Введение
ClickHouse обрабатывает запросы чрезвычайно быстро, но как эти запросы
распределяются и выполняются параллельно на нескольких серверах?
В этом руководстве мы сначала рассмотрим, как ClickHouse распределяет запрос
по нескольким шардам с помощью распределённых таблиц, а затем как запрос может
задействовать несколько реплик при выполнении.
Шардированная архитектура
В архитектуре без общей памяти (shared-nothing) кластеры обычно
разбиваются на несколько шардов, при этом каждый шард содержит подмножество
общих данных. Сверху этих шардов располагается распределённая таблица, которая
предоставляет единое представление всех данных целиком.
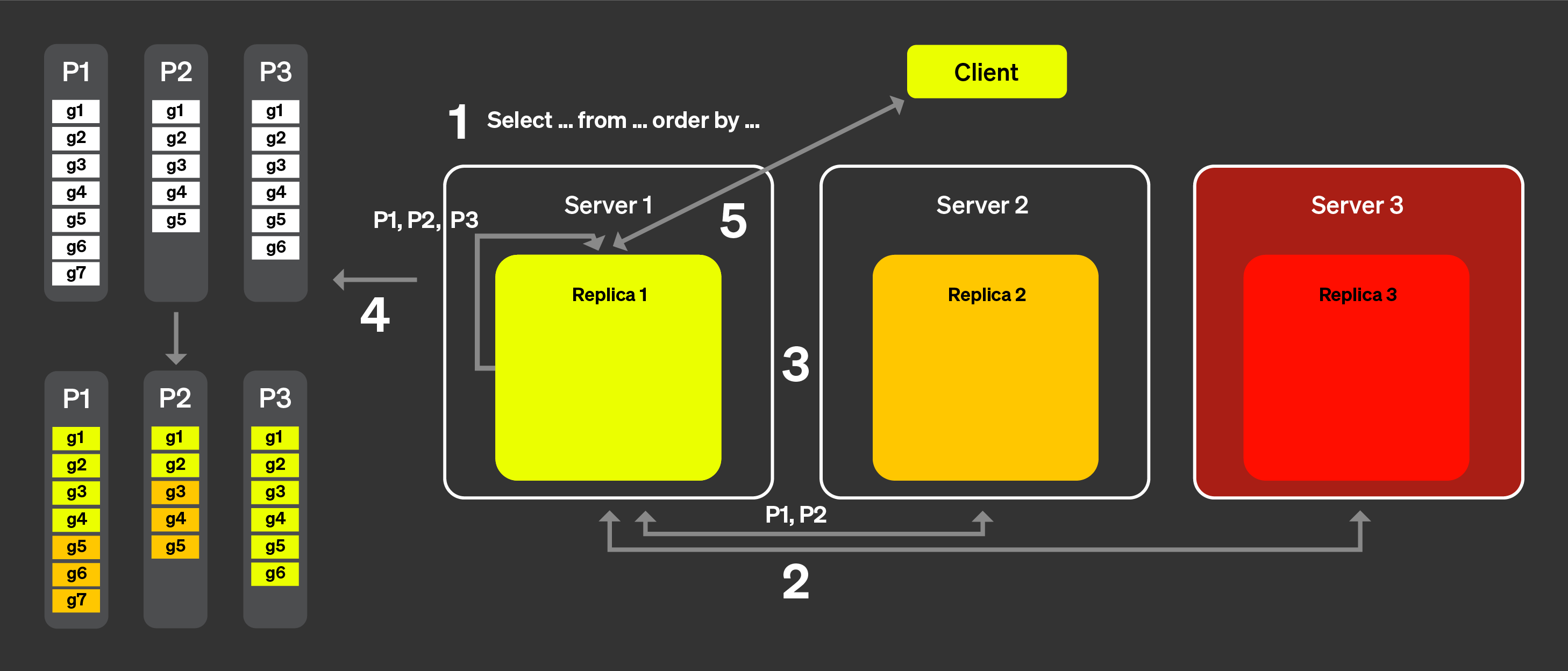
Запросы на чтение могут отправляться к локальной таблице. В этом случае
выполнение запроса произойдёт только на указанном шарде, либо запрос может быть
отправлен к распределённой таблице, и тогда каждый шард выполнит заданный
запрос. Сервер, на котором была выполнена выборка из распределённой таблицы,
агрегирует данные и отправит ответ клиенту:
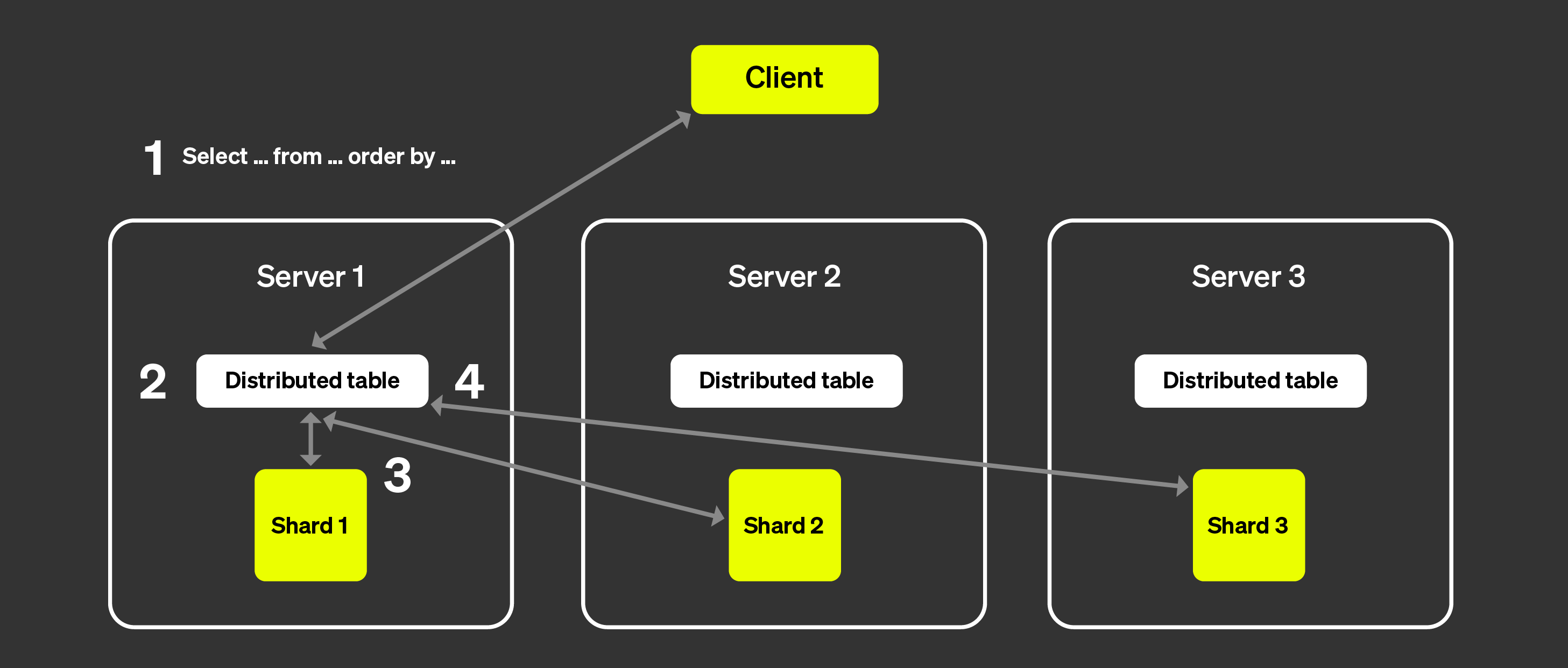
На рисунке выше показано, что происходит, когда клиент отправляет запрос к распределённой таблице:
Запрос SELECT отправляется к распределённой таблице на произвольный узел
(по стратегии round-robin или после маршрутизации балансировщиком нагрузки
на конкретный сервер). Этот узел теперь будет выступать координатором.
Узел определяет, какие шарды должны выполнить запрос,
используя информацию, указанную в распределённой таблице, и отправляет
запрос на каждый шард.
Каждый шард локально читает, фильтрует и агрегирует данные, а затем
отправляет агрегируемое состояние координатору.
Координирующий узел объединяет данные и затем отправляет ответ
обратно клиенту.
Когда мы добавляем реплики, процесс в целом остаётся похожим, с единственным
отличием: только одна реплика из каждого шарда будет выполнять запрос.
Это означает, что можно обрабатывать больше запросов параллельно.
Нешардированная архитектура
ClickHouse Cloud имеет архитектуру, существенно отличающуюся от представленной выше.
(См. раздел "ClickHouse Cloud Architecture"
для получения более подробной информации). Благодаря разделению вычислительных ресурсов и хранилища,
а также практически неограниченному объёму хранилища, необходимость в шардах во многом отпадает.
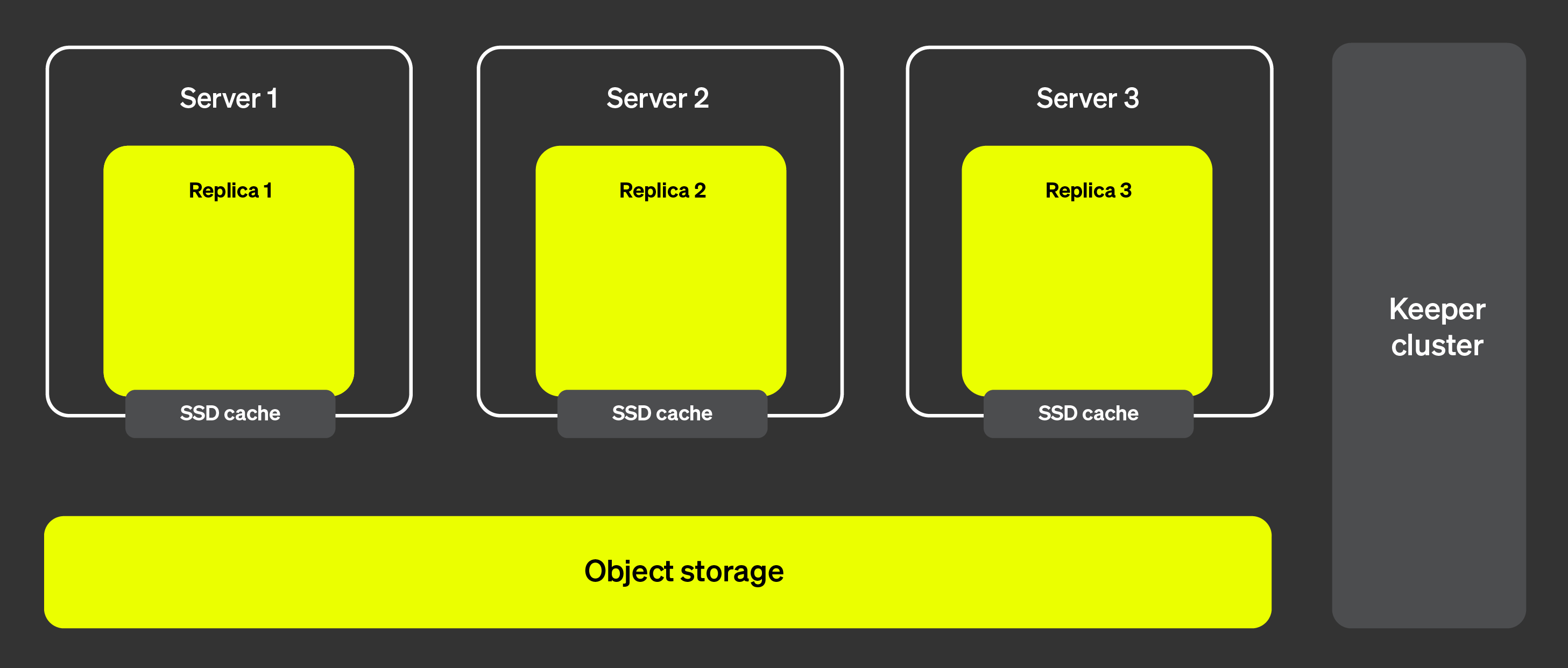
На рисунке ниже показана архитектура ClickHouse Cloud:
Эта архитектура позволяет почти мгновенно добавлять и удалять реплики, обеспечивая высокую
масштабируемость кластера. Кластер ClickHouse Keeper (показан справа) обеспечивает единый
источник истины для метаданных. Реплики могут получать метаданные из кластера ClickHouse Keeper
и таким образом работать с одними и теми же данными. Сами данные хранятся в объектном хранилище,
а SSD-кэш позволяет ускорить выполнение запросов.
Но как теперь распределять выполнение запросов между несколькими серверами?
В шардированной архитектуре это было довольно очевидно, поскольку каждый шард мог выполнять
запрос над подмножеством данных. Как это работает, когда шардирования нет?
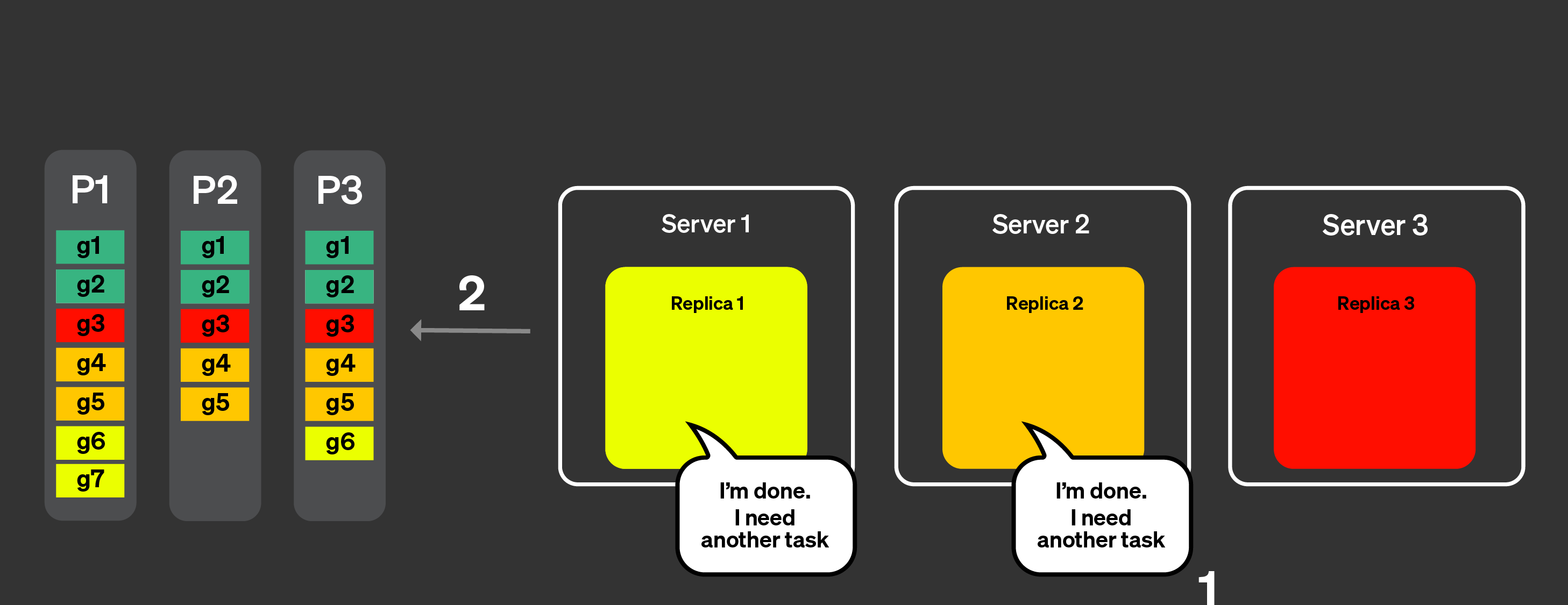
Введение в параллельные реплики
Чтобы распараллелить выполнение запроса на нескольких серверах, сначала нужно
иметь возможность назначить один из серверов координатором. Координатор —
это компонент, который создаёт список задач, подлежащих выполнению, следит за тем, чтобы
они все были выполнены, агрегированы и чтобы результат был возвращён клиенту.
Как и в большинстве распределённых систем, эту роль выполняет узел, который
получает исходный запрос. Нам также нужно определить единицу работы. В шардированной
архитектуре единицей работы является шард, подмножество данных. В случае
параллельных реплик в качестве единицы работы мы будем использовать небольшую
часть таблицы, называемую гранулами.
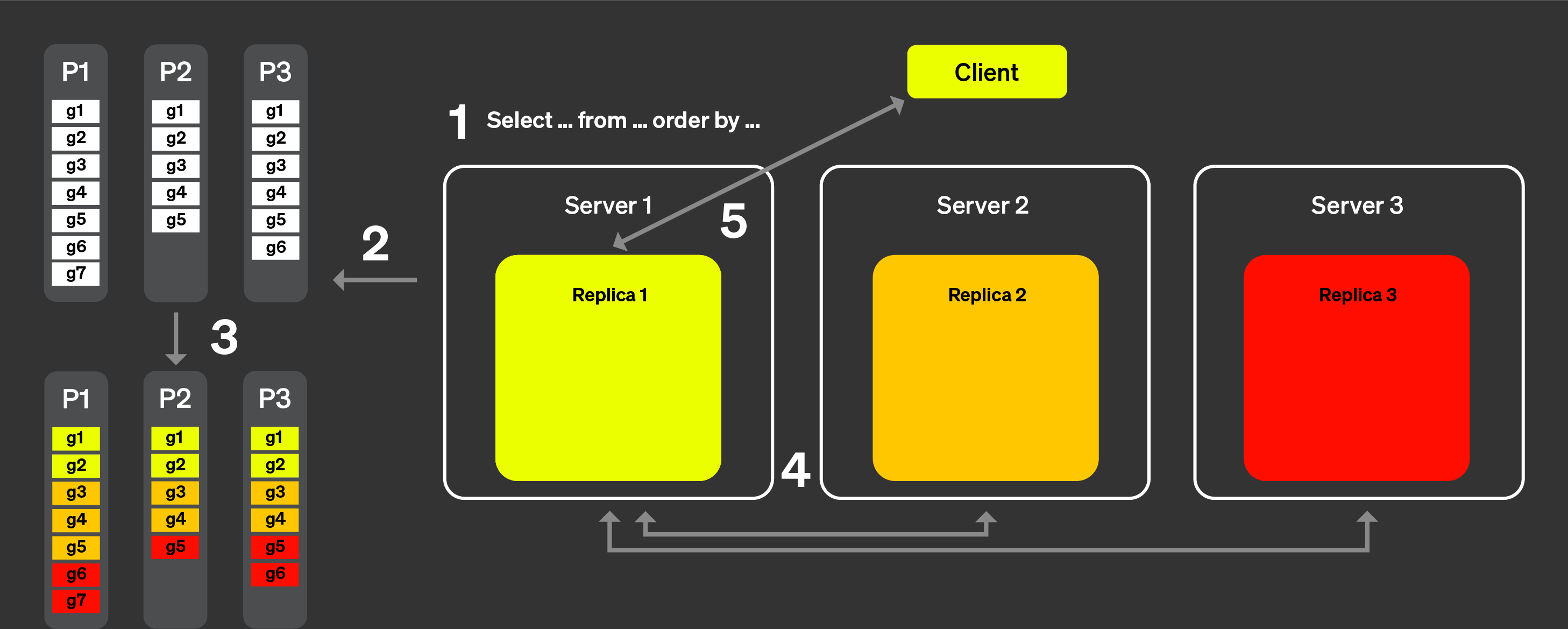
Теперь посмотрим, как это работает на практике, с помощью схемы ниже:
При использовании параллельных реплик:
Запрос от клиента отправляется на один узел после прохождения через
балансировщик нагрузки. Этот узел становится координатором для данного запроса.
Узел анализирует индекс каждой партиции и выбирает подходящие партиции и
гранулы для обработки.
Координатор разбивает нагрузку на набор гранул, который можно
распределить между разными репликами.
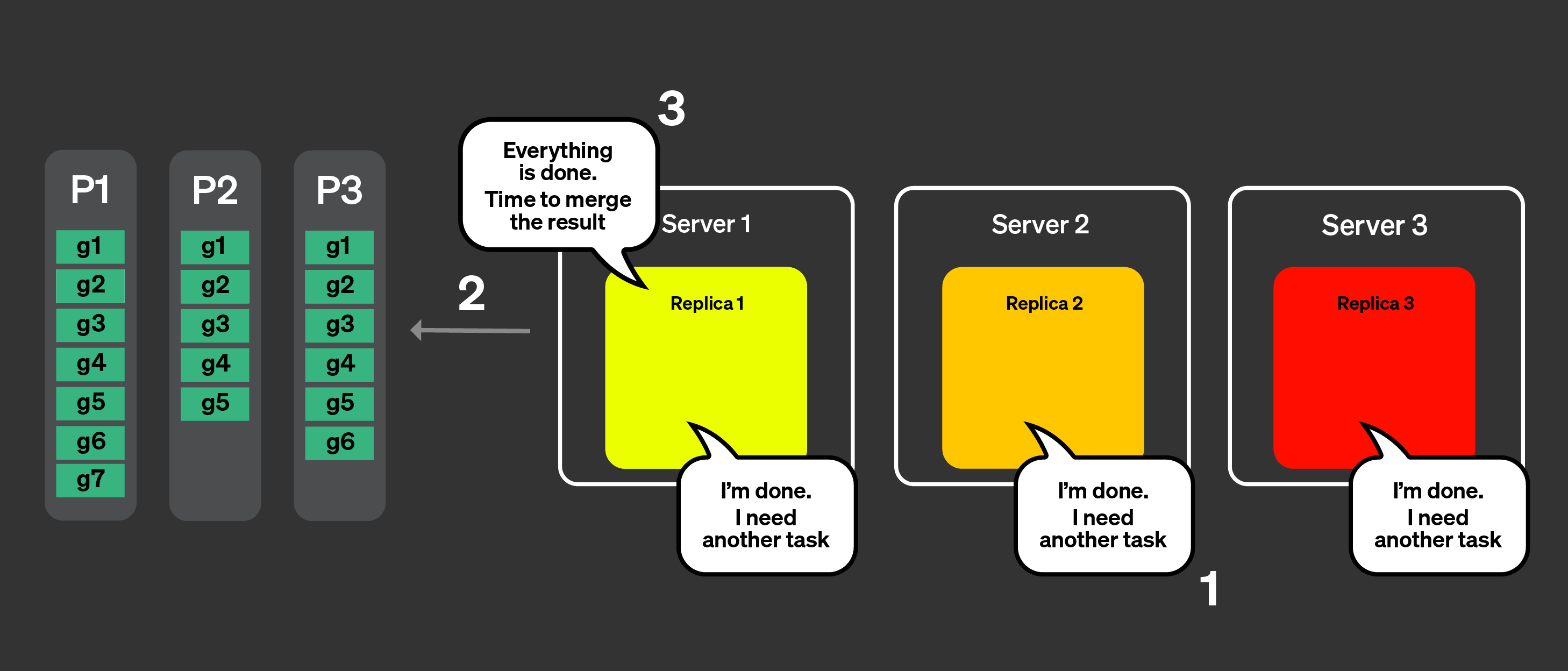
Каждый набор гранул обрабатывается соответствующими репликами, и по
завершении на координатор отправляется состояние, пригодное для слияния.
Наконец, координатор объединяет все результаты от реплик и
возвращает ответ клиенту.
Вышеописанные шаги показывают, как параллельные реплики работают в теории.
Однако на практике существует множество факторов, которые могут помешать
идеальной работе такого механизма:
Некоторые реплики могут быть недоступны.
Репликация в ClickHouse асинхронная, поэтому в какой-то момент времени
на некоторых репликах могут отсутствовать те же самые части.
Нужно как‑то обрабатывать «хвостовые» задержки между репликами.
Кэш файловой системы различается от реплики к реплике в зависимости
от активности на каждой реплике, поэтому случайное назначение
задач может привести к менее оптимальной производительности с точки
зрения локальности кэша.
В следующих разделах мы рассмотрим, как удаётся преодолеть эти факторы.
Объявления
Чтобы решить пункты (1) и (2) из списка выше, мы ввели концепцию
объявления. Рассмотрим, как это работает, на схеме ниже:
Запрос от клиента после прохождения через балансировщик нагрузки
отправляется на один из узлов. Этот узел становится координатором для данного запроса.
Узел-координатор отправляет запрос на получение объявлений от всех
реплик в кластере. У реплик могут быть немного разные представления о
текущем наборе частей (parts) таблицы. Поэтому нам нужно
собрать эту информацию, чтобы избежать неверных решений при
планировании.
Затем узел-координатор использует объявления, чтобы определить набор
гранул, которые можно назначить различным репликам. Здесь, например,
мы видим, что ни одна гранула из part 3 не была назначена
реплике 2, потому что эта реплика не указала эту часть в своем
объявлении. Также обратите внимание, что реплике 3 не были назначены
никакие задачи, потому что она не предоставила объявление.
После того как каждая реплика обработала запрос на своем подмножестве
гранул и объединяемое состояние было отправлено обратно координатору,
координатор объединяет результаты, и ответ отправляется клиенту.
Динамическая координация
Чтобы решить проблему хвостовой задержки, мы добавили динамическую координацию. Это означает,
что все гранулы не отправляются на реплику в одном запросе, а каждая реплика
может запрашивать у координатора новое задание (набор гранул для обработки).
Координатор выдаст реплике набор гранул на основе полученного объявления.
Предположим, что мы находимся на этапе процесса, когда все реплики отправили
объявление со всеми частями.
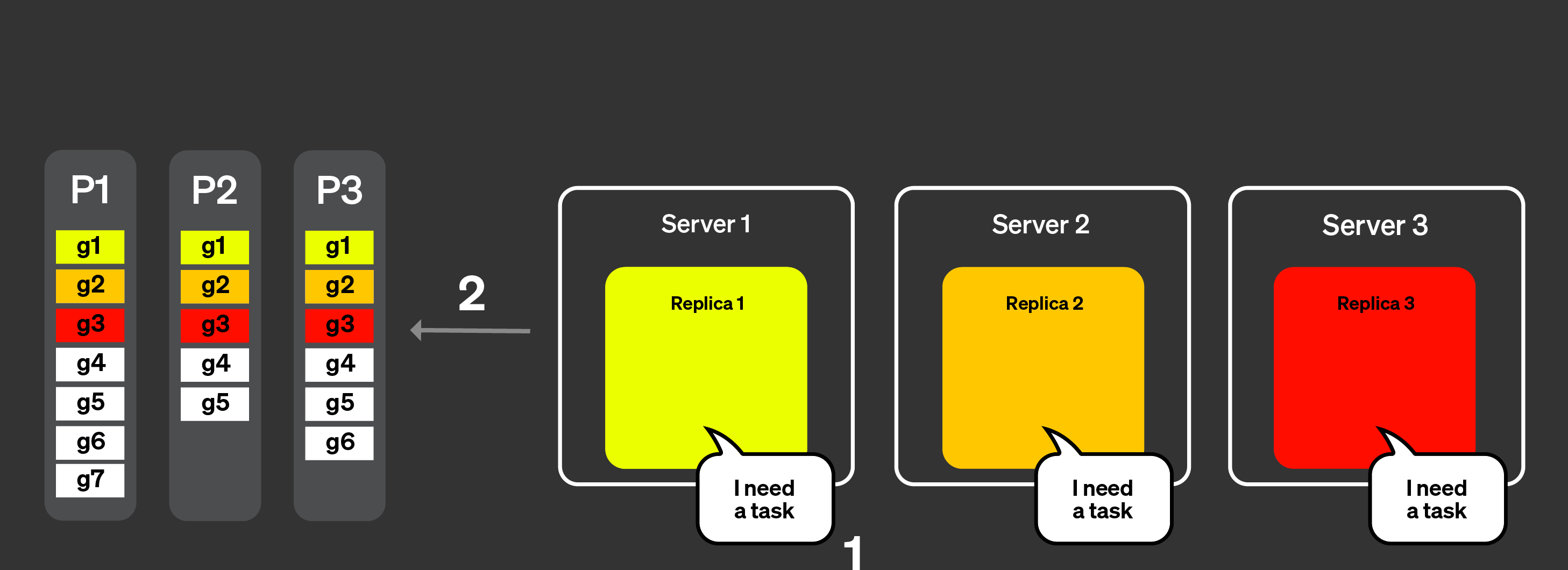
Следующий рисунок показывает, как работает динамическая координация:
Реплики уведомляют узел-координатор, что они готовы обрабатывать
задания, также они могут указать, какой объём работы могут выполнить.
Координатор назначает задания репликам.
Реплики 1 и 2 могут очень быстро завершить свои задания. Они
запрашивают у узла-координатора новое задание.
Координатор назначает новые задания репликам 1 и 2.
Все реплики завершили обработку своих заданий. Они
запрашивают дополнительные задания.
Координатор, используя объявления, проверяет, какие задания
ещё нужно обработать, но оставшихся заданий нет.
Координатор сообщает репликам, что всё обработано.
Теперь он объединит все состояния, подлежащие слиянию, и вернёт ответ на запрос.
Управление локальностью кэша
Последний оставшийся потенциальный проблемный момент — это то, как мы обрабатываем локальность кэша. Если запрос
выполняется несколько раз, как мы можем гарантировать, что одна и та же задача будет направляться на одну и ту же
реплику? В предыдущем примере у нас были назначены следующие задачи:
| Реплика 1 | Реплика 2 | Реплика 3 |
|---|
| Часть 1 | g1, g6, g7 | g2, g4, g5 | g3 |
| Часть 2 | g1 | g2, g4, г5 | g3 |
| Часть 3 | g1, g6 | g2, g4, g5 | g3 |
Чтобы гарантировать, что одни и те же задачи назначаются одним и тем же репликам и могут
использовать кэш, выполняются два шага. Вычисляется хэш части и набора
гранул (задачи). Затем при назначении задач выполняется операция взятия по модулю числа реплик.
На бумаге это выглядит хорошо, но на практике внезапная нагрузка на одну реплику или
деградация сети могут привести к росту хвостовой задержки, если одна и та же реплика
постоянно используется для выполнения определённых задач. Если max_parallel_replicas меньше
количества реплик, то для выполнения запроса случайным образом выбираются реплики.
Перехват задач
Если одна из реплик обрабатывает задачи медленнее других, остальные реплики попытаются
«перехватывать» задачи, которые по хешу формально принадлежат этой реплике, чтобы уменьшить
хвостовую задержку (tail latency).
Ограничения
У этой возможности есть известные ограничения, основные из которых описаны
в этом разделе.
Примечание
Если вы обнаружили проблему, которая не относится к перечисленным ниже
ограничениям и подозреваете, что причиной являются параллельные реплики,
пожалуйста, создайте issue в GitHub с меткой comp-parallel-replicas.
| Ограничение | Описание |
|---|
| Сложные запросы | В настоящее время механизм параллельных реплик достаточно хорошо работает для простых запросов. Дополнительные уровни сложности, такие как CTE, подзапросы, JOIN-операции, неплоские запросы и т. п., могут оказывать негативное влияние на производительность запросов. |
| Небольшие запросы | Если вы выполняете запрос, который не обрабатывает много строк, его выполнение на нескольких репликах может не дать выигрыша по времени выполнения, поскольку сетевые затраты на координацию между репликами могут приводить к дополнительным циклам при выполнении запроса. Вы можете снизить влияние этих факторов, используя настройку parallel_replicas_min_number_of_rows_per_replica. |
| Parallel replicas отключаются при использовании FINAL | |
| Проекции не используются совместно с Parallel replicas | |
| Данные с высокой кардинальностью и сложная агрегация | Агрегация с высокой кардинальностью, которой требуется передавать большой объем данных, может существенно замедлить ваши запросы. |
| Совместимость с новым анализатором | Новый анализатор может существенно замедлить или ускорить выполнение запроса в отдельных сценариях. |
| Setting | Description |
|---|
enable_parallel_replicas | 0: отключено
1: включено
2: принудительное использование параллельных реплик, будет сгенерировано исключение, если они не используются. |
cluster_for_parallel_replicas | Имя кластера, используемого для параллельной репликации; если вы используете ClickHouse Cloud, используйте default. |
max_parallel_replicas | Максимальное количество реплик, используемых для выполнения запроса на нескольких репликах; если указано число, меньшее количества реплик в кластере, узлы будут выбираться случайным образом. Это значение также может быть завышено с учетом горизонтального масштабирования. |
parallel_replicas_min_number_of_rows_per_replica | Позволяет ограничить количество используемых реплик на основе числа строк, которые необходимо обработать. Количество реплик определяется как:
estimated rows to read / min_number_of_rows_per_replica. |
allow_experimental_analyzer | 0: использовать старый анализатор
1: использовать новый анализатор.
Поведение параллельных реплик может изменяться в зависимости от используемого анализатора. |
Диагностика проблем с параллельными репликами
Вы можете проверить, какие настройки используются для каждого запроса, в таблице
system.query_log. Также можно
просмотреть таблицу system.events,
чтобы увидеть все события, произошедшие на сервере, а табличную функцию
clusterAllReplicas использовать для просмотра таблиц на всех репликах
(если вы пользователь облачного сервиса, используйте default).
SELECT
hostname(),
*
FROM clusterAllReplicas('default', system.events)
WHERE event ILIKE '%ParallelReplicas%'
Ответ
┌─hostname()───────────────────────┬─event──────────────────────────────────────────┬─value─┬─description──────────────────────────────────────────────────────────────────────────────────────────┐
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasHandleRequestMicroseconds │ 438 │ Время обработки запросов меток от реплик │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasHandleAnnouncementMicroseconds │ 558 │ Время обработки объявлений реплик │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasReadUnassignedMarks │ 240 │ Суммарное количество запланированных неназначенных меток по всем репликам │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasReadAssignedForStealingMarks │ 4 │ Суммарное количество запланированных меток, назначенных для перехвата по консистентному хешу, по всем репликам │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasStealingByHashMicroseconds │ 5 │ Время сбора сегментов, предназначенных для перехвата по хешу │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasProcessingPartsMicroseconds │ 5 │ Время обработки частей данных │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasStealingLeftoversMicroseconds │ 3 │ Время сбора осиротевших сегментов │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasUsedCount │ 2 │ Количество реплик, использованных для выполнения запроса с параллельными репликами на основе задач │
│ c-crimson-vd-86-server-rdhnsx3-0 │ ParallelReplicasAvailableCount │ 6 │ Количество реплик, доступных для выполнения запроса с параллельными репликами на основе задач │
└──────────────────────────────────┴────────────────────────────────────────────────┴───────┴──────────────────────────────────────────────────────────────────────────────────────────────────────┘
┌─hostname()───────────────────────┬─event──────────────────────────────────────────┬─value─┬─description──────────────────────────────────────────────────────────────────────────────────────────┐
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasHandleRequestMicroseconds │ 698 │ Время обработки запросов меток от реплик │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasHandleAnnouncementMicroseconds │ 644 │ Время обработки объявлений реплик │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasReadUnassignedMarks │ 190 │ Суммарное количество запланированных неназначенных меток по всем репликам │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasReadAssignedForStealingMarks │ 54 │ Суммарное количество запланированных меток, назначенных для перехвата по консистентному хешу, по всем репликам │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasStealingByHashMicroseconds │ 8 │ Время сбора сегментов, предназначенных для перехвата по хешу │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasProcessingPartsMicroseconds │ 4 │ Время обработки частей данных │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasStealingLeftoversMicroseconds │ 2 │ Время сбора осиротевших сегментов │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasUsedCount │ 2 │ Количество реплик, использованных для выполнения запроса с параллельными репликами на основе задач │
│ c-crimson-vd-86-server-e9kp5f0-0 │ ParallelReplicasAvailableCount │ 6 │ Количество реплик, доступных для выполнения запроса с параллельными репликами на основе задач │
└──────────────────────────────────┴────────────────────────────────────────────────┴───────┴──────────────────────────────────────────────────────────────────────────────────────────────────────┘
┌─hostname()───────────────────────┬─event──────────────────────────────────────────┬─value─┬─description──────────────────────────────────────────────────────────────────────────────────────────┐
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasHandleRequestMicroseconds │ 620 │ Время обработки запросов меток от реплик │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasHandleAnnouncementMicroseconds │ 656 │ Время обработки объявлений реплик │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasReadUnassignedMarks │ 1 │ Суммарное количество запланированных неназначенных меток по всем репликам │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasReadAssignedForStealingMarks │ 1 │ Суммарное количество запланированных меток, назначенных для перехвата по консистентному хешу, по всем репликам │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasStealingByHashMicroseconds │ 4 │ Время сбора сегментов, предназначенных для перехвата по хешу │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasProcessingPartsMicroseconds │ 3 │ Время обработки частей данных │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasStealingLeftoversMicroseconds │ 1 │ Время сбора осиротевших сегментов │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasUsedCount │ 2 │ Количество реплик, использованных для выполнения запроса с параллельными репликами на основе задач │
│ c-crimson-vd-86-server-ybtm18n-0 │ ParallelReplicasAvailableCount │ 12 │ Количество реплик, доступных для выполнения запроса с параллельными репликами на основе задач │
└──────────────────────────────────┴────────────────────────────────────────────────┴───────┴──────────────────────────────────────────────────────────────────────────────────────────────────────┘
┌─hostname()───────────────────────┬─event──────────────────────────────────────────┬─value─┬─description──────────────────────────────────────────────────────────────────────────────────────────┐
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasHandleRequestMicroseconds │ 696 │ Время обработки запросов меток от реплик │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasHandleAnnouncementMicroseconds │ 717 │ Время обработки объявлений реплик │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasReadUnassignedMarks │ 2 │ Суммарное количество запланированных неназначенных меток по всем репликам │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasReadAssignedForStealingMarks │ 2 │ Суммарное количество запланированных меток, назначенных для перехвата по консистентному хешу, по всем репликам │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasStealingByHashMicroseconds │ 10 │ Время сбора сегментов, предназначенных для перехвата по хешу │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasProcessingPartsMicroseconds │ 6 │ Время обработки частей данных │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasStealingLeftoversMicroseconds │ 2 │ Время сбора осиротевших сегментов │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasUsedCount │ 2 │ Количество реплик, использованных для выполнения запроса с параллельными репликами на основе задач │
│ c-crimson-vd-86-server-16j1ncj-0 │ ParallelReplicasAvailableCount │ 12 │ Количество реплик, доступных для выполнения запроса с параллельными репликами на основе задач │
└──────────────────────────────────┴────────────────────────────────────────────────┴───────┴──────────────────────────────────────────────────────────────────────────────────────────────────────┘
Таблица system.text_log также
содержит информацию о выполнении запросов при использовании параллельных реплик:
SELECT message
FROM clusterAllReplicas('default', system.text_log)
WHERE query_id = 'ad40c712-d25d-45c4-b1a1-a28ba8d4019c'
ORDER BY event_time_microseconds ASC
Ответ
┌─message────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ (from 54.218.178.249:59198) SELECT * FROM session_events WHERE type='type2' LIMIT 10 SETTINGS allow_experimental_parallel_reading_from_replicas=2; (stage: Complete) │
│ Query SELECT __table1.clientId AS clientId, __table1.sessionId AS sessionId, __table1.pageId AS pageId, __table1.timestamp AS timestamp, __table1.type AS type FROM default.session_events AS __table1 WHERE __table1.type = 'type2' LIMIT _CAST(10, 'UInt64') SETTINGS allow_experimental_parallel_reading_from_replicas = 2 to stage Complete │
│ Доступ предоставлен: SELECT(clientId, sessionId, pageId, timestamp, type) ON default.session_events │
│ Query SELECT __table1.clientId AS clientId, __table1.sessionId AS sessionId, __table1.pageId AS pageId, __table1.timestamp AS timestamp, __table1.type AS type FROM default.session_events AS __table1 WHERE __table1.type = 'type2' LIMIT _CAST(10, 'UInt64') to stage WithMergeableState only analyze │
│ Доступ предоставлен: SELECT(clientId, sessionId, pageId, timestamp, type) ON default.session_events │
│ Query SELECT __table1.clientId AS clientId, __table1.sessionId AS sessionId, __table1.pageId AS pageId, __table1.timestamp AS timestamp, __table1.type AS type FROM default.session_events AS __table1 WHERE __table1.type = 'type2' LIMIT _CAST(10, 'UInt64') from stage FetchColumns to stage WithMergeableState only analyze │
│ Query SELECT __table1.clientId AS clientId, __table1.sessionId AS sessionId, __table1.pageId AS pageId, __table1.timestamp AS timestamp, __table1.type AS type FROM default.session_events AS __table1 WHERE __table1.type = 'type2' LIMIT _CAST(10, 'UInt64') SETTINGS allow_experimental_parallel_reading_from_replicas = 2 to stage WithMergeableState only analyze │
│ Доступ предоставлен: SELECT(clientId, sessionId, pageId, timestamp, type) ON default.session_events │
│ Query SELECT __table1.clientId AS clientId, __table1.sessionId AS sessionId, __table1.pageId AS pageId, __table1.timestamp AS timestamp, __table1.type AS type FROM default.session_events AS __table1 WHERE __table1.type = 'type2' LIMIT _CAST(10, 'UInt64') SETTINGS allow_experimental_parallel_reading_from_replicas = 2 from stage FetchColumns to stage WithMergeableState only analyze │
│ Query SELECT __table1.clientId AS clientId, __table1.sessionId AS sessionId, __table1.pageId AS pageId, __table1.timestamp AS timestamp, __table1.type AS type FROM default.session_events AS __table1 WHERE __table1.type = 'type2' LIMIT _CAST(10, 'UInt64') SETTINGS allow_experimental_parallel_reading_from_replicas = 2 from stage WithMergeableState to stage Complete │
│ Запрошенное количество реплик (100) превышает фактическое количество доступных в кластере (6). Для выполнения запроса будет использовано фактическое значение. │
│ Начальный запрос от реплики 4: 2 части: [part all_0_2_1 with ranges [(0, 182)], part all_3_3_0 with ranges [(0, 62)]]----------
Получено от реплики 4
│
│ Состояние чтения полностью инициализировано: part all_0_2_1 with ranges [(0, 182)] in replicas [4]; part all_3_3_0 with ranges [(0, 62)] in replicas [4] │
│ Отправлено начальных запросов: 1 Количество реплик: 6 │
│ Начальный запрос от реплики 2: 2 части: [part all_0_2_1 with ranges [(0, 182)], part all_3_3_0 with ranges [(0, 62)]]----------
Получено от реплики 2
│
│ Отправлено начальных запросов: 2 Количество реплик: 6 │
│ Обработка запроса от реплики 4, минимальный размер меток: 240 │
│ Отправка ответа реплике 4 с 1 частью: [part all_0_2_1 with ranges [(128, 182)]]. Finish: false; mine_marks=0, stolen_by_hash=54, stolen_rest=0 │
│ Начальный запрос от реплики 1: 2 части: [part all_0_2_1 with ranges [(0, 182)], part all_3_3_0 with ranges [(0, 62)]]----------
Получено от реплики 1
│
│ Отправлено начальных запросов: 3 Количество реплик: 6 │
│ Обработка запроса от реплики 4, минимальный размер меток: 240 │
│ Отправка ответа реплике 4 с 2 частями: [part all_0_2_1 with ranges [(0, 128)], part all_3_3_0 with ranges [(0, 62)]]. Finish: false; mine_marks=0, stolen_by_hash=0, stolen_rest=190 │
│ Начальный запрос от реплики 0: 2 части: [part all_0_2_1 with ranges [(0, 182)], part all_3_3_0 with ranges [(0, 62)]]----------
Получено от реплики 0
│
│ Отправлено начальных запросов: 4 Количество реплик: 6 │
│ Начальный запрос от реплики 5: 2 части: [part all_0_2_1 with ranges [(0, 182)], part all_3_3_0 with ranges [(0, 62)]]----------
Получено от реплики 5
│
│ Отправлено начальных запросов: 5 Количество реплик: 6 │
│ Обработка запроса от реплики 2, минимальный размер меток: 240 │
│ Отправка ответа реплике 2 с 0 частями: []. Finish: true; mine_marks=0, stolen_by_hash=0, stolen_rest=0 │
│ Начальный запрос от реплики 3: 2 части: [part all_0_2_1 with ranges [(0, 182)], part all_3_3_0 with ranges [(0, 62)]]----------
Получено от реплики 3
│
│ Отправлено начальных запросов: 6 Количество реплик: 6 │
│ Всего строк для чтения: 2000000 │
│ Обработка запроса от реплики 5, минимальный размер меток: 240 │
│ Отправка ответа реплике 5 с 0 частями: []. Finish: true; mine_marks=0, stolen_by_hash=0, stolen_rest=0 │
│ Обработка запроса от реплики 0, минимальный размер меток: 240 │
│ Отправка ответа реплике 0 с 0 частями: []. Finish: true; mine_marks=0, stolen_by_hash=0, stolen_rest=0 │
│ Обработка запроса от реплики 1, минимальный размер меток: 240 │
│ Отправка ответа реплике 1 с 0 частями: []. Finish: true; mine_marks=0, stolen_by_hash=0, stolen_rest=0 │
│ Обработка запроса от реплики 3, минимальный размер меток: 240 │
│ Отправка ответа реплике 3 с 0 частями: []. Finish: true; mine_marks=0, stolen_by_hash=0, stolen_rest=0 │
│ (c-crimson-vd-86-server-rdhnsx3-0.c-crimson-vd-86-server-headless.ns-crimson-vd-86.svc.cluster.local:9000) Отмена запроса: прочитано достаточно данных │
│ Прочитано 81920 строк, 5.16 МиБ за 0.013166 сек., 6222087.194288318 строк/сек., 391.63 МиБ/сек. │
│ Координация завершена: Статистика: replica 0 - {requests: 2 marks: 0 assigned_to_me: 0 stolen_by_hash: 0 stolen_unassigned: 0}; replica 1 - {requests: 2 marks: 0 assigned_to_me: 0 stolen_by_hash: 0 stolen_unassigned: 0}; replica 2 - {requests: 2 marks: 0 assigned_to_me: 0 stolen_by_hash: 0 stolen_unassigned: 0}; replica 3 - {requests: 2 marks: 0 assigned_to_me: 0 stolen_by_hash: 0 stolen_unassigned: 0}; replica 4 - {requests: 3 marks: 244 assigned_to_me: 0 stolen_by_hash: 54 stolen_unassigned: 190}; replica 5 - {requests: 2 marks: 0 assigned_to_me: 0 stolen_by_hash: 0 stolen_unassigned: 0} │
│ Пиковое использование памяти (для запроса): 1.81 МиБ. │
│ Обработано за 0.024095586 сек. │
└────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
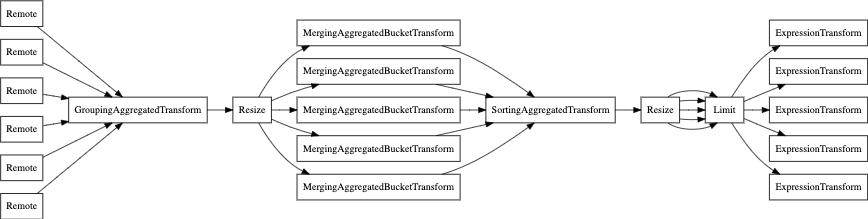
Наконец, вы можете использовать и EXPLAIN PIPELINE. Он показывает, как ClickHouse
будет выполнять запрос и какие ресурсы будут задействованы при
его выполнении. Возьмем, к примеру, следующий запрос:
SELECT count(), uniq(pageId) , min(timestamp), max(timestamp)
FROM session_events
WHERE type='type3'
GROUP BY toYear(timestamp) LIMIT 10
Рассмотрим конвейер выполнения запроса без параллельных реплик:
EXPLAIN PIPELINE graph = 1, compact = 0
SELECT count(), uniq(pageId) , min(timestamp), max(timestamp)
FROM session_events
WHERE type='type3'
GROUP BY toYear(timestamp)
LIMIT 10
SETTINGS allow_experimental_parallel_reading_from_replicas=0
FORMAT TSV;
Теперь с parallel_replica:
EXPLAIN PIPELINE graph = 1, compact = 0
SELECT count(), uniq(pageId) , min(timestamp), max(timestamp)
FROM session_events
WHERE type='type3'
GROUP BY toYear(timestamp)
LIMIT 10
SETTINGS allow_experimental_parallel_reading_from_replicas=2
FORMAT TSV;