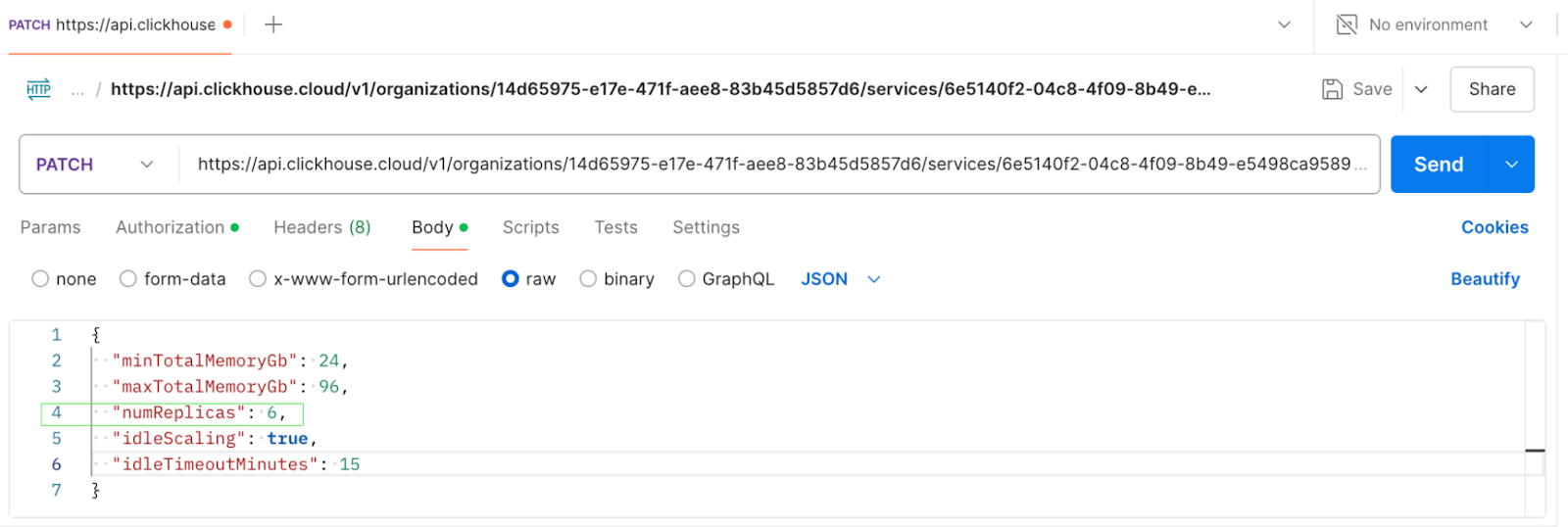
PATCH‑запрос для обновления numReplicas
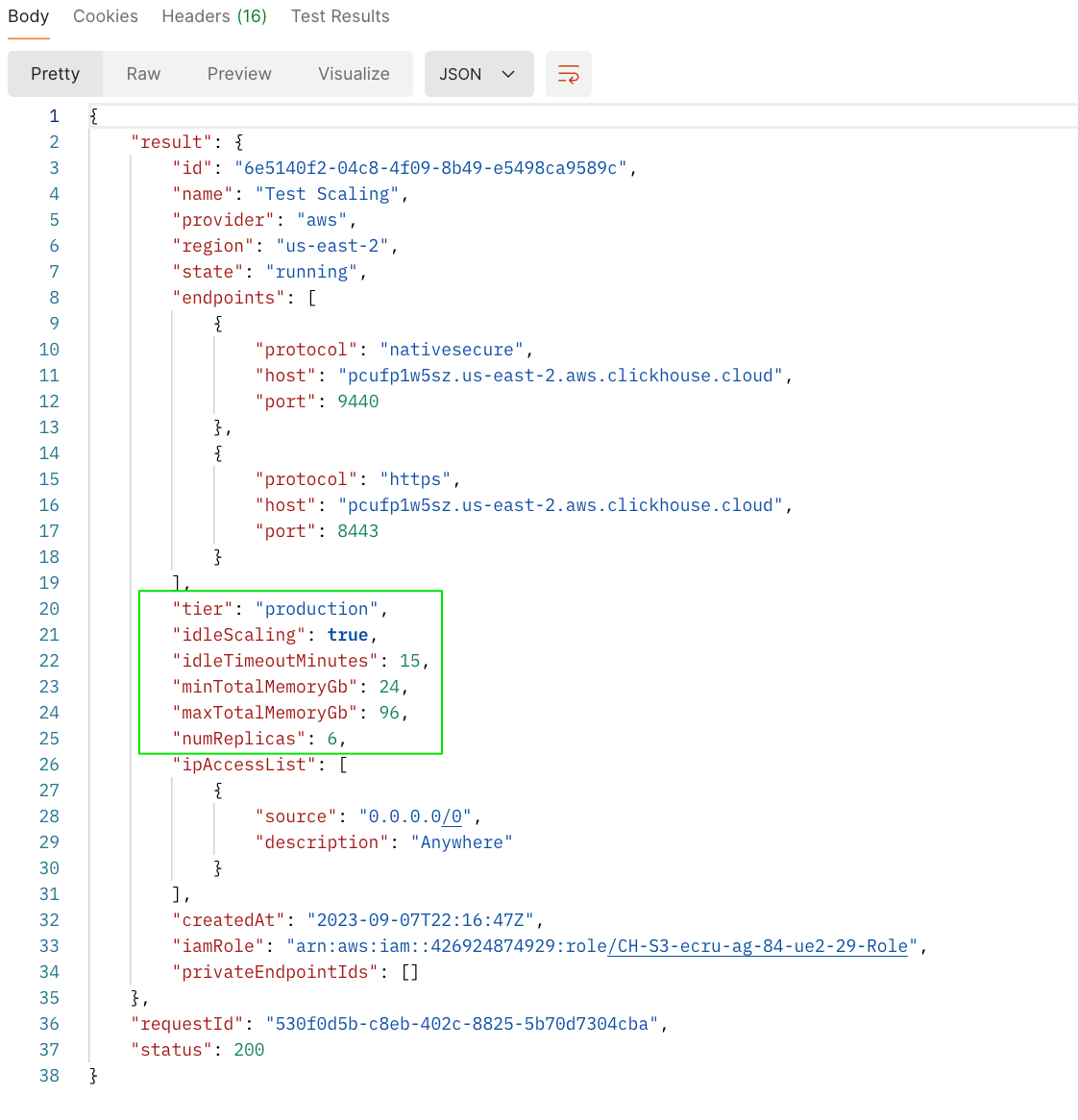
Ответ на PATCH‑запрос
Если вы отправите новый запрос масштабирования или несколько запросов подряд, пока один уже выполняется, служба масштабирования проигнорирует промежуточные состояния и в итоге сойдётся к целевому числу реплик.
Горизонтальное масштабирование через UI
Чтобы масштабировать сервис горизонтально через UI, измените количество реплик для сервиса на странице Settings.
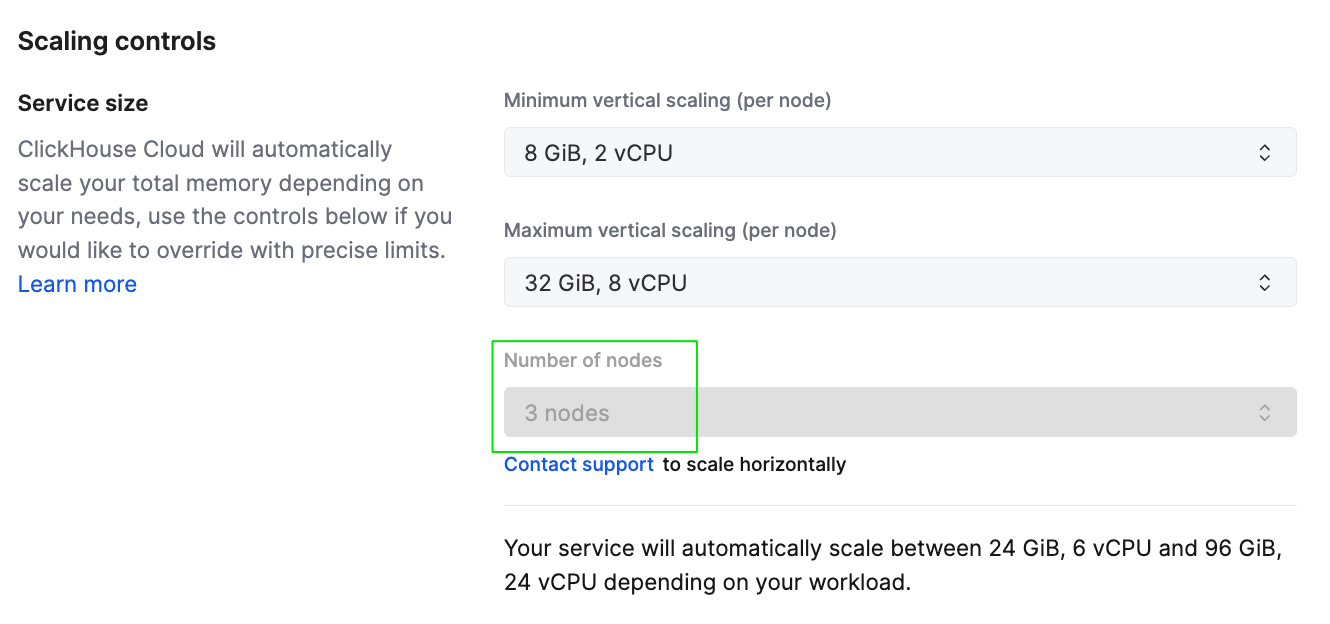
Настройки масштабирования сервиса в консоли ClickHouse Cloud
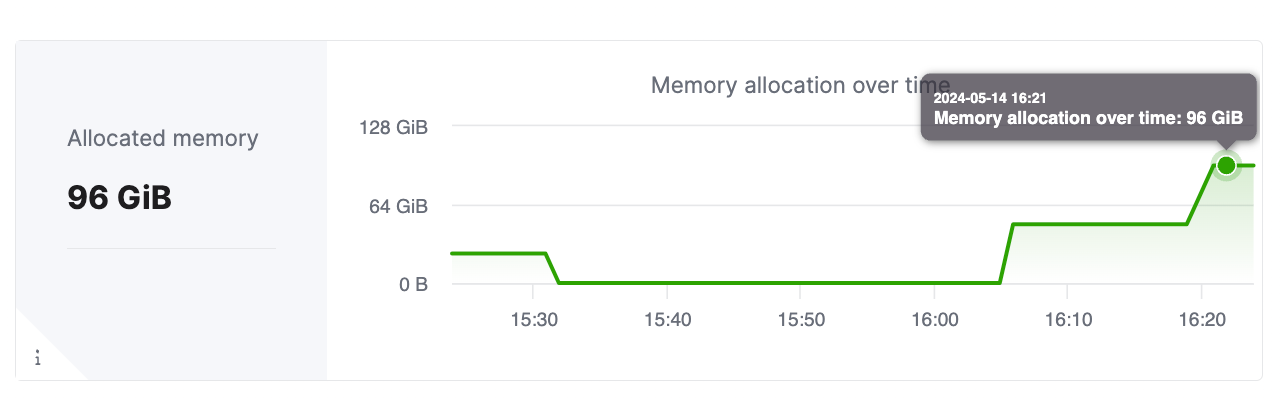
После того как сервис будет масштабирован, дашборд метрик в облачной консоли должен отразить корректное выделение ресурсов для сервиса. Скриншот ниже показывает кластер, масштабированный до общего объёма памяти 96 GiB, что соответствует 6 репликам, каждая с выделением памяти 16 GiB.
Автоматический переход в режим ожидания
На странице Settings вы также можете выбрать, разрешать ли автоматический переход сервиса в режим ожидания, когда он неактивен, как показано на изображении выше (то есть когда сервис не выполняет никаких пользовательских запросов). Автоматический переход в режим ожидания снижает стоимость работы сервиса, так как с вас не взимается плата за вычислительные ресурсы, пока сервис приостановлен.
В некоторых особых случаях, например когда у сервиса большое количество частей данных, он не будет автоматически переведен в режим ожидания.
Сервис может перейти в режим ожидания, при котором приостанавливаются обновления обновляемых материализованных представлений, потребление из S3Queue и планирование новых операций слияния (merge). Текущие операции слияния будут завершены до того, как сервис перейдет в режим ожидания. Чтобы обеспечить непрерывную работу обновляемых материализованных представлений и потребления из S3Queue, отключите функцию режима ожидания.
Используйте автоматический переход в режим ожидания только в том случае, если в вашей задаче допустима задержка перед ответом на запросы, поскольку при приостановке сервиса подключения к нему будут завершаться по таймауту. Автоматический переход в режим ожидания оптимален для сервисов, которые используются редко и где задержка может быть терпима. Он не рекомендуется для сервисов, обеспечивающих клиентские функции, которыми часто пользуются.
Обработка всплесков нагрузки
Если в ближайшее время ожидается всплеск нагрузки, вы можете использовать ClickHouse Cloud API, чтобы заранее увеличить масштаб сервиса для обработки всплеска, а затем уменьшить его, когда спрос снизится.
Чтобы узнать текущее количество задействованных ядер CPU и объём памяти для каждой из ваших реплик, выполните следующий запрос:
