Как работает оптимизация PREWHERE?
Предложение PREWHERE — это оптимизация выполнения запроса в ClickHouse. Она уменьшает объём операций ввода-вывода и ускоряет выполнение запроса, избегая ненужного чтения данных и отфильтровывая лишние данные до чтения со встроенного диска столбцов, не участвующих в фильтрации.
В этом руководстве объясняется, как работает PREWHERE, как измерить его влияние и как настроить его для наилучшей производительности.
Обработка запроса без оптимизации PREWHERE
Рассмотрим, как обрабатывается запрос к таблице uk_price_paid_simple без использования PREWHERE:

① В запросе используется фильтр по столбцу town, который является частью первичного ключа таблицы и, следовательно, также частью первичного индекса.
② Для ускорения запроса ClickHouse загружает первичный индекс таблицы в память.
③ Индексные записи просматриваются, чтобы определить, какие гранулы столбца town могут содержать строки, удовлетворяющие условию.
④ Эти потенциально подходящие гранулы загружаются в память вместе с позиционно выровненными гранулами из всех других столбцов, необходимых для запроса.
⑤ Оставшиеся фильтры затем применяются во время выполнения запроса.
Как видно, без PREWHERE все потенциально подходящие столбцы загружаются до фильтрации, даже если фактически совпадает лишь небольшое количество строк.
Как PREWHERE повышает эффективность запросов
Следующие анимации показывают, как приведённый выше запрос обрабатывается с предложением PREWHERE, применённым ко всем предикатам запроса.
Первые три шага обработки такие же, как и раньше:

① Запрос содержит фильтр по столбцу town, который является частью первичного ключа таблицы — а значит, также частью первичного индекса.
② Аналогично запуску без предложения PREWHERE, чтобы ускорить запрос, ClickHouse загружает первичный индекс в память,
③ затем сканирует записи индекса, чтобы определить, какие гранулы из столбца town могут содержать строки, удовлетворяющие предикату.
Теперь, благодаря предложению PREWHERE, следующий шаг отличается: вместо того чтобы заранее читать все нужные столбцы, ClickHouse фильтрует данные по столбцам, загружая только то, что действительно нужно. Это значительно сокращает объём I/O, особенно для «широких» таблиц.
На каждом шаге он загружает только те гранулы, которые содержат хотя бы одну строку, «пережившую», то есть удовлетворившую, предыдущий фильтр. В результате количество гранул, которые нужно загрузить и проверить для каждого следующего фильтра, монотонно уменьшается:
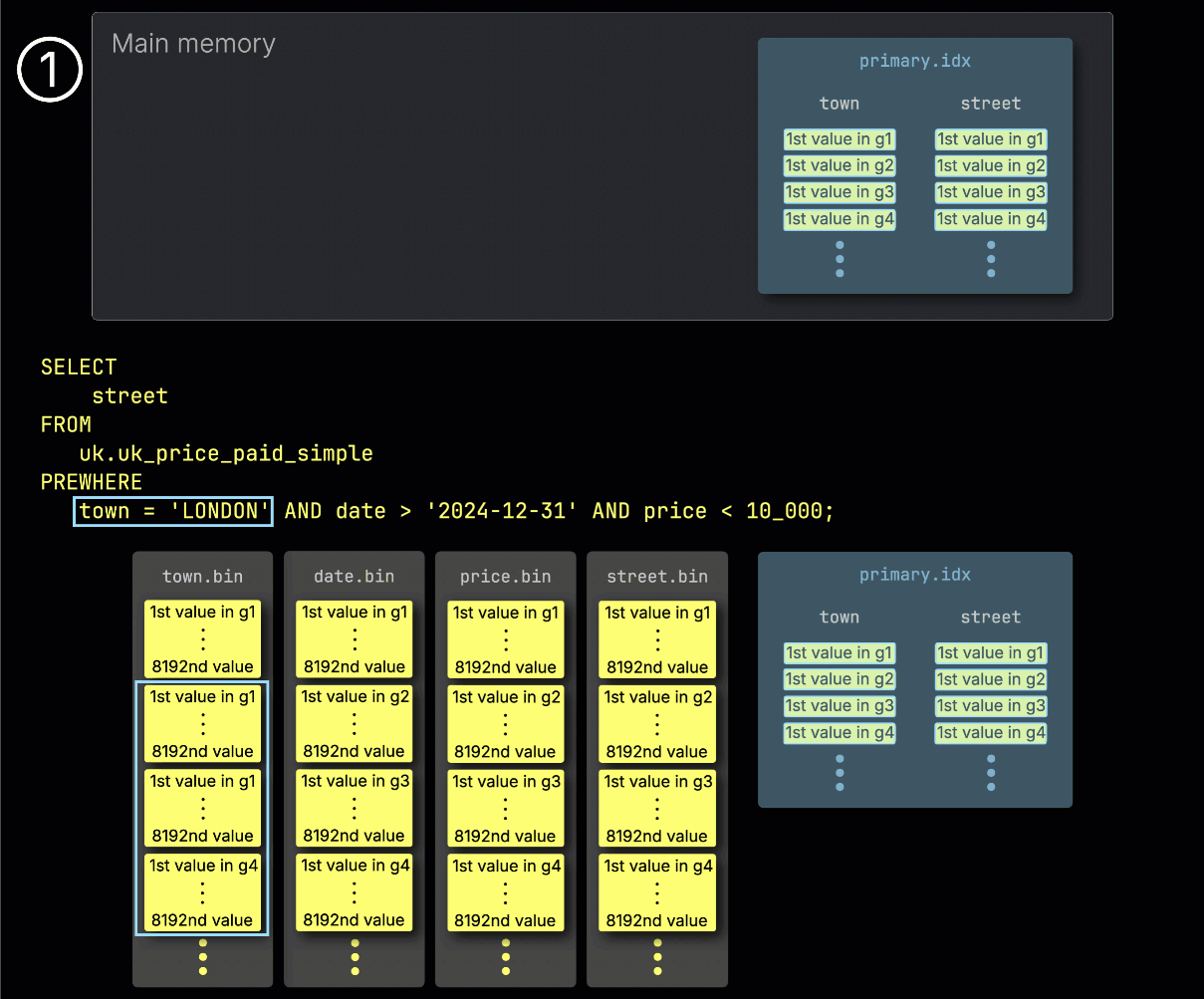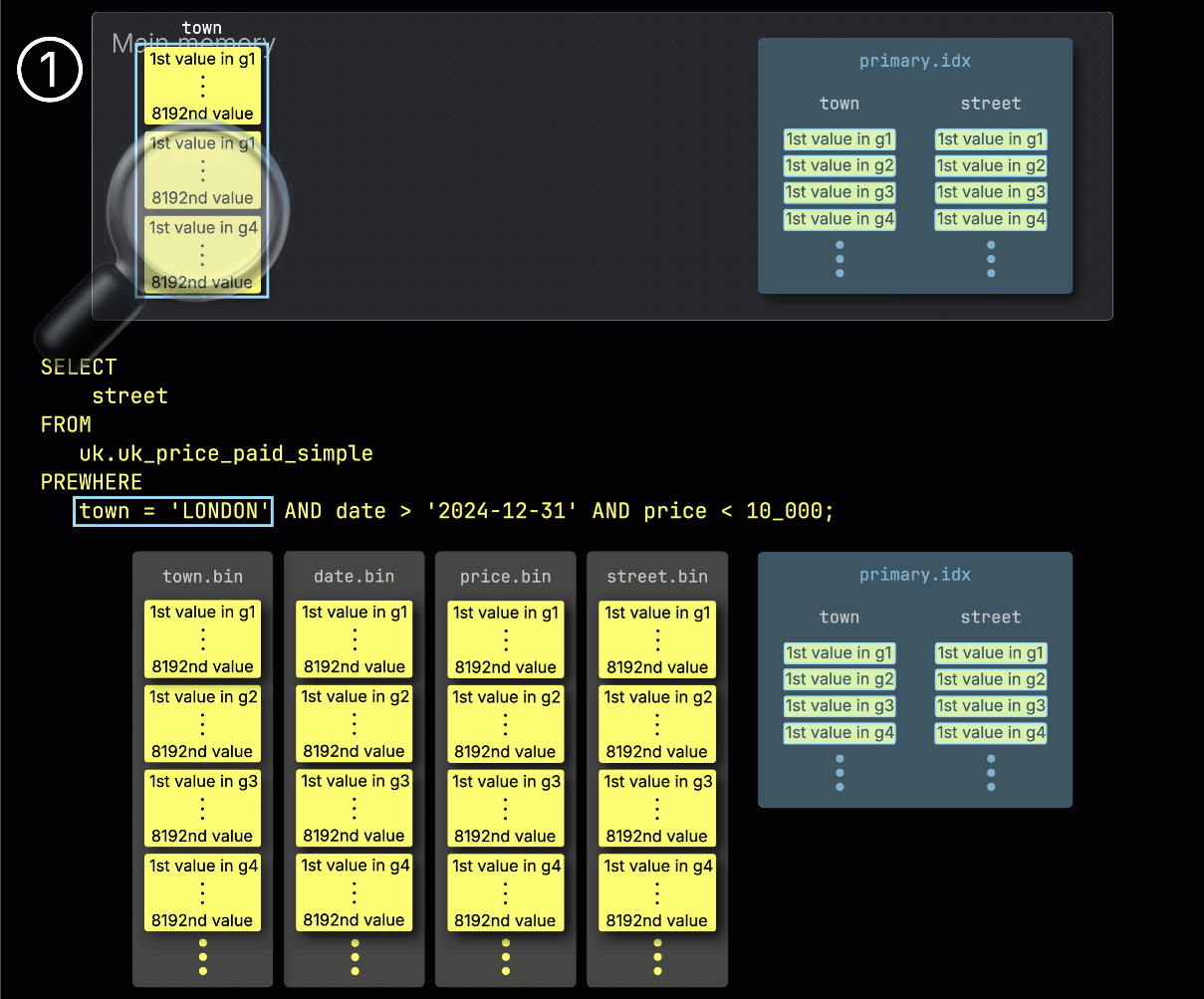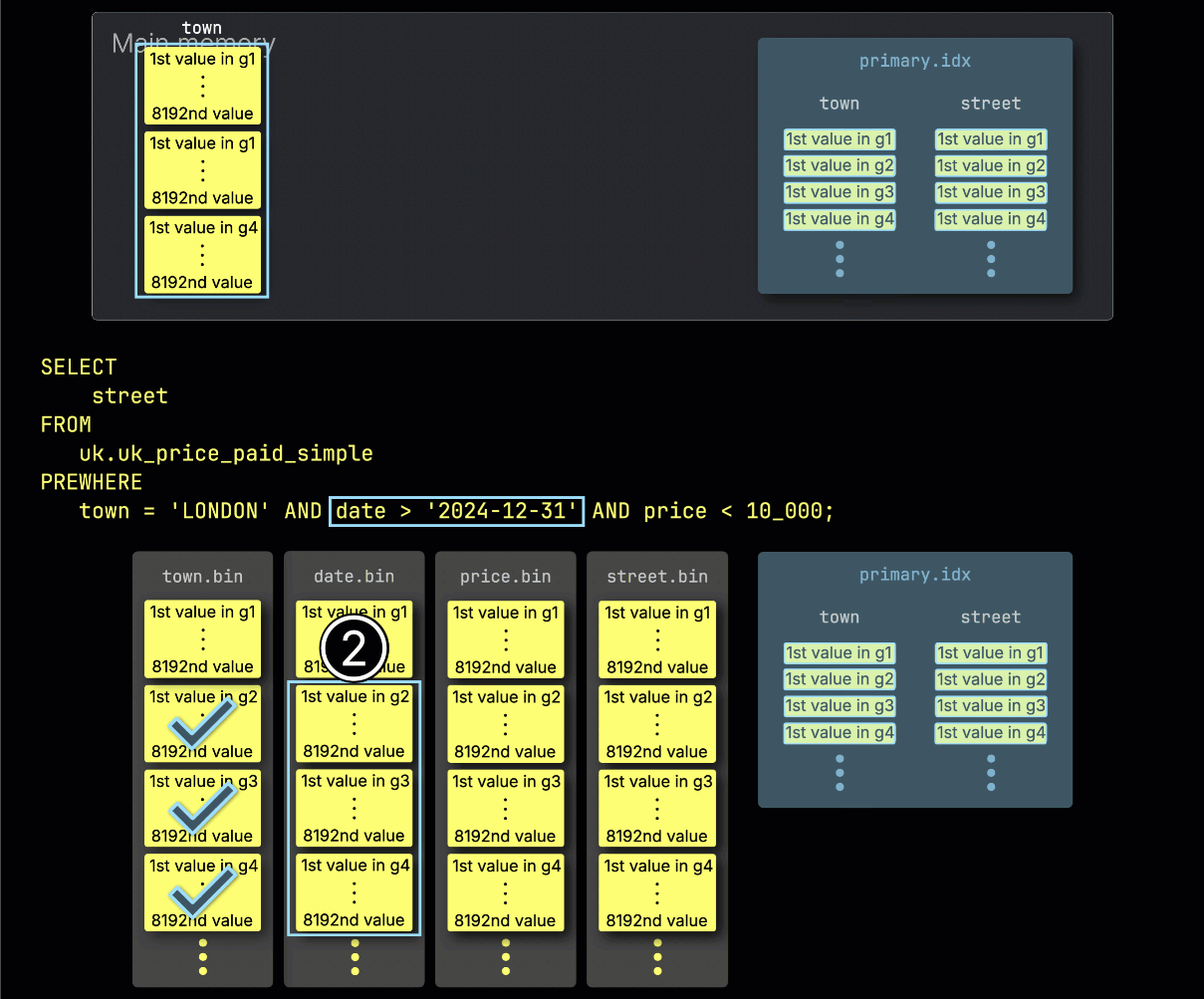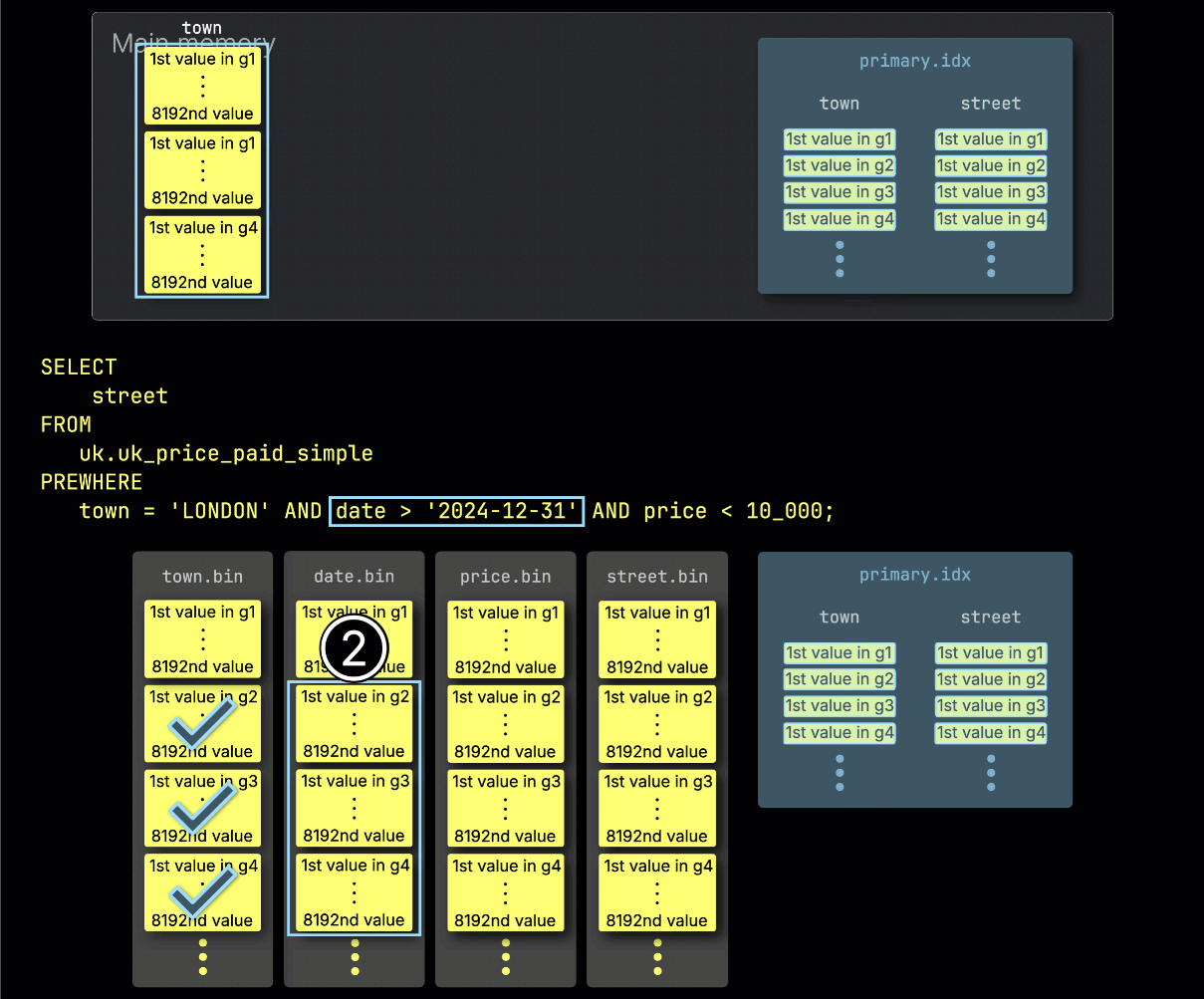
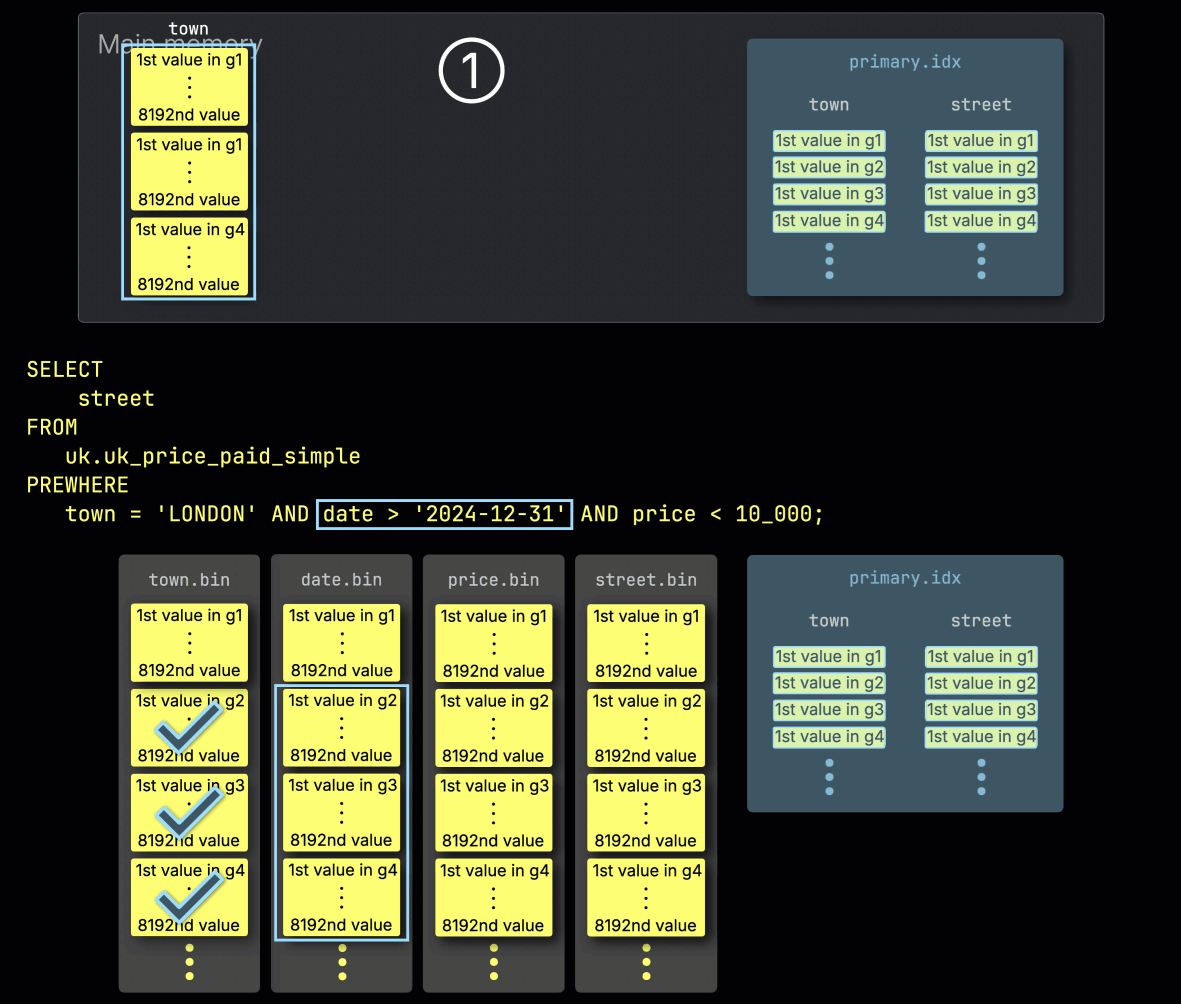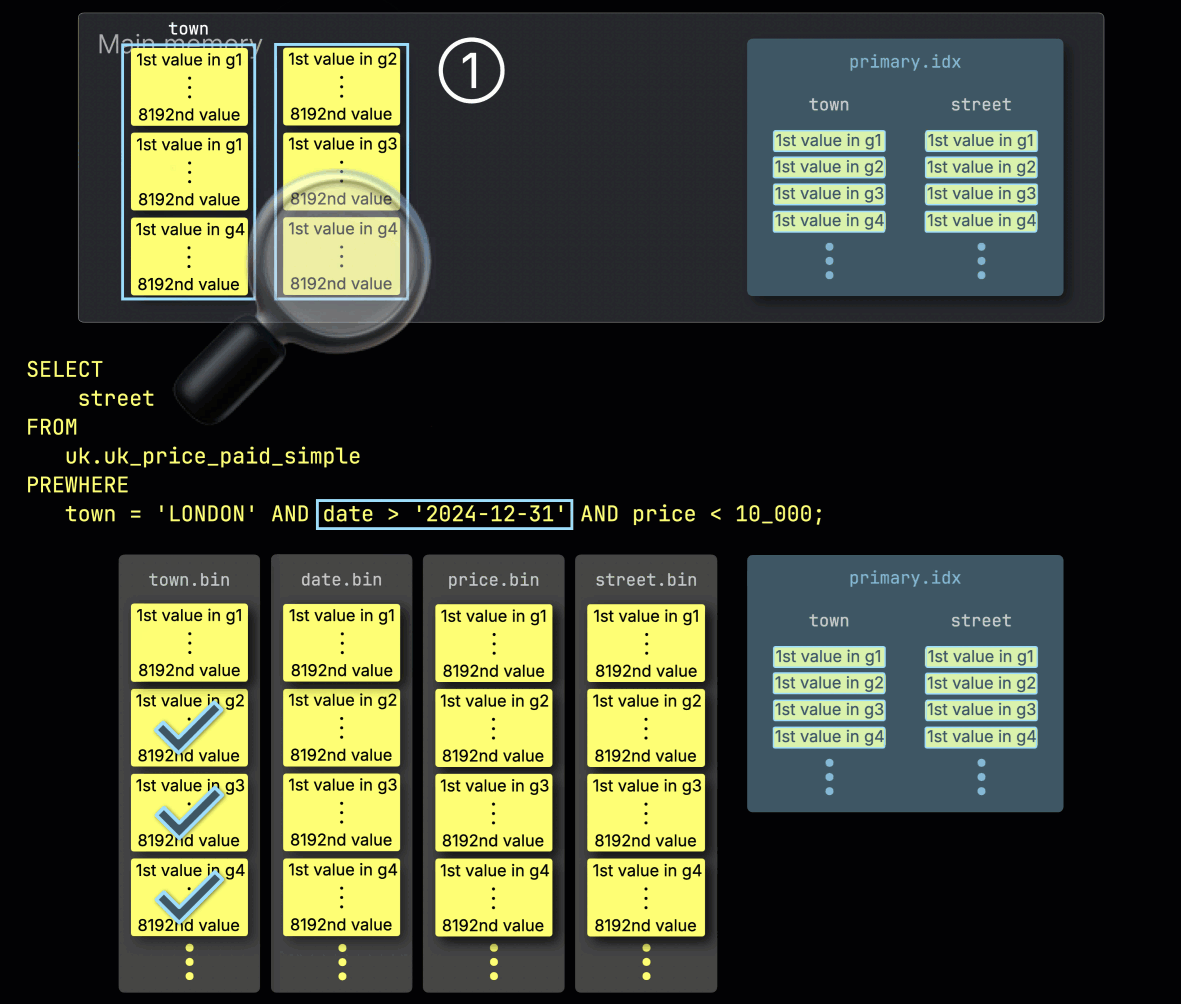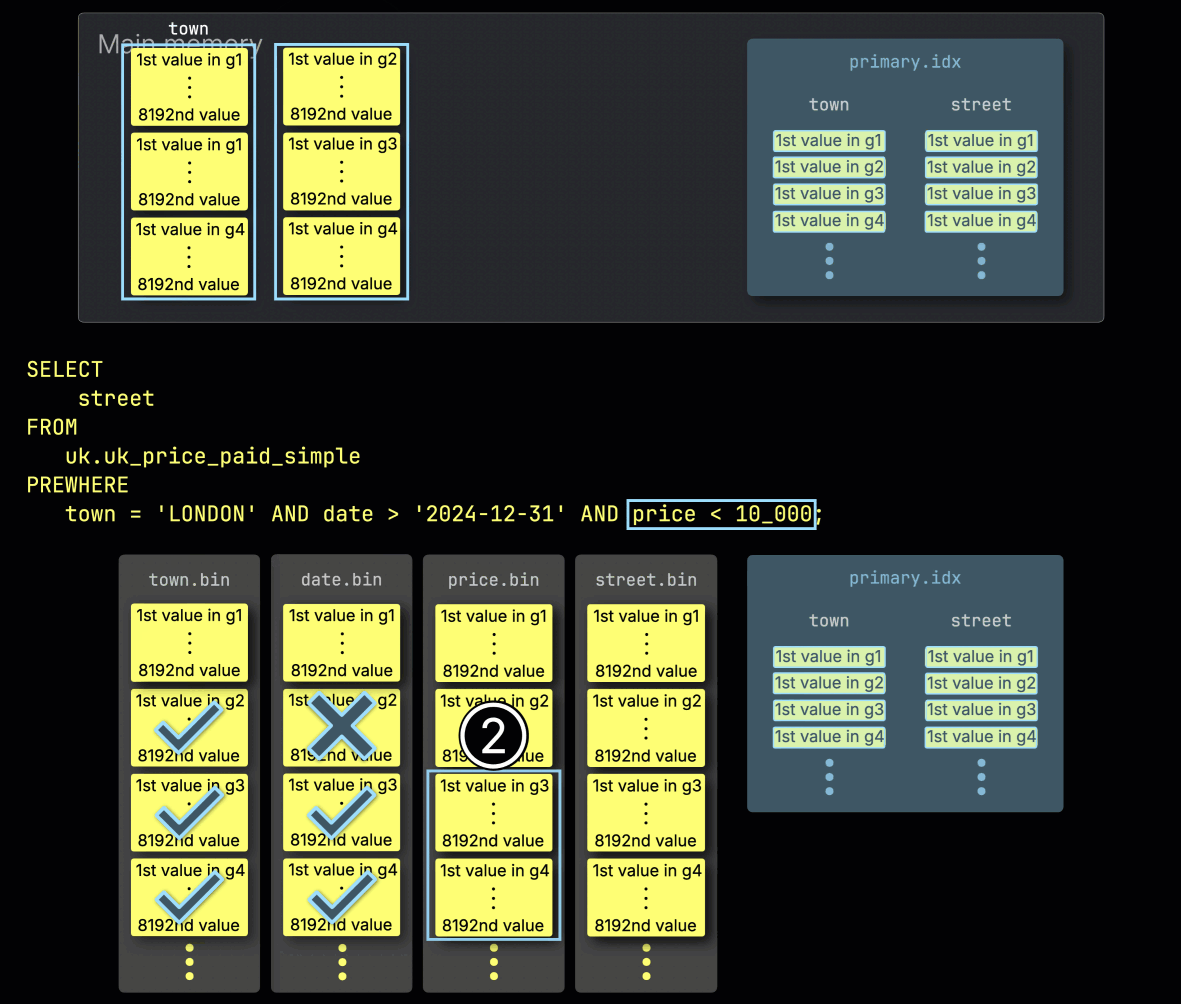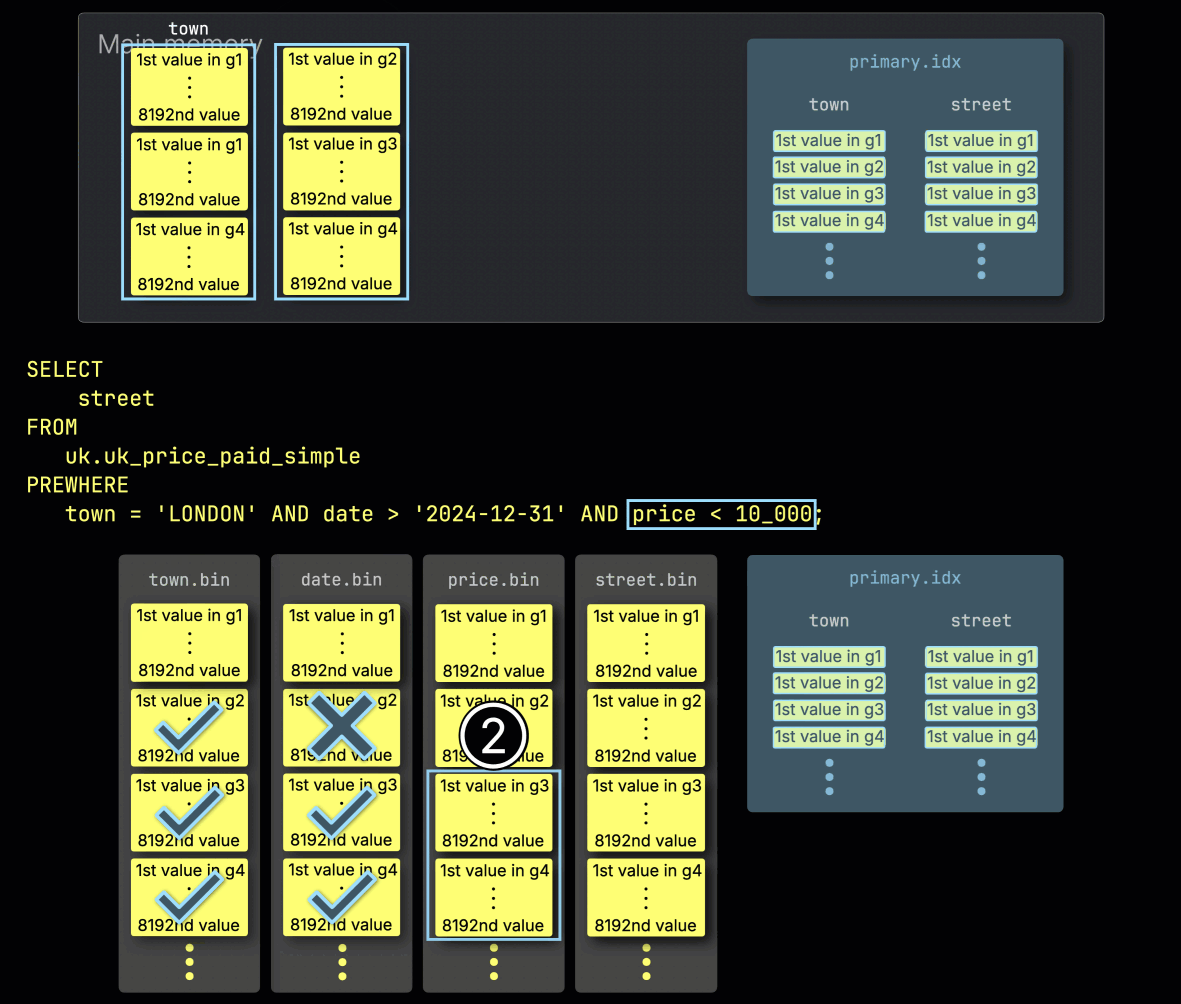
Шаг 1: Фильтрация по town
ClickHouse начинает обработку PREWHERE, ① читая выбранные гранулы из столбца town и проверяя, какие из них действительно содержат строки, соответствующие значению London.
В нашем примере все выбранные гранулы содержат такие строки, поэтому ② для обработки выбираются соответствующие позиционно выровненные гранулы следующего столбца фильтра — date:
Шаг 2: Фильтрация по date
Далее ClickHouse ① читает выбранные гранулы столбца date, чтобы применить фильтр date > '2024-12-31'.
В этом случае две из трёх гранул содержат подходящие строки, поэтому ② для дальнейшей обработки выбираются только их позиционно выровненные гранулы из следующего столбца фильтра — price:
Шаг 3: Фильтрация по price
Наконец, ClickHouse ① читает две выбранные гранулы из столбца price, чтобы применить последний фильтр price > 10_000.
Только одна из двух гранул содержит подходящие строки, поэтому ② для дальнейшей обработки нужно загрузить лишь её позиционно выровненную гранулу из столбца из списка SELECT — street:

К финальному шагу загружается только минимальный набор гранул столбцов, содержащих подходящие строки. Это приводит к меньшему потреблению памяти, снижению дисковых операций I/O и более быстрой обработке запроса.
Обратите внимание, что ClickHouse обрабатывает одинаковое количество строк как в варианте запроса с PREWHERE, так и без него. Однако при применении оптимизаций PREWHERE нет необходимости загружать значения всех столбцов для каждой обрабатываемой строки.
Оптимизация PREWHERE применяется автоматически
Предложение PREWHERE можно добавить вручную, как показано в примере выше. Однако нет необходимости указывать PREWHERE вручную. Когда настройка optimize_move_to_prewhere включена (по умолчанию true), ClickHouse автоматически переносит условия фильтрации из WHERE в PREWHERE, отдавая приоритет тем, которые сильнее всего уменьшают объём чтения.
Идея заключается в том, что меньшие по размеру столбцы сканируются быстрее, и к тому моменту, когда обрабатываются более крупные столбцы, большинство гранул уже отфильтровано. Поскольку все столбцы содержат одинаковое количество строк, размер столбца в первую очередь определяется его типом данных — например, столбец типа UInt8 обычно значительно меньше, чем столбец типа String.
Начиная с версии 23.2 ClickHouse по умолчанию следует этой стратегии, сортируя столбцы фильтра PREWHERE для многошаговой обработки в порядке возрастания их несжатого размера.
Начиная с версии 23.11, дополнительная статистика по столбцам позволяет ещё больше улучшить это поведение, выбирая порядок применения фильтров на основе фактической селективности данных, а не только размера столбца.
Как измерить влияние PREWHERE
Чтобы убедиться, что PREWHERE действительно ускоряет ваши запросы, вы можете сравнить их производительность с включённой и выключенной настройкой optimize_move_to_prewhere.
Сначала выполним запрос с отключённой настройкой optimize_move_to_prewhere:
ClickHouse прочитал 23.36 MB столбцовых данных при обработке 2.31 миллиона строк при выполнении запроса.
Далее мы выполняем запрос с включённой настройкой optimize_move_to_prewhere. (Обратите внимание, что эта настройка необязательна, так как включена по умолчанию):
Было обработано то же количество строк (2,31 миллиона), но благодаря PREWHERE ClickHouse прочитал более чем в три раза меньше столбцовых данных — всего 6,74 МБ вместо 23,36 МБ, — что сократило общее время выполнения в 3 раза.
Чтобы глубже понять, как ClickHouse применяет PREWHERE, используйте EXPLAIN и логи трассировки.
Мы изучаем логический план запроса с помощью предложения EXPLAIN:
Здесь мы опускаем большую часть вывода плана, так как он довольно объёмен. По сути, он показывает, что все три предиката по столбцам были автоматически перенесены в PREWHERE.
Когда вы будете воспроизводить это самостоятельно, вы также увидите в плане запроса, что порядок этих предикатов определяется размерами типов данных столбцов. Поскольку мы не включили статистику по столбцам, ClickHouse использует размер как запасной критерий для определения порядка обработки в PREWHERE.
Если вы хотите заглянуть ещё глубже во внутреннее устройство, вы можете наблюдать каждый отдельный шаг обработки PREWHERE, попросив ClickHouse вернуть все лог-записи уровня test во время выполнения запроса:
Ключевые выводы
- PREWHERE позволяет не считывать данные столбцов, которые позже будут отфильтрованы, экономя I/O и память.
- PREWHERE применяется автоматически, когда включен параметр
optimize_move_to_prewhere(по умолчанию). - Порядок фильтрации имеет значение: сначала должны идти небольшие и селективные столбцы.
- Используйте
EXPLAINи логи, чтобы проверить, что PREWHERE применяется, и понять его эффект. - PREWHERE оказывает наибольшее влияние на широкие таблицы и масштабные чтения с селективными фильтрами.
