JDBC connector
Этот коннектор следует использовать только в том случае, если ваши данные простые и состоят из примитивных типов данных, например int. Специфичные для ClickHouse типы, такие как map, не поддерживаются.
В наших примерах мы используем дистрибутив Kafka Connect от Confluent.
Ниже мы описываем простую установку, при которой сообщения считываются из одного Kafka-топика и вставляются в таблицу ClickHouse. Мы рекомендуем Confluent Cloud, который предоставляет щедрый бесплатный тариф для тех, у кого нет собственного Kafka-окружения.
Обратите внимание, что для коннектора JDBC требуется схема (нельзя использовать обычный JSON или CSV с JDBC-коннектором). Хотя схема может быть закодирована в каждом сообщении, настойчиво рекомендуется использовать Confluent Schema Registry, чтобы избежать связанных накладных расходов. Предоставленный скрипт вставки автоматически выводит схему из сообщений и добавляет её в реестр — таким образом, этот скрипт может быть повторно использован для других наборов данных. Предполагается, что ключи Kafka имеют тип String. Дополнительные сведения о схемах Kafka можно найти здесь.
Лицензия
JDBC Connector распространяется под Confluent Community License
Шаги
Соберите данные для подключения
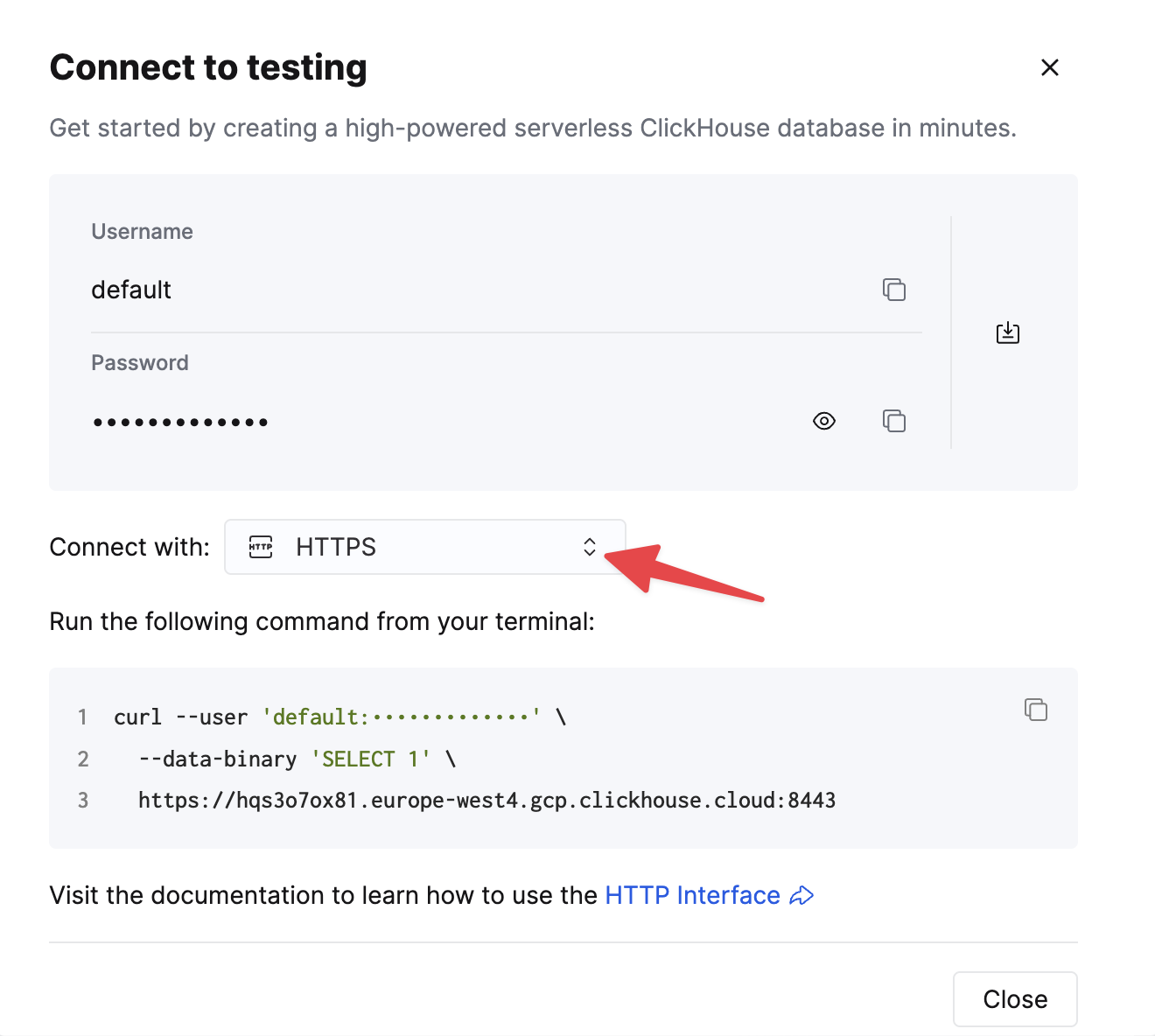
Чтобы подключиться к ClickHouse по HTTP(S), вам потребуется следующая информация:
| Параметр(ы) | Описание |
|---|---|
HOST и PORT | Обычно используется порт 8443 при использовании TLS или 8123 при отсутствии TLS. |
DATABASE NAME | По умолчанию существует база данных default; используйте имя базы данных, к которой вы хотите подключиться. |
USERNAME и PASSWORD | По умолчанию имя пользователя — default. Используйте имя пользователя, соответствующее вашему сценарию. |
Сведения о вашем сервисе ClickHouse Cloud доступны в консоли ClickHouse Cloud. Выберите сервис и нажмите Connect:
Выберите HTTPS. Параметры подключения отображаются в примере команды curl.
Если вы используете самостоятельное (self-managed) развертывание ClickHouse, параметры подключения задаются администратором ClickHouse.
1. Установите Kafka Connect и коннектор
Предполагается, что вы скачали пакет Confluent и установили его локально. Следуйте инструкциям по установке коннектора, описанным здесь.
Если вы используете метод установки через confluent-hub, ваши локальные конфигурационные файлы будут обновлены.
Для отправки данных из Kafka в ClickHouse мы используем sink-компонент коннектора.
2. Скачайте и установите JDBC-драйвер
Скачайте и установите JDBC-драйвер ClickHouse clickhouse-jdbc-<version>-shaded.jar отсюда. Установите его в Kafka Connect, следуя инструкциям здесь. Другие драйверы могут работать, но не были протестированы.
Типичная проблема: в документации предлагается скопировать JAR в share/java/kafka-connect-jdbc/. Если вы сталкиваетесь с проблемами при обнаружении драйвера Connect, скопируйте драйвер в share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/. Либо измените plugin.path, чтобы включить драйвер — см. ниже.
3. Подготовьте конфигурацию
Следуйте этим инструкциям для настройки Connect, соответствующей вашему типу установки, учитывая различия между автономным и распределённым кластером. При использовании Confluent Cloud актуальна распределённая конфигурация.
Следующие параметры важны для использования JDBC-коннектора с ClickHouse. Полный список параметров можно найти здесь:
_connection.url_- должен иметь форматjdbc:clickhouse://<clickhouse host>:<clickhouse http port>/<target database>connection.user- пользователь с правами записи в целевую базу данныхtable.name.format- таблица ClickHouse, в которую выполняется вставка данных. Таблица должна уже существовать.batch.size- количество строк, отправляемых в одном пакете. Убедитесь, что задано достаточно большое значение. Согласно рекомендациям ClickHouse минимальным следует считать значение 1000.tasks.max- коннектор JDBC Sink поддерживает запуск одной или нескольких задач. Это можно использовать для увеличения производительности. Вместе с размером пакета это ваши основные средства повышения производительности.value.converter.schemas.enable- установите в false при использовании реестра схем, в true — если вы встраиваете схемы в сообщения.value.converter- установите в соответствии с вашим типом данных, например, для JSON —io.confluent.connect.json.JsonSchemaConverter.key.converter- установитеorg.apache.kafka.connect.storage.StringConverter. Мы используем строковые ключи.pk.mode- не актуален для ClickHouse. Установите none.auto.create- не поддерживается и должен иметь значение false.auto.evolve- мы рекомендуем значение false для этого параметра, хотя поддержка может появиться в будущем.insert.mode- установите "insert". Другие режимы в настоящее время не поддерживаются.key.converter- укажите в соответствии с типами ваших ключей.value.converter- укажите на основе типа данных в вашем топике. Эти данные должны иметь поддерживаемую схему — форматы JSON, Avro или Protobuf.
Если вы используете наш пример набора данных для тестирования, убедитесь, что заданы следующие параметры:
value.converter.schemas.enable- установите в false, так как мы используем реестр схем. Установите в true, если вы встраиваете схему в каждое сообщение.key.converter- установите "org.apache.kafka.connect.storage.StringConverter". Мы используем строковые ключи.value.converter- установите "io.confluent.connect.json.JsonSchemaConverter".value.converter.schema.registry.url- укажите URL сервера реестра схем, а также учетные данные для этого сервера через параметрvalue.converter.schema.registry.basic.auth.user.info.
Примеры файлов конфигурации для тестового набора данных GitHub можно найти здесь, при условии, что Connect запускается в режиме standalone, а Kafka размещена в Confluent Cloud.
4. Создание таблицы ClickHouse
Убедитесь, что таблица создана, удалив её, если она уже существует из предыдущих примеров. Ниже приведён пример, совместимый с уменьшенным набором данных GitHub. Обратите внимание на отсутствие каких-либо типов Array или Map, которые в настоящее время не поддерживаются:
5. Запустите Kafka Connect
Запустите Kafka Connect в автономном или распределённом режиме.
6. Добавьте данные в Kafka
Отправьте сообщения в Kafka, используя предоставленные скрипт и конфигурацию. Вам нужно будет изменить файл конфигурации github.config, чтобы указать свои учетные данные Kafka. По умолчанию скрипт настроен для работы с Confluent Cloud.
Этот скрипт можно использовать для записи любого файла ndjson в топик Kafka. Он попытается автоматически вывести схему. Приведённая примерная конфигурация запишет только 10 000 сообщений — при необходимости измените здесь. Эта конфигурация также удаляет все несовместимые поля типа Array из набора данных при отправке в Kafka.
Это необходимо для того, чтобы коннектор JDBC мог преобразовывать сообщения в операторы INSERT. Если вы используете собственные данные, убедитесь, что вы либо добавляете схему к каждому сообщению (установив _value.converter.schemas.enable _в true), либо что ваш клиент публикует сообщения, ссылающиеся на схему в реестре.
Kafka Connect должен начать считывать сообщения и вставлять строки в ClickHouse. Обратите внимание, что предупреждения вида "[JDBC Compliant Mode] Transaction is not supported." являются ожидаемыми и их можно игнорировать.
Простой запрос к целевой таблице "Github" должен подтвердить, что данные были вставлены.
Рекомендуемые дополнительные материалы
- Параметры конфигурации приёмника Kafka (Kafka Sink Configuration Parameters)
- Подробный разбор Kafka Connect – JDBC Source Connector (Kafka Connect Deep Dive – JDBC Source Connector)
- Подробный разбор Kafka Connect JDBC Sink: работа с первичными ключами (Kafka Connect JDBC Sink deep-dive: Working with Primary Keys)
- Kafka Connect в действии: JDBC Sink (Kafka Connect in Action: JDBC Sink) — для тех, кто предпочитает видео чтению.
- Подробный разбор Kafka Connect – конвертеры и сериализация (Kafka Connect Deep Dive – Converters and Serialization Explained)
