Использование операторов JOIN в ClickHouse
ClickHouse имеет полную поддержку JOIN с широким выбором алгоритмов соединения. Для максимальной производительности рекомендуется следовать рекомендациям по оптимизации соединений, перечисленным в этом руководстве.
- Для оптимальной производительности пользователям следует стремиться сократить количество
JOINв запросах, особенно для аналитических нагрузок в реальном времени, где требуется время отклика на уровне миллисекунд. Старайтесь ограничиваться максимум 3–4JOINв запросе. Мы подробно рассматриваем ряд подходов, позволяющих минимизировать количествоJOIN, в разделе моделирования данных, включая денормализацию, словари и материализованные представления. - В настоящее время ClickHouse не меняет порядок соединений. Следите за тем, чтобы на правой стороне
JOINвсегда находилась наименьшая таблица. Она будет удерживаться в памяти для большинства алгоритмов соединения, что обеспечит минимальные накладные расходы по памяти для запроса. - Если в вашем запросе требуется прямое соединение, т. е.
LEFT ANY JOIN, как показано ниже, мы рекомендуем по возможности использовать Dictionaries.
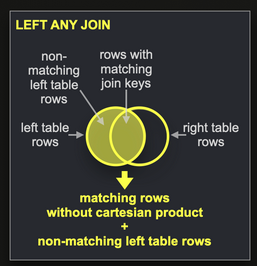
- При выполнении внутренних соединений (
INNER JOIN) часто более эффективно записывать их как подзапросы с использованием выраженияIN. Рассмотрим следующие запросы, которые функционально эквивалентны. Оба находят количествоposts, которые не упоминают ClickHouse в вопросе, но упоминают его вcomments.
Обратите внимание, что мы используем ANY INNER JOIN, а не просто INNER JOIN, так как не хотим получать декартово произведение — нам нужно только одно совпадение для каждого поста.
Этот JOIN можно переписать в виде подзапроса, что значительно улучшит производительность:
Хотя ClickHouse пытается протолкнуть условия во все выражения JOIN и подзапросы, мы рекомендуем всегда вручную применять условия ко всем частям запроса, где это возможно — тем самым минимизируя объём данных для JOIN. Рассмотрим следующий пример, где мы хотим вычислить количество голосов «за» для постов, связанных с Java, начиная с 2020 года.
Наивный запрос, с более крупной таблицей слева, выполняется за 56 секунд:
1 row in set. Elapsed: 56.642 sec. Processed 252.30 million rows, 1.62 GB (4.45 million rows/s., 28.60 MB/s.)
Добавление фильтра в левую таблицу ещё больше повышает производительность — до 0,5 с.
Этот запрос можно ещё больше улучшить, перенеся INNER JOIN во вложенный запрос, как уже отмечалось ранее, при этом сохранив фильтр во внешнем и во внутреннем запросах.
Выбор алгоритма JOIN
ClickHouse поддерживает ряд алгоритмов соединения. Эти алгоритмы, как правило, представляют собой компромисс между потреблением памяти и производительностью. Ниже приведён обзор алгоритмов JOIN в ClickHouse с точки зрения их относительного потребления памяти и времени выполнения:
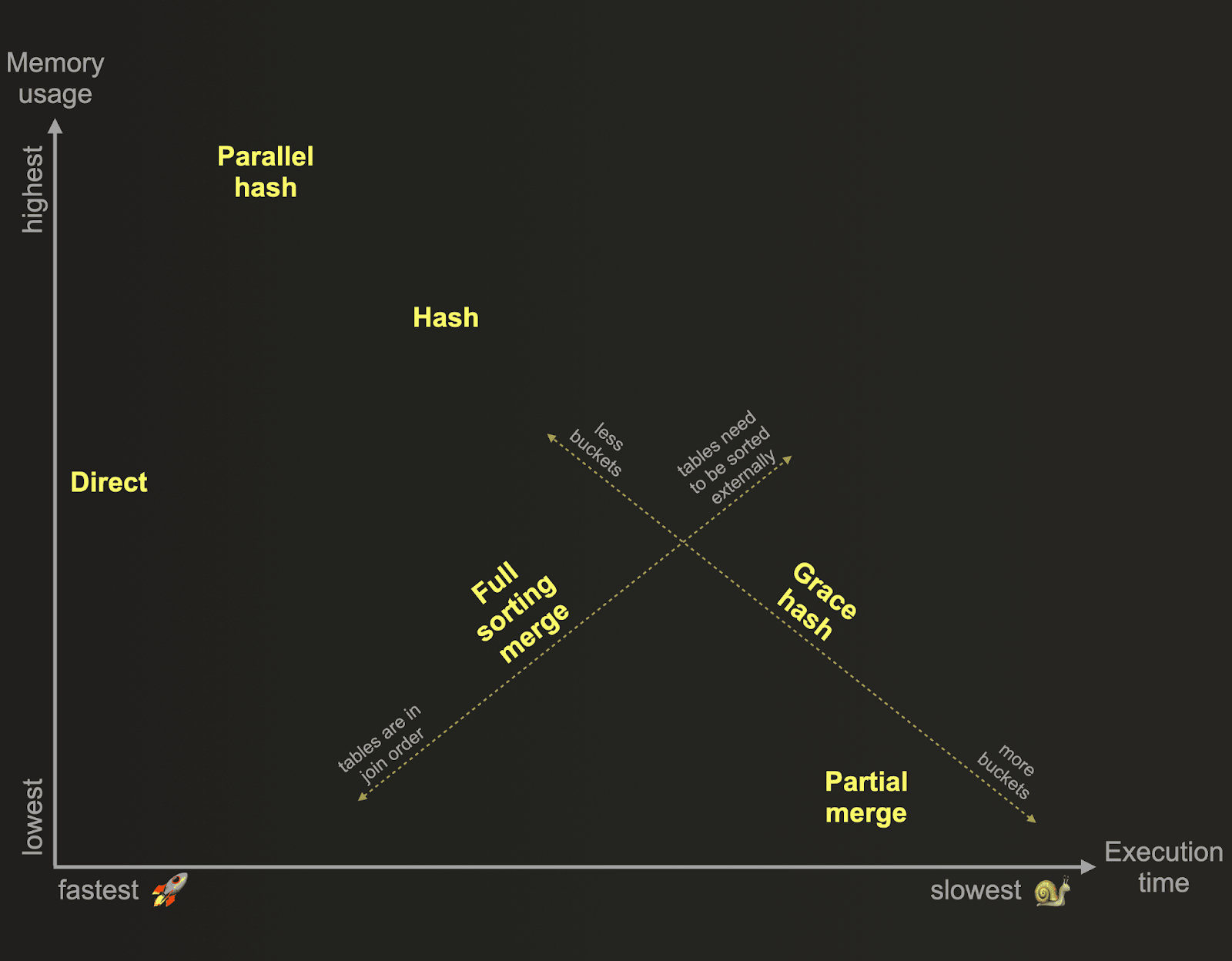
Эти алгоритмы определяют, каким образом запрос JOIN планируется и выполняется. По умолчанию ClickHouse использует алгоритм прямого или хеш-соединения в зависимости от типа и строгости JOIN, а также движка присоединяемых таблиц. В качестве альтернативы ClickHouse можно настроить на адаптивный выбор и динамическую смену алгоритма JOIN во время выполнения в зависимости от доступности и использования ресурсов: когда join_algorithm=auto, ClickHouse сначала пробует алгоритм хеш-соединения, и если лимит памяти для этого алгоритма превышен, он на лету переключается на частичный merge join. Отследить, какой алгоритм был выбран, можно по трассировочному логированию. ClickHouse также позволяет пользователям самостоятельно указать требуемый алгоритм JOIN с помощью настройки join_algorithm.
Поддерживаемые типы JOIN для каждого алгоритма JOIN показаны ниже и должны учитываться при оптимизации:
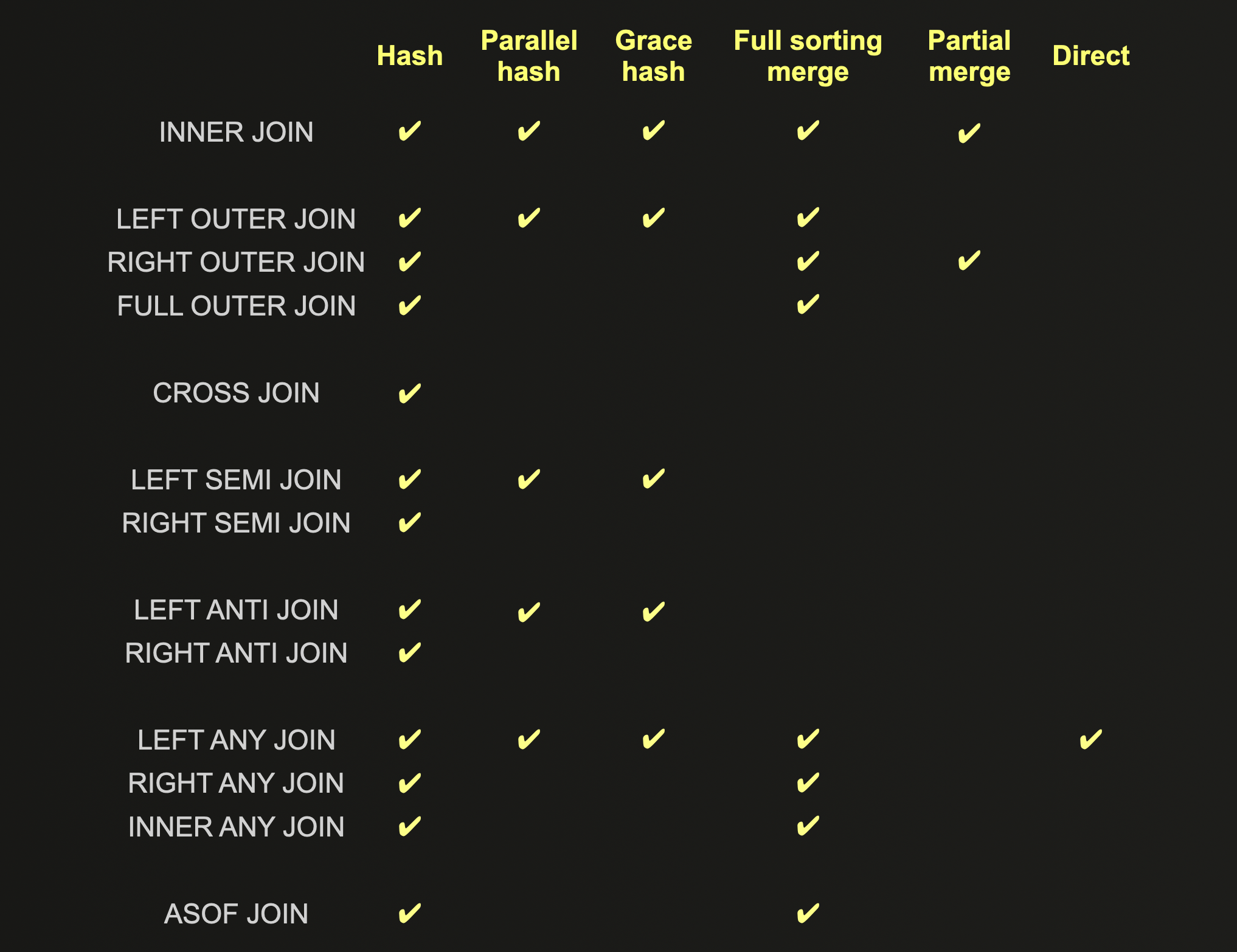
Полное подробное описание каждого алгоритма JOIN можно найти здесь, включая их преимущества, недостатки и характеристики масштабируемости.
Выбор подходящего алгоритма JOIN зависит от того, хотите ли вы оптимизировать по памяти или по производительности.
Оптимизация производительности JOIN
Если вашим основным показателем оптимизации является производительность и вы хотите выполнить JOIN как можно быстрее, вы можете использовать следующую блок-схему для выбора подходящего алгоритма JOIN:
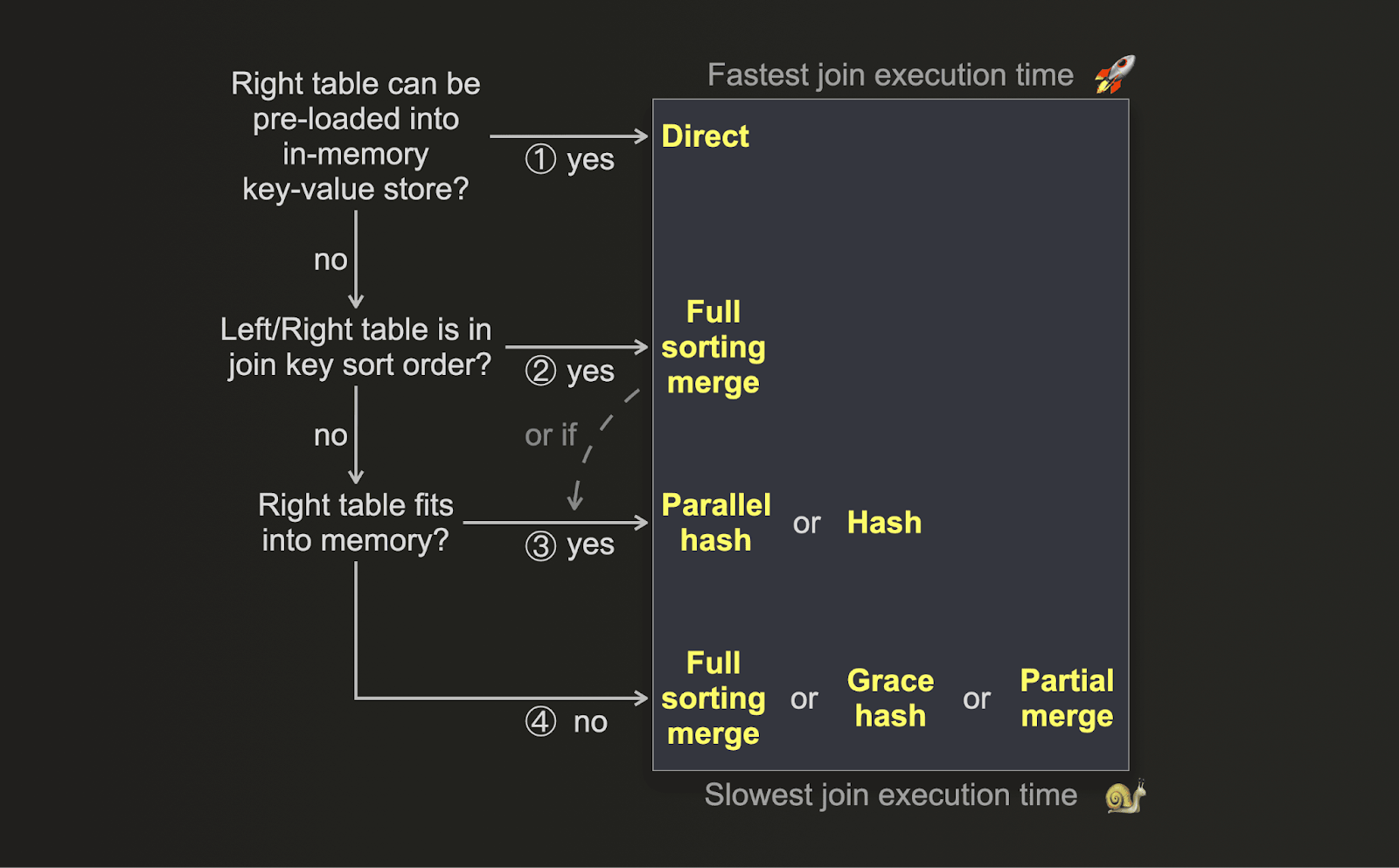
-
(1) Если данные из правой таблицы можно заранее загрузить в расположенную в памяти key-value структуру данных с низкой задержкой, например словарь, и если ключ JOIN совпадает с ключевым атрибутом базового key-value хранилища, и если семантика
LEFT ANY JOINявляется достаточной — тогда можно применять direct join, который обеспечивает наивысшую скорость. -
(2) Если физический порядок строк в вашей таблице совпадает с порядком сортировки по ключу JOIN, то всё зависит от ситуации. В этом случае full sorting merge join пропускает фазу сортировки, что приводит к существенно меньшему использованию памяти и, в зависимости от объёма данных и распределения значений ключа JOIN, к более быстрому выполнению, чем некоторые алгоритмы hash join.
-
(3) Если правая таблица помещается в память, даже с учётом дополнительных накладных расходов по памяти у parallel hash join, то этот алгоритм или hash join могут быть быстрее. Это зависит от объёма данных, типов данных и распределения значений по столбцам ключа JOIN.
-
(4) Если правая таблица не помещается в память, то снова всё зависит от ситуации. ClickHouse предлагает три алгоритма JOIN, не ограниченных объёмом оперативной памяти. Все три временно выгружают данные на диск. Full sorting merge join и partial merge join требуют предварительной сортировки данных. Grace hash join вместо этого строит по данным хеш-таблицы. В зависимости от объёма данных, типов данных и распределения значений по столбцам ключа JOIN возможны сценарии, когда построение хеш-таблиц по данным быстрее, чем сортировка данных, и наоборот.
Partial merge join оптимизирован для минимизации использования памяти при объединении больших таблиц — ценой скорости выполнения JOIN, которая получается довольно низкой. Это особенно заметно, когда физический порядок строк в левой таблице не совпадает с порядком сортировки по ключу JOIN.
Grace hash join является наиболее гибким из трёх алгоритмов JOIN, не ограниченных объёмом памяти, и обеспечивает хороший контроль баланса между использованием памяти и скоростью JOIN с помощью настройки grace_hash_join_initial_buckets. В зависимости от объёма данных grace hash может быть как быстрее, так и медленнее, чем алгоритм partial merge, если количество buckets выбрано так, что использование памяти обоими алгоритмами примерно совпадает. Когда использование памяти grace hash join сконфигурировано так, чтобы оно было примерно сопоставимо с использованием памяти full sorting merge, в наших тестовых прогонах full sorting merge всегда был быстрее.
То, какой из трёх алгоритмов, не ограниченных объёмом памяти, окажется самым быстрым, зависит от объёма данных, типов данных и распределения значений по столбцам ключа JOIN. Всегда лучше запустить несколько бенчмарков с реалистичными объёмами и структурой данных, чтобы определить, какой алгоритм будет самым быстрым.
Оптимизация по памяти
Если вы хотите оптимизировать JOIN на минимальное использование памяти, а не на максимально быстрое время выполнения, вы можете использовать следующее дерево решений:
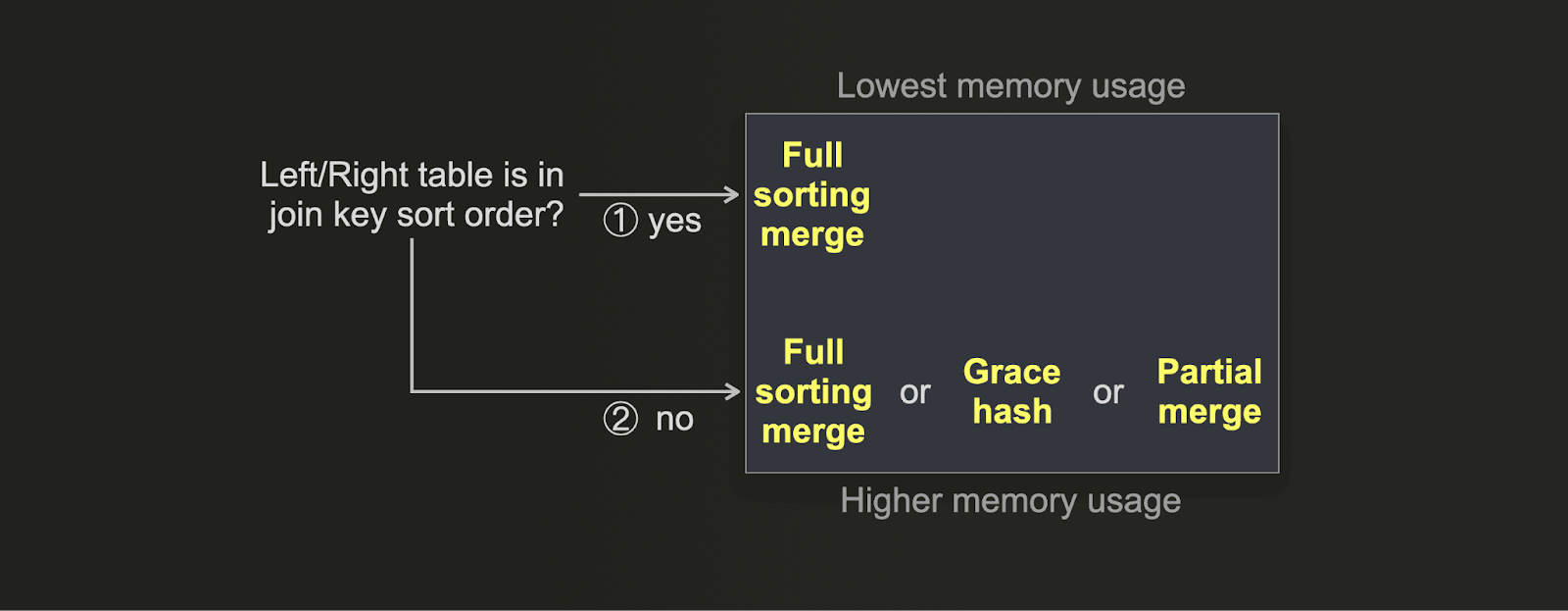
- (1) Если физический порядок строк в вашей таблице совпадает с порядком сортировки по ключу
JOIN, то потребление памяти у full sorting merge join будет минимально возможным. Дополнительным преимуществом является высокая скорость выполненияJOIN, поскольку фаза сортировки отключается. - (2) Grace hash join можно настроить на очень низкое потребление памяти, настроив большое количество бакетов ценой снижения скорости
JOIN. Partial merge join изначально спроектирован так, чтобы использовать малый объем оперативной памяти. Full sorting merge join с включенной внешней сортировкой, как правило, потребляет больше памяти, чем partial merge join (если порядок строк не совпадает с порядком сортировки по ключу), но обеспечивает значительно более высокую скорость выполненияJOIN.
Пользователям, которым требуется больше подробностей по указанному выше материалу, мы рекомендуем следующую серию статей в блоге.
