Хранилища
Что такое разделение вычислительных ресурсов (compute-compute)?
Разделение вычислительных ресурсов (compute-compute) доступно для тарифов Scale и Enterprise.
Каждый сервис ClickHouse Cloud включает:
- Группу из двух или более узлов ClickHouse (или реплик) — это обязательное требование, однако дочерние сервисы могут иметь только одну реплику.
- Endpoint (или несколько endpoints, созданных через веб-консоль ClickHouse Cloud) — это URL сервиса, который вы используете для подключения к нему (например,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443). - Папку в объектном хранилище, где сервис хранит все данные и часть метаданных:
Дочерние сервисы с одной репликой могут масштабироваться вертикально, в отличие от родительских сервисов с одной репликой.
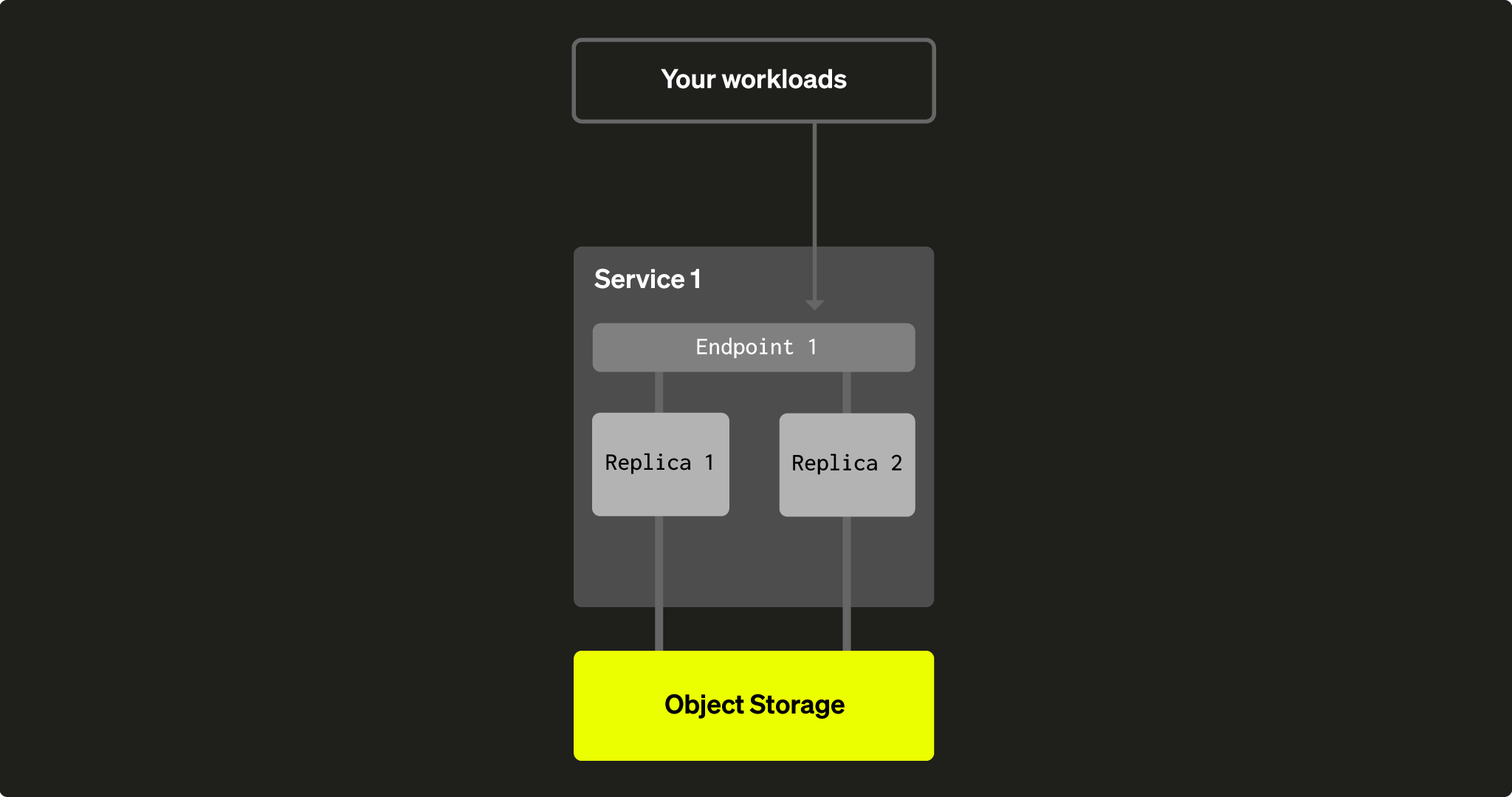
Рис. 1 — текущий сервис в ClickHouse Cloud
Разделение вычислительных ресурсов (compute-compute) позволяет пользователям создавать несколько групп вычислительных узлов, каждая со своим endpoint, которые используют одну и ту же папку в объектном хранилище и, следовательно, одни и те же таблицы, представления и т. д.
Каждая группа вычислительных узлов будет иметь свой endpoint, поэтому вы можете выбирать, какой набор реплик использовать для своих нагрузок. Для части нагрузок может быть достаточно одной небольшой реплики, а другие могут требовать полноценной высокой доступности (HA) и сотен гигабайт памяти. Разделение вычислительных ресурсов также позволяет разделить операции чтения и записи, чтобы они не мешали друг другу:
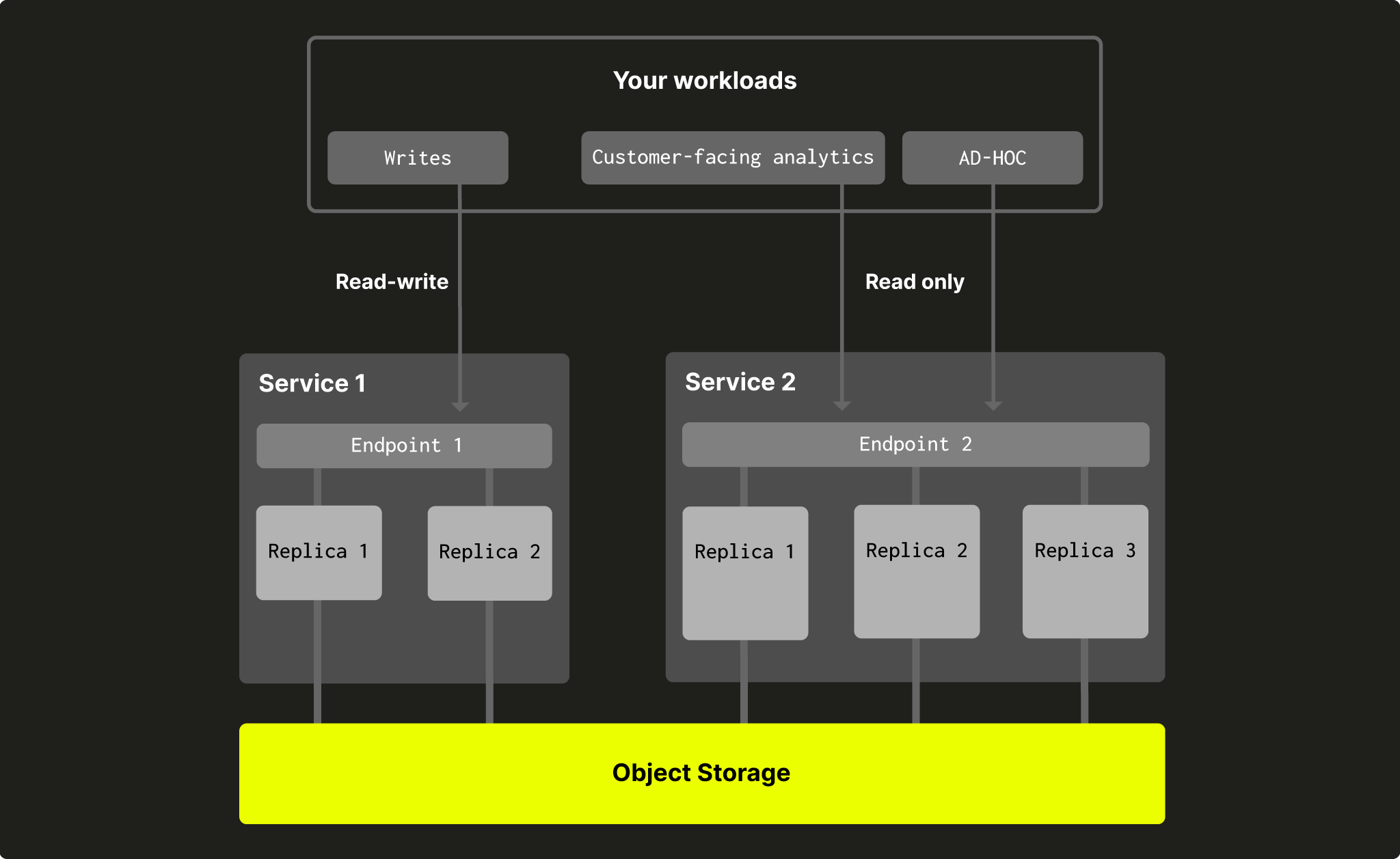
Рис. 2 — разделение вычислительных ресурсов в ClickHouse Cloud
Можно создавать дополнительные сервисы, которые совместно используют те же данные, что и ваши существующие сервисы, или настроить полностью новую конфигурацию с несколькими сервисами, совместно использующими одни и те же данные.
Что такое warehouse?
В ClickHouse Cloud warehouse — это набор сервисов, которые используют одни и те же данные. У каждого warehouse есть основной сервис (этот сервис был создан первым) и вторичные сервисы. Например, на скриншоте ниже показан warehouse "DWH Prod" с двумя сервисами:
- Основной сервис
DWH Prod - Вторичный сервис
DWH Prod Subservice

Рис. 3 — Пример warehouse
Все сервисы в одном warehouse используют общие настройки:
- Регион (например, us-east1)
- Облачного провайдера (AWS, GCP или Azure)
- Версию базы данных ClickHouse
Вы можете сортировать сервисы по warehouse, к которому они относятся.
Контроль доступа
Учетные данные базы данных
Поскольку все сервисы в рамках одного warehouse используют один и тот же набор таблиц, к ним применяются одни и те же настройки доступа. Это означает, что все пользователи базы данных, созданные в Service 1, смогут использовать Service 2 с теми же правами (гранты на таблицы, представления и т.д.), и наоборот. Пользователи будут использовать разные endpoints для каждого сервиса, но один и тот же логин и пароль. Другими словами, пользователи являются общими для сервисов, которые работают с одним и тем же хранилищем:
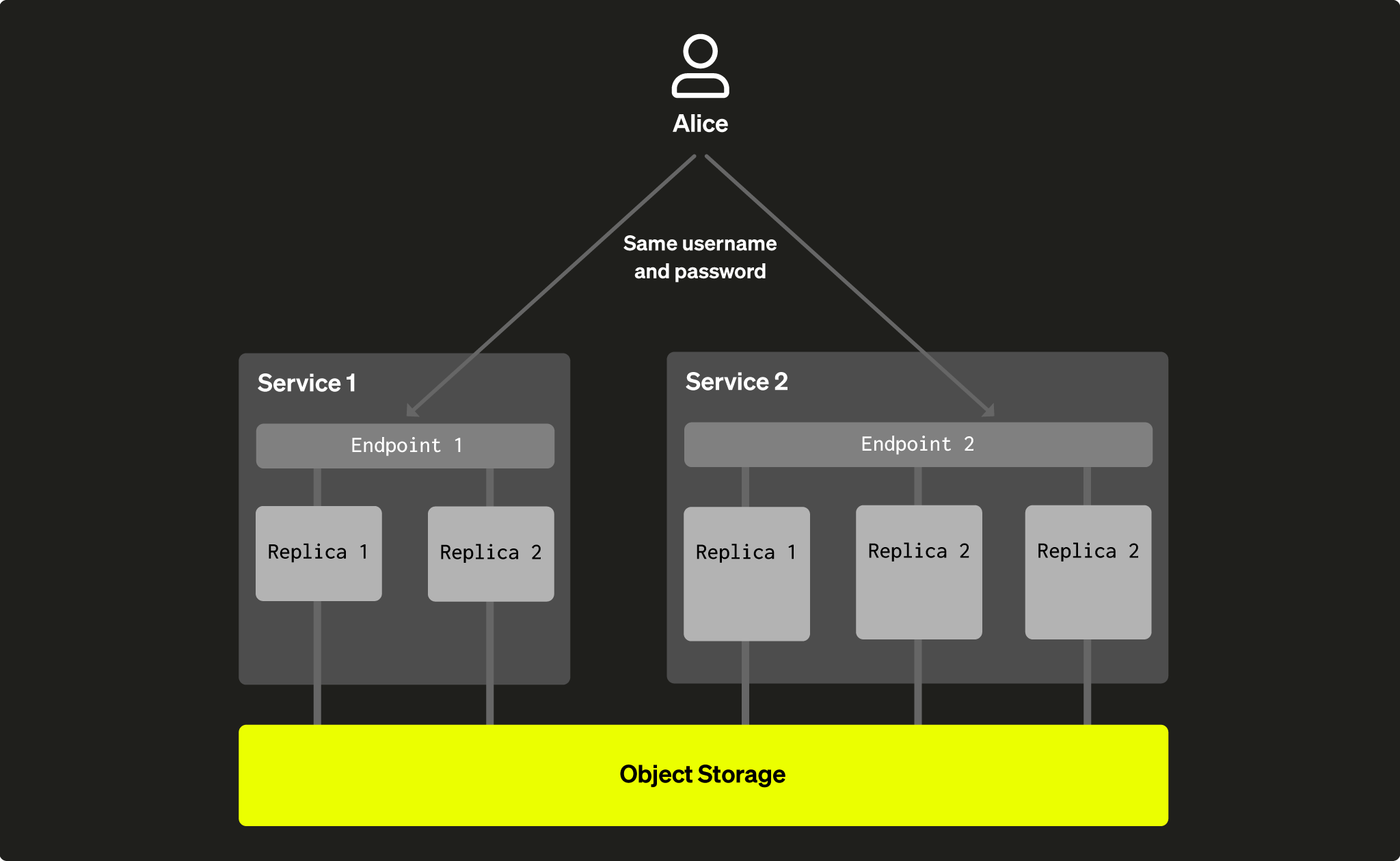
Рис. 4 — пользователь Alice был создан в Service 1, но она может использовать те же учетные данные для доступа ко всем сервисам, которые используют одни и те же данные
Сетевой контроль доступа
Часто бывает полезно ограничить использование отдельных сервисов другими приложениями или пользователями, выполняющими разовые (ad-hoc) запросы. Это можно сделать с помощью сетевых ограничений, аналогично тому, как это сейчас настроено для обычных сервисов (перейдите в Settings на вкладке сервиса для конкретного сервиса в консоли ClickHouse Cloud).
Вы можете настроить фильтрацию по IP для каждого сервиса отдельно, что позволяет контролировать, какое приложение может обращаться к какому сервису. Это позволяет ограничивать пользователей в использовании отдельных сервисов:
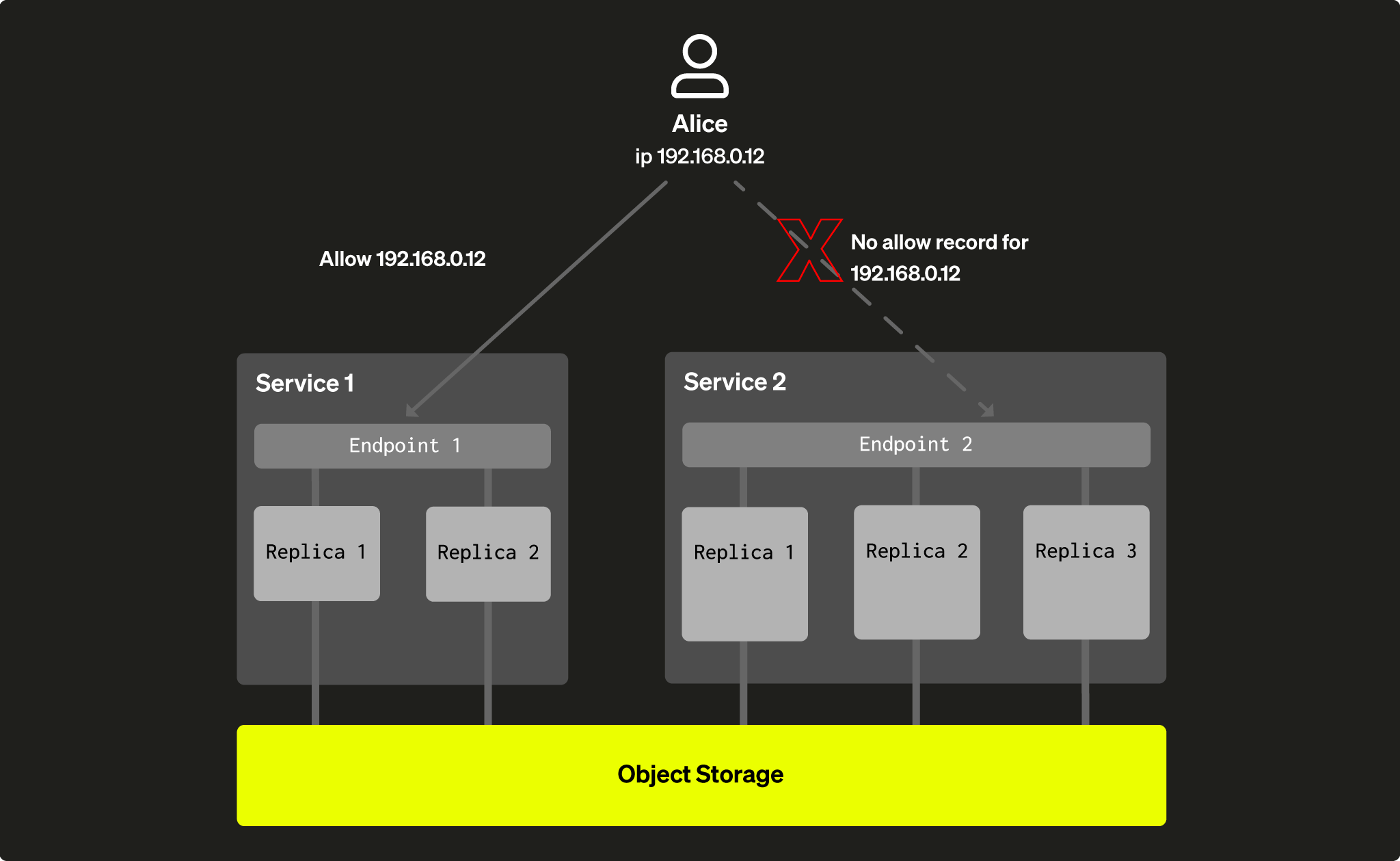
Рис. 5 — доступ Alice к Service 2 ограничен из-за сетевых настроек
Доступ на чтение и чтение-запись
Иногда полезно ограничить доступ на запись к определенному сервису и разрешить запись только для части сервисов в рамках warehouse. Это можно сделать при создании второго и последующих сервисов (первый сервис всегда должен быть с правами чтения-записи):
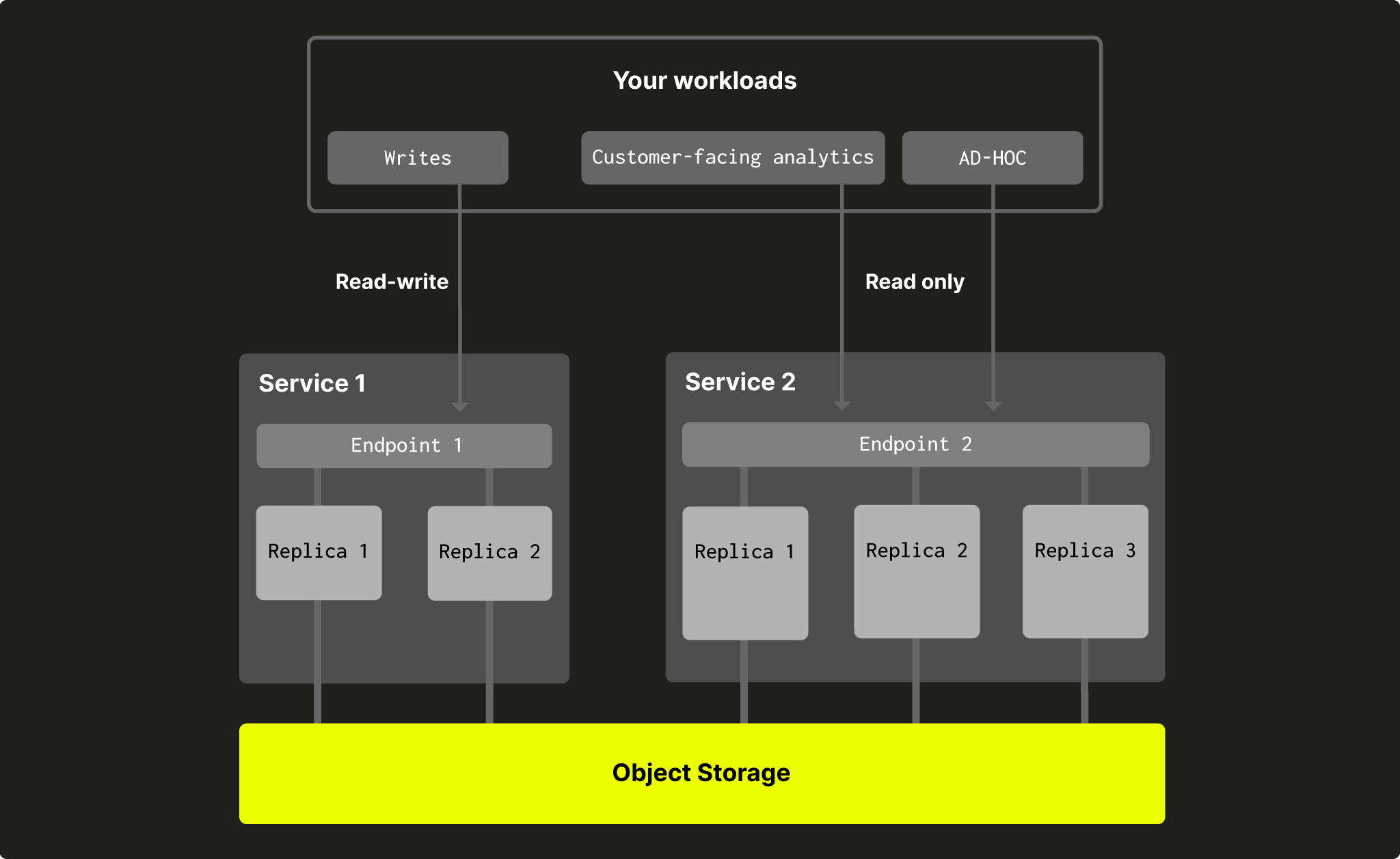
Рис. 6 — Сервисы с правами чтения-записи и только для чтения в рамках warehouse
- Сервисы только для чтения в настоящее время позволяют выполнять операции управления пользователями (create, drop и т.д.). Это поведение может быть изменено в будущем.
- В настоящее время обновляемые материализованные представления выполняются на всех сервисах в рамках warehouse, включая сервисы только для чтения. В будущем это поведение будет изменено, и они будут выполняться только на сервисах с правами чтения-записи.
Масштабирование
Каждый сервис в Warehouse можно настроить под вашу нагрузку по следующим параметрам:
- Количество узлов (реплик). Основной сервис (сервис, который был создан первым в Warehouse) должен иметь не менее двух узлов. Каждый вторичный сервис может иметь один или более узлов.
- Размер узлов (реплик)
- Нужно ли автоматически масштабировать сервис
- Нужно ли переводить сервис в режим простоя при отсутствии активности (не может быть применено к первому сервису в группе — см. раздел Ограничения)
Изменения в поведении
После того как для сервиса включён режим compute-compute (создан хотя бы один вторичный сервис), вызов функции clusterAllReplicas() с именем кластера default будет использовать только реплики того сервиса, в котором она была вызвана. Это означает, что если два сервиса подключены к одному и тому же набору данных и clusterAllReplicas(default, system, processes) вызывается из сервиса 1, будут показаны только процессы, запущенные на сервисе 1. При необходимости вы по-прежнему можете вызвать, например, clusterAllReplicas('all_groups.default', system, processes), чтобы обратиться ко всем репликам.
Ограничения
-
Основной сервис всегда должен быть запущен и не может переходить в режим простоя (это ограничение будет снято через некоторое время после GA). Во время private preview и некоторое время после GA основной сервис (обычно это существующий сервис, который вы хотите расширить, добавив другие сервисы) всегда будет работать, и для него будет отключена настройка простоя. Вы не сможете остановить или перевести в режим простоя основной сервис, если существует хотя бы один вторичный сервис. Как только все вторичные сервисы будут удалены, вы снова сможете остановить или перевести в режим простоя исходный сервис.
-
Иногда нагрузки нельзя изолировать. Хотя цель состоит в том, чтобы дать вам возможность изолировать нагрузки на базу данных друг от друга, могут существовать крайние случаи, когда одна нагрузка в одном сервисе будет затрагивать другой сервис, использующий те же данные. Это достаточно редкие ситуации, в основном связанные с OLTP-подобными нагрузками.
-
Все сервисы с возможностью чтения и записи выполняют фоновые операции слияния. При вставке данных в ClickHouse база данных сначала записывает данные во временные партиции, а затем выполняет слияния в фоновом режиме. Эти слияния могут потреблять ресурсы памяти и CPU. Когда два сервиса с возможностью чтения и записи используют одно и то же хранилище, оба выполняют фоновые операции. Это означает, что может возникнуть ситуация, когда запрос
INSERTвыполняется в Service 1, а операция слияния завершается Service 2. Обратите внимание, что сервисы только для чтения не выполняют фоновые слияния, поэтому они не расходуют свои ресурсы на эту операцию. -
Все сервисы с возможностью чтения и записи выполняют операции вставки в таблицы с движком S3Queue. При создании таблицы S3Queue на RW-сервисе все остальные RW-сервисы в WH могут читать данные из S3 и записывать данные в базу данных.
-
Вставки в одном сервисе с возможностью чтения и записи могут не дать другому сервису с возможностью чтения и записи перейти в режим простоя, если режим простоя включен. В результате второй сервис выполняет фоновые операции слияния для первого сервиса. Эти фоновые операции могут помешать второму сервису перейти в режим простоя. После завершения фоновых операций сервис будет переведен в режим простоя. Сервисы только для чтения на это не влияют и будут переводиться в режим простоя без задержки.
-
Запросы CREATE/RENAME/DROP DATABASE по умолчанию могут блокироваться сервисами в режиме простоя или остановленными сервисами. Эти запросы могут «подвисать». Чтобы обойти это, вы можете выполнять запросы управления базой данных с
settings distributed_ddl_task_timeout=0на уровне сессии или отдельного запроса. Например:
- В настоящее время действует мягкий лимит — не более 5 сервисов на один warehouse. Обратитесь в службу поддержки, если вам нужно использовать более 5 сервисов в одном warehouse.
Цены
Стоимость вычислительных ресурсов одинакова для всех сервисов в хранилище (основном и дополнительном). Хранение данных тарифицируется только один раз — оно включено в первый (исходный) сервис.
Воспользуйтесь калькулятором на странице Pricing, который поможет оценить стоимость в зависимости от размера вашей нагрузки и выбранного тарифа.
Резервные копии
- Поскольку все сервисы в одном warehouse используют одно и то же хранилище, резервные копии создаются только на основном (первичном) сервисе. Таким образом, в резервную копию попадают данные всех сервисов в этом warehouse.
- Если вы восстанавливаете резервную копию с основного сервиса warehouse, она будет развёрнута как полностью новый сервис, не связанный с существующим warehouse. Затем вы можете добавить дополнительные сервисы к этому новому сервису сразу после завершения восстановления.
Использование хранилищ
Создание хранилища
Чтобы создать хранилище, необходимо создать второй сервис, который будет совместно использовать данные с существующим сервисом. Это можно сделать, нажав значок плюса у любого из существующих сервисов:
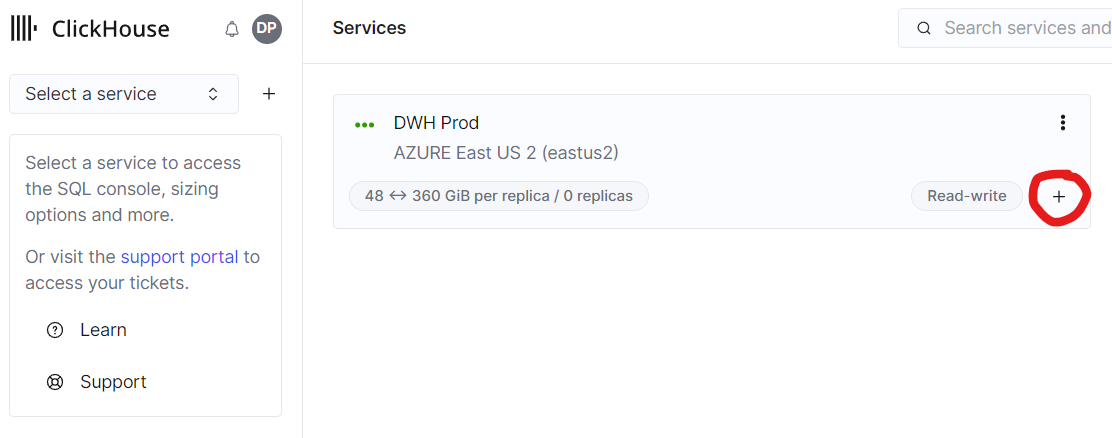
Рис. 7 — нажмите значок плюса, чтобы создать новый сервис в хранилище
На экране создания сервиса исходный сервис будет выбран в выпадающем списке как источник данных для нового сервиса. После создания эти два сервиса образуют хранилище.
Переименование хранилища
Переименовать хранилище можно двумя способами:
- Вы можете выбрать «Sort by warehouse» на странице сервисов в правом верхнем углу, а затем нажать на значок карандаша рядом с именем хранилища;
- Вы можете нажать на имя хранилища у любого из сервисов и переименовать хранилище там.
Удаление хранилища
Удаление хранилища означает удаление всех вычислительных сервисов и данных (таблиц, представлений, пользователей и т. д.). Это действие нельзя отменить. Удалить хранилище можно только через удаление первого созданного сервиса. Для этого:
- Удалите все сервисы, которые были созданы в дополнение к сервису, созданному первым;
- Удалите первый сервис (предупреждение: на этом шаге будут удалены все данные хранилища).
