Мониторинг ClickHouse Cloud
Это руководство предоставляет корпоративным командам, оценивающим ClickHouse Cloud, подробную информацию о возможностях мониторинга и наблюдаемости для продуктивных развертываний. Корпоративные клиенты часто спрашивают о встроенных возможностях мониторинга, интеграции с существующими стеками наблюдаемости, включая такие инструменты, как Datadog и AWS CloudWatch, а также о том, как возможности мониторинга ClickHouse Cloud соотносятся с развертываниями в self-hosted‑средах.
Расширенная панель наблюдения
ClickHouse Cloud предоставляет всесторонний мониторинг через встроенные панели, доступные в разделе Monitoring. Эти панели отображают системные метрики и метрики производительности в режиме реального времени без дополнительной настройки и служат основными инструментами для мониторинга боевых сред в ClickHouse Cloud.
- Advanced Dashboard: Основной интерфейс панели, доступный через Monitoring → Advanced dashboard, обеспечивает мониторинг в реальном времени показателей скорости запросов, использования ресурсов, состояния системы и производительности хранилища. Для этой панели не требуется отдельная аутентификация, она не мешает экземплярам переходить в режим простоя и не добавляет нагрузку запросами на вашу продуктивную систему. Каждая визуализация построена на настраиваемых SQL‑запросах; готовые диаграммы сгруппированы по метрикам, специфичным для ClickHouse, метрикам состояния системы и метрикам, специфичным для Cloud. Пользователи могут расширять мониторинг, создавая собственные запросы непосредственно в SQL‑консоли.
Доступ к этим метрикам не генерирует запрос к базовому сервису и не выводит из режима простоя простаивающие сервисы.
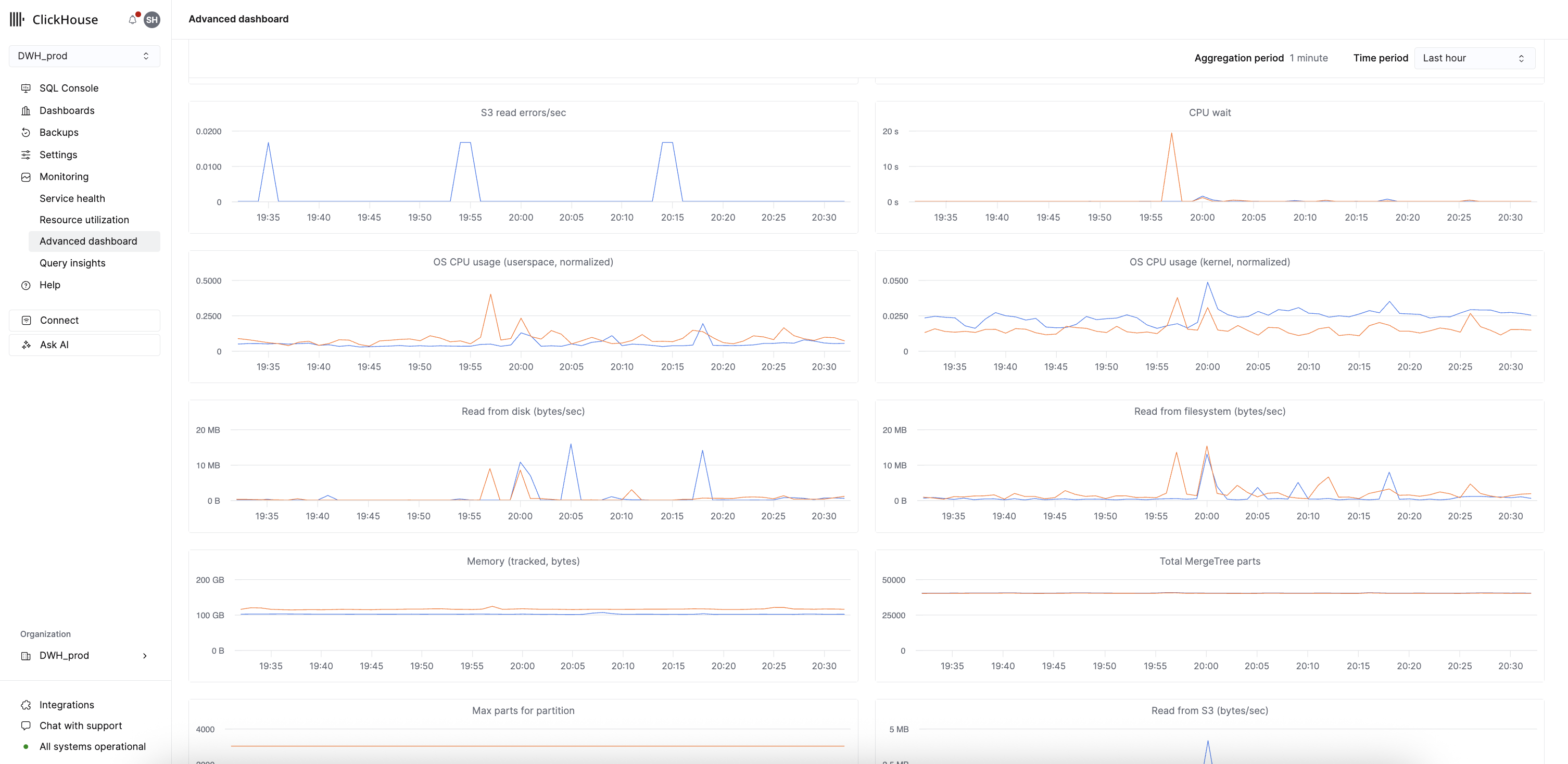
Пользователи, которые хотят расширить эти визуализации, могут использовать возможности панелей мониторинга в ClickHouse Cloud, выполняя запросы напрямую к системным таблицам.
- Native advanced dashboard: Альтернативный интерфейс панели, доступный по ссылке «You can still access the native advanced dashboard» в разделе Monitoring. Он открывается в отдельной вкладке с аутентификацией и предоставляет альтернативный интерфейс для мониторинга состояния системы и сервиса. Эта панель поддерживает расширенную аналитику, позволяя пользователям изменять базовые SQL‑запросы.
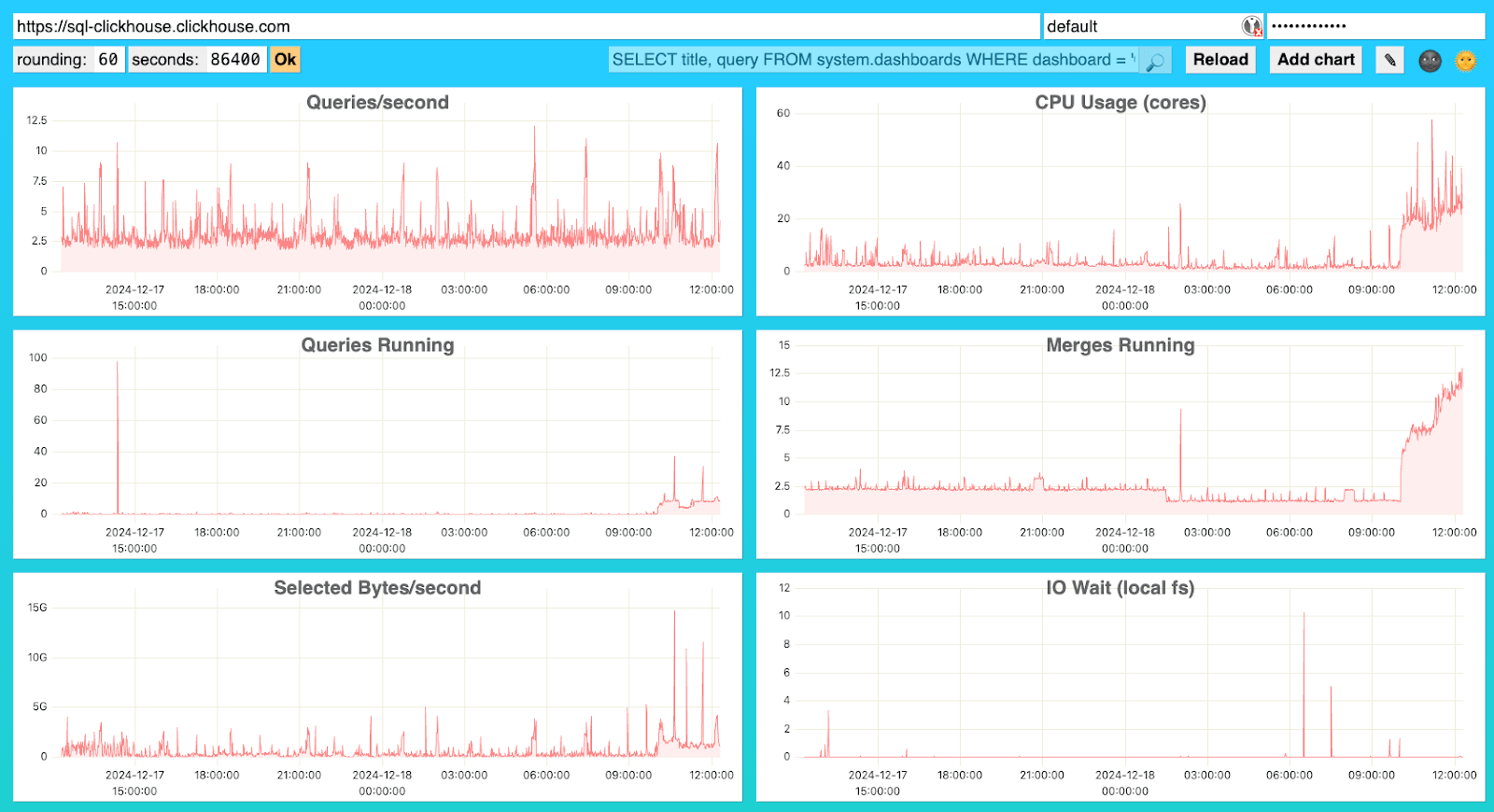
Обе панели обеспечивают оперативное представление о состоянии и производительности сервиса без внешних зависимостей, что отличает их от внешних инструментов, ориентированных на отладку, таких как ClickStack.
Подробное описание возможностей панелей и доступных метрик см. в документации по расширенной панели наблюдения.
Аналитика запросов и мониторинг ресурсов
ClickHouse Cloud включает дополнительные средства мониторинга:
- Query Insights: встроенный интерфейс для анализа производительности запросов и устранения неполадок
- Resource Utilization Dashboard: отслеживает использование памяти, распределение CPU и характер передачи данных. Графики использования CPU и памяти показывают максимальное значение соответствующей метрики за определённый период времени. График использования CPU отображает метрику загрузки CPU на уровне системы (а не метрику загрузки CPU ClickHouse).
См. документацию по аналитике запросов и использованию ресурсов для подробного описания возможностей.
Совместимая с Prometheus конечная точка метрик
ClickHouse Cloud предоставляет конечную точку, совместимую с Prometheus. Это позволяет пользователям сохранять текущие рабочие процессы, использовать существующий опыт команды и интегрировать метрики ClickHouse в корпоративные платформы мониторинга, включая Grafana, Datadog и другие инструменты, совместимые с Prometheus.
Конечная точка на уровне организации агрегирует метрики от всех сервисов, а конечные точки для отдельных сервисов обеспечивают детализированный мониторинг. Ключевые возможности включают:
- Опция фильтрации метрик: необязательный параметр
filtered_metrics=trueсокращает объём данных с более чем 1000 доступных метрик до 125 «критически важных» метрик для оптимизации затрат и упрощения мониторинга. - Кэшированная доставка метрик: использует материализованные представления, обновляемые каждую минуту, чтобы минимизировать нагрузку от запросов на производственные системы.
Этот подход учитывает поведение простаивающих сервисов, позволяя оптимизировать затраты, когда сервисы не выполняют активную обработку запросов. Эта конечная точка API использует учетные данные API ClickHouse Cloud. Полные сведения о конфигурации конечной точки смотрите в документации по Prometheus.
Примеры интеграции
Внешняя интеграция позволяет организациям сохранять сложившиеся процессы мониторинга, использовать накопленную экспертизу команд с привычными инструментами и интегрировать мониторинг ClickHouse с общей наблюдаемостью за инфраструктурой без нарушения текущих процессов и необходимости значительных затрат на переобучение. Команды могут применять существующие правила оповещений и процедуры эскалации к метрикам ClickHouse, одновременно сопоставляя производительность базы данных с состоянием приложений и инфраструктуры в рамках единой платформы наблюдаемости. Такой подход максимизирует отдачу от текущих систем мониторинга и ускоряет устранение неполадок за счет консолидированных дашбордов и знакомых интерфейсов инструментов.
Мониторинг в Grafana Cloud
Grafana обеспечивает мониторинг ClickHouse как через прямую интеграцию с помощью плагина, так и на основе подходов с использованием Prometheus. Интеграция через Prometheus-эндпоинт поддерживает операционное разделение между системами мониторинга и производственными нагрузками, одновременно позволяя визуализировать данные в существующей инфраструктуре Grafana Cloud. См. документацию Grafana по ClickHouse для получения рекомендаций по настройке.
Мониторинг в Datadog
Datadog разрабатывает специальную интеграцию через API, которая обеспечит корректный мониторинг облачных сервисов с учетом поведения простаивающих сервисов. Пока она находится в разработке, команды могут использовать подход интеграции OpenMetrics через Prometheus-эндпоинты ClickHouse для операционного разделения и экономичного мониторинга. Рекомендации по настройке см. в документации Datadog по интеграции Prometheus и OpenMetrics.
ClickStack
ClickStack является рекомендованным решением наблюдаемости для ClickHouse для глубокого анализа системы и отладки, предоставляя единую платформу для логов, метрик и трассировок с использованием ClickHouse в качестве движка хранения. Этот подход использует HyperDX, пользовательский интерфейс ClickStack, который подключается напрямую к системным таблицам внутри вашего экземпляра ClickHouse. HyperDX поставляется со специализированной для ClickHouse панелью мониторинга с вкладками Selects, Inserts и Infrastructure. Команды также могут использовать синтаксис Lucene или SQL для поиска по системным таблицам и логам, а также создавать пользовательские визуализации через Chart Explorer для детального анализа системы. Этот подход оптимален для отладки сложных проблем, анализа производительности и глубокого анализа состояния системы, а не для построения оповещений для продакшена в режиме реального времени.
Обратите внимание, что этот подход будет пробуждать простаивающие сервисы, поскольку HyperDX обращается к системным таблицам напрямую.
Варианты развертывания ClickStack
- HyperDX в ClickHouse Cloud (закрытый предварительный релиз): HyperDX можно запустить на любом сервисе ClickHouse Cloud.
- Helm: Рекомендуется для Kubernetes-сред для отладки. Поддерживает интеграцию с ClickHouse Cloud и позволяет настраивать конфигурацию для конкретной среды, лимиты ресурсов и масштабирование через
values.yaml. - Docker Compose: Разворачивает каждый компонент (ClickHouse, HyperDX, OTel collector, MongoDB) отдельно. Пользователи могут изменить compose-файл, чтобы удалить неиспользуемые компоненты при интеграции с ClickHouse Cloud, в частности ClickHouse и OTel collector.
- Только HyperDX: Автономный контейнер HyperDX.
Полный перечень вариантов развертывания и подробности архитектуры см. в документации ClickStack и руководстве по ингестии данных.
Пользователи также могут собирать метрики с Prometheus-эндпоинта ClickHouse Cloud через коллектор OpenTelemetry и пересылать их в отдельное развертывание ClickStack для визуализации.
Прямая интеграция с плагином Grafana
Плагин источника данных ClickHouse для Grafana позволяет визуализировать и исследовать данные непосредственно из ClickHouse, используя системные таблицы. Такой подход хорошо подходит для мониторинга производительности и создания настраиваемых дашбордов для детализированного анализа системы. Сведения об установке и настройке плагина см. в разделе о плагине источника данных для ClickHouse. Полное решение для мониторинга с использованием Prometheus-Grafana mix-in с преднастроенными дашбордами и правилами оповещений описано в статье Monitor ClickHouse with the new Prometheus-Grafana mix-in.
Прямая интеграция с Datadog
Datadog предлагает плагин ClickHouse Monitoring для своего агента, который напрямую запрашивает системные таблицы. Эта интеграция обеспечивает всесторонний мониторинг базы данных с учетом кластера благодаря функциональности clusterAllReplicas.
Эта интеграция не рекомендуется для развертываний ClickHouse Cloud из-за несовместимости с оптимизацией затрат при простое и операционных ограничений прокси-слоя в облаке.
Непосредственное использование системных таблиц
Пользователи могут выполнять глубокий анализ производительности запросов, подключаясь к системным таблицам ClickHouse, в частности к system.query_log, и выполняя запросы напрямую. Используя SQL-консоль или clickhouse client, команды могут выявлять медленные запросы, анализировать использование ресурсов и отслеживать характер использования по всей организации.
Анализ производительности запросов
Пользователи могут использовать журналы запросов в системных таблицах для выполнения анализа производительности запросов.
Пример запроса: Найти пять самых долгих по времени выполнения запросов по всем репликам кластера:
Решения для мониторинга от сообщества
Сообщество ClickHouse разработало комплексные решения для мониторинга, которые интегрируются с популярными стеками наблюдаемости. ClickHouse Monitoring предоставляет полноценную систему мониторинга с преднастроенными дашбордами. Этот проект с открытым исходным кодом предлагает быстрый старт для команд, которые хотят реализовать мониторинг ClickHouse на основе устоявшихся практик и проверенных конфигураций дашбордов.
Как и другие подходы к прямому мониторингу баз данных, это решение напрямую опрашивает системные таблицы ClickHouse, что не позволяет экземплярам простаивать и затрудняет оптимизацию затрат.
Соображения по влиянию на систему
Все перечисленные выше подходы в разной степени опираются либо на эндпоинты Prometheus, либо управляются ClickHouse Cloud, либо выполняют прямые запросы к системным таблицам. Последний из этих вариантов основан на выполнении запросов к продукционной службе ClickHouse. Это добавляет дополнительную нагрузку на наблюдаемую систему за счёт выполнения запросов и мешает экземплярам ClickHouse Cloud простаивать, что влияет на оптимизацию затрат. Кроме того, в случае отказа продукционной системы мониторинг также может пострадать, так как они тесно связаны. Этот подход хорошо подходит для глубокого анализа работы системы и отладки, но менее уместен для мониторинга продукционных систем в реальном времени. Учитывайте этот баланс между возможностями детального анализа системы и операционными накладными расходами при оценке прямой интеграции с Grafana по сравнению с подходами интеграции через внешние инструменты, обсуждаемыми в следующем разделе.
