Добавление данных в ClickHouse
Вставка в ClickHouse по сравнению с OLTP-базами данных
Как СУБД класса OLAP (Online Analytical Processing), ClickHouse оптимизирован для высокой производительности и масштабируемости, позволяя потенциально вставлять миллионы строк в секунду. Этого удаётся достичь за счёт сочетания высокопараллельной архитектуры и эффективного колоночного сжатия, но с компромиссами по части мгновенной согласованности. Более конкретно, ClickHouse оптимизирован для операций добавления (append-only) и предоставляет лишь гарантию сходимости к согласованному состоянию (eventual consistency).
В отличие от этого, OLTP-базы данных, такие как Postgres, специально оптимизированы для транзакционных вставок с полной поддержкой ACID, обеспечивая строгую согласованность и высокую надёжность. PostgreSQL использует MVCC (Multi-Version Concurrency Control) для обработки параллельных транзакций, что предполагает хранение нескольких версий данных. Такие транзакции могут затрагивать небольшое количество строк за один раз, при этом возникают значительные накладные расходы из‑за гарантий надёжности, ограничивающих производительность вставки.
Чтобы достичь высокой производительности вставки при сохранении строгих гарантий согласованности, пользователям следует придерживаться простых правил, описанных ниже, при вставке данных в ClickHouse. Следование этим правилам поможет избежать проблем, с которыми пользователи часто сталкиваются при первом использовании ClickHouse, пытаясь воспроизвести стратегию вставки, применимую к OLTP-базам данных.
Рекомендации по вставке данных
Вставка данных крупными батчами
По умолчанию каждая операция вставки, отправленная в ClickHouse, приводит к немедленному созданию части данных в хранилище, содержащей данные вставки вместе с другими метаданными, которые необходимо сохранить. Поэтому отправка меньшего количества вставок, каждая из которых содержит больше данных, по сравнению с отправкой большего количества вставок с меньшим объёмом данных, уменьшит количество необходимых операций записи. В целом мы рекомендуем вставлять данные достаточно крупными батчами — как минимум по 1 000 строк за раз, а в идеале от 10 000 до 100 000 строк. (Подробности см. здесь).
Если крупные батчи невозможны, используйте асинхронные вставки, описанные ниже.
Обеспечивайте однородность батчей для идемпотентных повторных попыток
По умолчанию вставки в ClickHouse являются синхронными и идемпотентными (т. е. многократное выполнение одной и той же операции вставки даёт тот же эффект, что и однократное выполнение). Для таблиц семейства движков MergeTree ClickHouse по умолчанию автоматически удаляет дубликаты при вставке.
Это означает, что вставки остаются надёжными в следующих случаях:
-
- Если у узла, принимающего данные, возникают проблемы, запрос на вставку завершится по тайм-ауту (или выдаст более конкретную ошибку) и не получит подтверждение.
-
- Если данные были записаны узлом, но подтверждение не может быть возвращено отправителю запроса из‑за сетевых сбоев, отправитель получит либо тайм-аут, либо сетевую ошибку.
С точки зрения клиента случаи (i) и (ii) могут быть трудно различимы. Однако в обоих случаях неподтверждённую вставку можно сразу же повторить. До тех пор, пока повторный запрос на вставку содержит те же данные в том же порядке, ClickHouse автоматически проигнорирует повторную вставку, если исходная (неподтверждённая) вставка была успешной.
Вставка в таблицу MergeTree или распределённую таблицу
Мы рекомендуем вставлять данные напрямую в таблицу MergeTree (или Replicated‑таблицу), распределяя запросы по набору узлов, если данные шардуются, и указывать internal_replication=true.
В этом случае ClickHouse будет самостоятельно реплицировать данные на доступные реплики шардов и обеспечит их eventual consistency.
Если балансировка нагрузки на стороне клиента неудобна, пользователи могут выполнять вставку через распределённую таблицу, которая будет распределять записи по узлам. При этом также рекомендуется задать internal_replication=true.
Однако следует учитывать, что такой подход несколько менее эффективен, поскольку данные сначала должны быть записаны локально на узле с распределённой таблицей, а затем отправлены на шарды.
Использование асинхронных вставок для небольших батчей
Существуют сценарии, в которых батчирование на стороне клиента невозможно, например сценарий наблюдаемости (observability) с сотнями или тысячами узкоспециализированных агентов, отправляющих логи, метрики, трейсы и т. д. В этом случае критически важна доставка этих данных в режиме, близком к реальному времени, чтобы как можно быстрее обнаруживать проблемы и аномалии. Кроме того, существует риск всплесков событий в наблюдаемых системах, которые при попытке буферизовать данные наблюдаемости на стороне клиента могут приводить к резким всплескам потребления памяти и связанным с этим проблемам. Если вставка крупными батчами невозможна, пользователи могут делегировать батчирование ClickHouse, используя асинхронные вставки.
При использовании асинхронных вставок данные сначала вставляются в буфер, а затем записываются в хранилище базы данных позже, в 3 шага, как показано на схеме ниже:
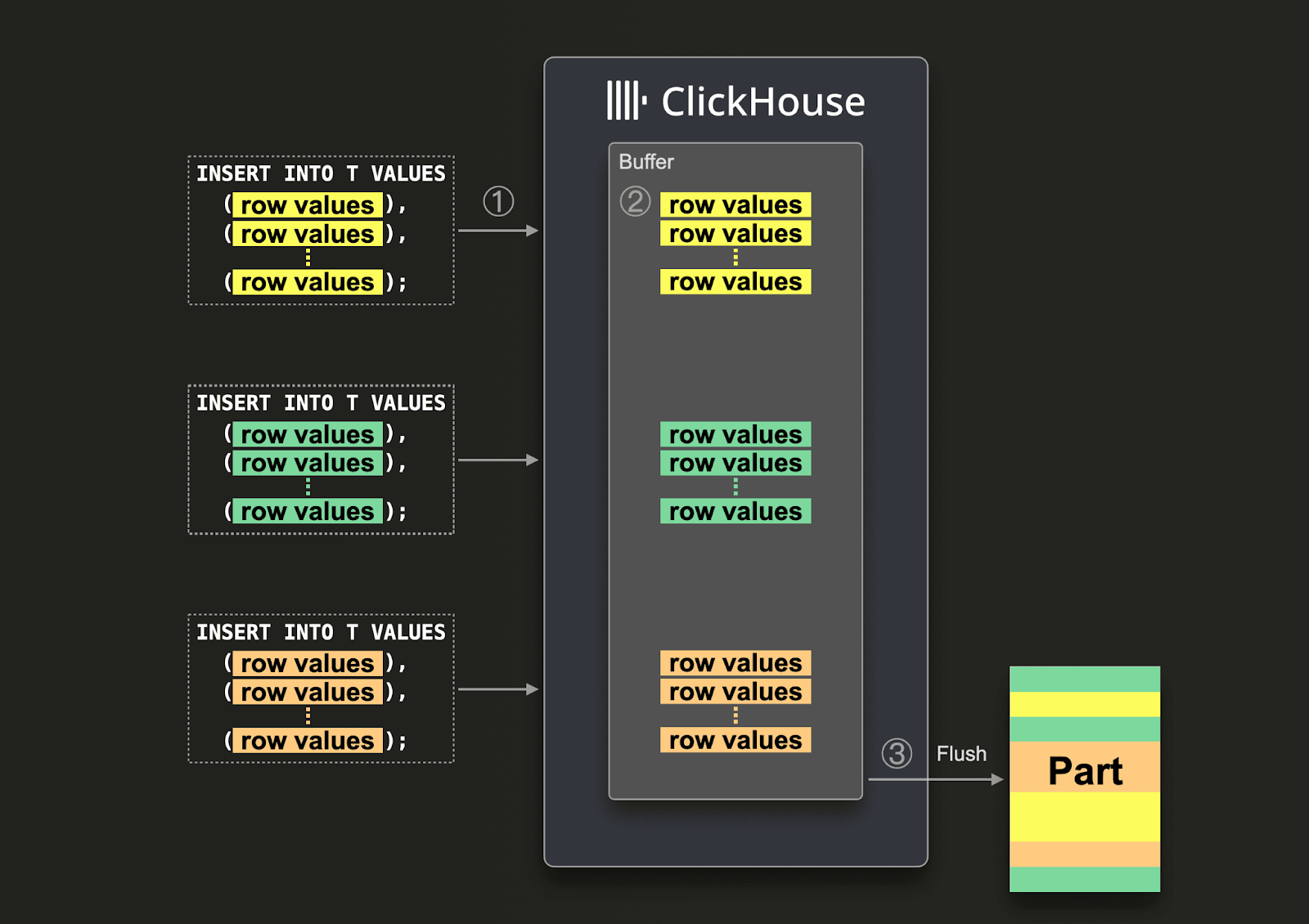
При включённых асинхронных вставках ClickHouse:
(1) асинхронно получает запрос на вставку.
(2) сначала записывает данные запроса во внутренний буфер в памяти.
(3) сортирует и записывает данные как часть в хранилище базы данных только при следующем сбросе буфера.
До того как буфер будет сброшен, в нём могут накапливаться данные других запросов асинхронной вставки от того же или других клиентов. Часть, создаваемая при сбросе буфера, потенциально будет содержать данные из нескольких запросов асинхронной вставки. В целом эти механизмы переносят батчирование данных с клиентской стороны на серверную сторону (инстанс ClickHouse).
Используйте официальные клиенты ClickHouse
Для ClickHouse доступны клиенты на наиболее популярных языках программирования. Они оптимизированы для корректного выполнения вставок и нативно поддерживают асинхронные вставки либо напрямую, как, например, Go-клиент, либо косвенно, когда они включены в настройках запроса, пользователя или соединения.
См. Clients and Drivers для полного списка доступных клиентов и драйверов ClickHouse.
Отдавайте предпочтение нативному формату
ClickHouse поддерживает множество форматов ввода во время вставки (и выполнения запросов). Это важное отличие от OLTP-баз данных и значительно упрощает загрузку данных из внешних источников — особенно в сочетании с табличными функциями и возможностью загружать данные из файлов на диске. Эти форматы идеально подходят для разовых загрузок данных и задач data engineering.
Для приложений, которые стремятся к оптимальной производительности вставок, рекомендуется выполнять вставки, используя формат Native. Он поддерживается большинством клиентов (таких как Go и Python) и обеспечивает минимальный объем работы на стороне сервера, поскольку этот формат уже столбцово-ориентирован. Таким образом, ответственность за преобразование данных в столбцово-ориентированный формат перекладывается на клиент. Это важно для эффективного масштабирования вставок.
В качестве альтернативы пользователи могут использовать формат RowBinary (используется Java-клиентом), если предпочтителен строковый формат — он обычно проще в генерации, чем формат Native. Он более эффективен с точки зрения сжатия, сетевых накладных расходов и обработки на сервере, чем альтернативные строковые форматы, такие как JSON. Формат JSONEachRow можно рассмотреть пользователям с невысокой скоростью записи, которым важно быстро интегрироваться. Пользователям следует учитывать, что этот формат создает дополнительную нагрузку на CPU в ClickHouse при разборе данных.
Используйте HTTP-интерфейс
В отличие от многих традиционных баз данных, ClickHouse поддерживает HTTP-интерфейс. Его можно использовать как для вставки, так и для выполнения запросов, применяя любой из указанных выше форматов. Часто он предпочтительнее нативного протокола ClickHouse, так как позволяет легко переключать трафик с помощью балансировщиков нагрузки. Следует ожидать небольших различий в производительности вставок по сравнению с нативным протоколом, который создает немного меньшие накладные расходы. Существующие клиенты используют один из этих протоколов (в некоторых случаях оба, например Go-клиент). Нативный протокол также позволяет легко отслеживать прогресс выполнения запроса.
См. HTTP Interface для получения более подробной информации.
Простой пример
Вы можете использовать знакомую команду INSERT INTO TABLE в ClickHouse. Давайте добавим немного данных в таблицу, которую мы создали в руководстве по началу работы "Создание таблиц в ClickHouse".
Чтобы убедиться, что всё сработало, выполните следующий запрос SELECT:
В результате будет возвращено:
Загрузка данных из Postgres
Для загрузки данных из Postgres можно использовать:
ClickPipes— ETL-инструмент, специально разработанный для репликации баз данных PostgreSQL. Доступен в следующих вариантах:- ClickHouse Cloud — через наш управляемый сервис ингестии в ClickPipes.
- Самостоятельное развёртывание — через open-source проект PeerDB.
- Движок таблиц PostgreSQL для непосредственного чтения данных, как показано в предыдущих примерах. Обычно подходит, если достаточно пакетной репликации на основе известного watermark, например временной метки, или если это одноразовая миграция. Этот подход масштабируется до десятков миллионов строк. Пользователям, которые хотят мигрировать более крупные наборы данных, следует рассмотреть несколько запросов, каждый из которых обрабатывает отдельный фрагмент данных. Для каждого фрагмента могут использоваться промежуточные таблицы до переноса его партиций в финальную таблицу. Это позволяет повторно выполнять неудачные запросы. Дополнительные сведения об этой стратегии массовой загрузки см. здесь.
- Данные можно экспортировать из PostgreSQL в формате CSV. Затем их можно загрузить в ClickHouse либо из локальных файлов, либо через объектное хранилище с использованием табличных функций.
Если вам нужна помощь с загрузкой больших наборов данных или вы сталкиваетесь с ошибками при импорте данных в ClickHouse Cloud, свяжитесь с нами по адресу support@clickhouse.com, и мы поможем.
Вставка данных из командной строки
Предварительные требования
- У вас установлен ClickHouse
clickhouse-serverзапущен- У вас есть доступ к терминалу с
wget,zcatиcurl
В этом примере показано, как вставить CSV-файл в ClickHouse из командной строки с помощью clickhouse-client в пакетном режиме. Для получения дополнительной информации и примеров вставки данных через командную строку с использованием clickhouse-client в пакетном режиме см. раздел "Batch mode".
В этом примере мы будем использовать набор данных Hacker News, который содержит 28 миллионов строк данных Hacker News.
Загрузка CSV
Выполните следующую команду, чтобы скачать CSV-версию набора данных из нашего публичного бакета S3:
При размере 4.6 GB и 28 млн строк загрузка этого сжатого файла должна занять 5–10 минут.
Создание таблицы
При запущенном clickhouse-server вы можете создать пустую таблицу со следующей схемой непосредственно из командной строки с помощью clickhouse-client в пакетном режиме:
Если ошибок нет, значит таблица успешно создана. В приведённой выше команде одинарные кавычки используются вокруг разделителя heredoc (_EOF), чтобы предотвратить интерполяцию. Без одинарных кавычек пришлось бы экранировать обратные кавычки вокруг имён столбцов.
Вставка данных из командной строки
Затем выполните следующую команду, чтобы вставить данные из ранее загруженного файла в вашу таблицу:
Поскольку наши данные сжаты, нам сначала нужно распаковать файл с помощью инструмента вроде gzip, zcat или аналогичного, а затем передать распакованные данные в clickhouse-client с соответствующим оператором INSERT и параметром FORMAT.
При вставке данных с помощью clickhouse-client в интерактивном режиме можно позволить ClickHouse обработать распаковку за вас при вставке, используя предложение COMPRESSION. ClickHouse может автоматически определить тип сжатия по расширению файла, но вы также можете указать его явно.
Запрос на вставку тогда будет выглядеть так:
Когда вставка данных завершится, вы можете выполнить следующую команду, чтобы увидеть количество строк в таблице hackernews:
Вставка данных из командной строки с помощью curl
В предыдущих шагах вы сначала скачивали CSV-файл на локальную машину с помощью wget. Также возможно напрямую вставить данные с удалённого URL одной командой.
Выполните следующую команду, чтобы очистить таблицу hackernews, чтобы вы могли вставить данные снова без промежуточного шага скачивания на локальную машину:
Теперь выполните:
Теперь вы можете выполнить ту же команду, что и ранее, чтобы убедиться, что данные были вставлены снова:
